
AI workloads have quickly moved from experimental batch jobs to business-critical systems. The infrastructure supporting them has had to mature just as fast. Distributed training on Kubernetes, large language model serving under tight latency requirements, and multi-tenant accelerator clusters shared across engineering teams all present orchestration challenges that general-purpose systems were not built to handle.
By 2026, Kubernetes AI infrastructure has become the de facto orchestration layer across many engineering organizations. GPU scheduling on Kubernetes, distributed training coordination with KubeRay, multi-tenancy controls, DRA-based resource allocation, and LLM inference serving are now supported through a mature ecosystem of operators and schedulers. The reasons for this adoption are less about any single feature and more about a combination of portability, ecosystem depth, and a control plane flexible enough to accommodate hardware requirements far beyond its original scope. This article covers the reference architecture of a production Kubernetes AI stack, the scheduling constraints specific to GPU workloads, multi-tenancy design, common failure patterns, and a realistic comparison with managed ML platforms.
Why Kubernetes Became the Standard for AI Workloads
The shift toward Kubernetes-native AI infrastructure was driven by practical operational requirements that existing tools handled poorly.
ML pipelines need to produce consistent behavior across a range of environments: a local workstation, an on-premises GPU server, a cloud spot instance pool, or a specialized bare-metal provider. Packaging CUDA runtimes, model weights, Python environments, and configuration together into OCI containers makes environment parity achievable in a way that earlier approaches, such as managed conda environments or custom provisioning scripts, could not reliably deliver at scale.
The CNCF ecosystem removed the need to build foundational operational tooling from scratch. Certificate management, access control, metrics collection, storage provisioning, and GitOps-based deployment workflows all have production-tested Kubernetes-native implementations. For platform teams managing heterogeneous AI workloads across regions or cloud providers, this ecosystem maturity reduces the surface area of custom systems that need to be built and maintained.
Probably the biggest reason Kubernetes won, though, is extensibility at the API layer. Custom Resource Definitions and operators let the community extend the scheduler and control plane to handle GPU lifecycle events, distributed runtime state, and topology-aware placement without modifying upstream code. The GPU Operator, KubeRay, Kueue, Volcano, and the Dynamic Resource Allocation framework all exist because that extension model made it practical to build specialized AI infrastructure tooling on a common foundation.
Kubernetes AI Infrastructure Reference Architecture: GPU Clusters in 2026
A production Kubernetes AI stack integrates several distinct components, each handling a specific concern. Built on the extensible control plane described above, the challenge is not selecting individual tools but configuring them to work as a coherent system rather than a collection of independent services.
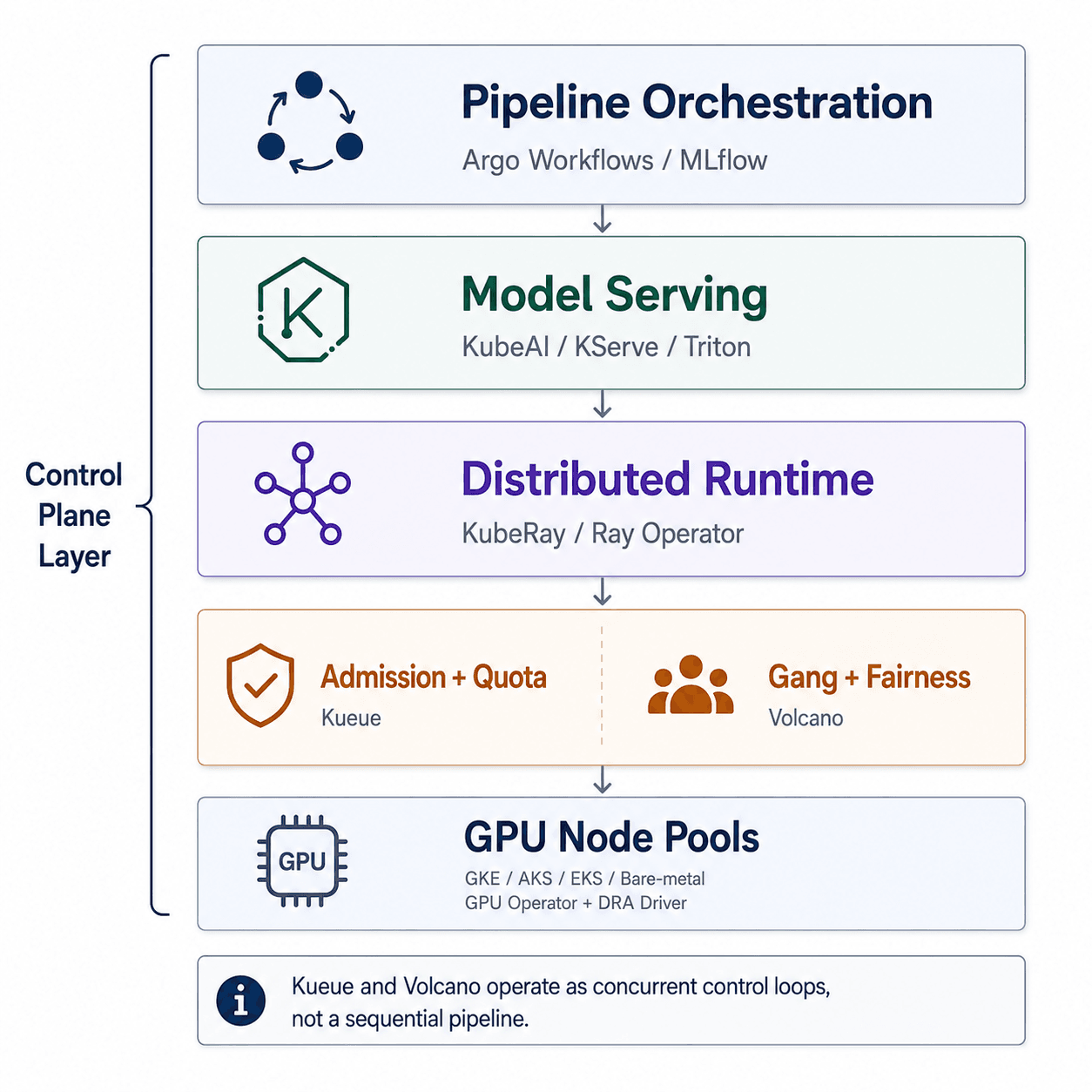
FIgure 1: Modern AI infrastructure on Kubernetes combines orchestration, distributed runtimes, scheduling, and GPU management into a unified control plane.
GPU Node Pools provide the physical or virtualized accelerator capacity. Whether sourced from bare-metal providers or managed cloud services like GKE, AKS, or EKS, GPU nodes are exposed to the scheduler through node taints, node selectors, and provisioning APIs such as GKE's ProvisioningRequest for dynamic scale-out.
Distributed Runtime (KubeRay / Ray Operator v1.6.1+) coordinates the head and worker topology for distributed training and fine-tuning. The operator exposes RayCluster, RayJob, and RayService custom resources that abstract the complexity of managing distributed Python processes across nodes.
Batch Scheduling (Kueue / Volcano) covers two distinct concerns. Kueue controls admission and enforces quota, deciding which jobs enter the scheduling pool. Volcano coordinates gang scheduling and DRF-style fairness at the scheduler level. In many production environments, both run together as layered control systems rather than a strict sequential pipeline.
Model Serving (KServe / Triton / KubeAI v0.23.2) controls inference endpoint management. KubeAI has seen broad adoption for LLM serving due to its minimal dependency footprint and built-in prefix-aware load balancing. KServe and Triton remain widely used for multi-framework serving environments.
Pipeline Orchestration (Argo Workflows / MLflow) coordinates DAG-based workflows for data preparation, training triggers, and evaluation. Pipelines run on CPU or GPU workers depending on the stage, with shared persistent volumes coordinating data between steps.
When a developer submits a RayJob manifest, Kueue handles quota and admission while Volcano manages gang scheduling. Their interaction happens through queued state transitions rather than a strict handoff. Kueue holds the job in suspension if quota is exhausted while infrastructure scales in the background. Volcano monitors the scheduling pool as a continuous observer of cluster state, re-evaluating placement feasibility as capacity changes rather than waiting for a single trigger event. Workers are committed to nodes only when the complete set can be satisfied simultaneously. Version drift between the Ray Operator and Kueue's admission webhook is a common source of jobs that appear queued but never schedule, making component version compatibility a first-class operational concern.
Kubernetes GPU Scheduling for Distributed AI Training
Distributed training imposes scheduling constraints with no equivalent in stateless application workloads. Understanding why default Kubernetes scheduling falls short for GPU workloads, and how the ecosystem addresses these gaps, is foundational to running production training infrastructure.
The default Kubernetes scheduler evaluates and places pods independently. For a distributed training job, this creates a real problem: if seven of eight requested worker pods schedule while the eighth stays pending, the active workers hold GPU allocations at near-zero utilization waiting for the missing peer. Those resources stay blocked for other workloads, degrading overall cluster efficiency every time partial placements happen.
Volcano's PodGroup abstraction addresses this with gang scheduling. It treats the entire worker group as an atomic scheduling unit. Rather than evaluating each worker pod in isolation, Volcano operates as an event-driven placement system: it monitors cluster capacity as a whole, reacts to resource state changes, and continuously re-evaluates whether the full worker set can be satisfied before committing any of them to nodes. If capacity is unavailable, the job stays queued entirely. This all-or-nothing behavior is a prerequisite for reliable distributed training on Kubernetes, not an optional optimization.
Over time, clusters build up fragmentation as jobs of varying sizes complete and leave uneven GPU counts across nodes. A cluster with 40 total GPUs available may still be unable to satisfy a request for 8 GPUs on a single node, which matters for topology-sensitive distributed training Kubernetes workloads relying on NVLink bandwidth within a node boundary. Volcano includes topology-aware scheduling policies that consider NVLink and PCIe topology when placing workers, though these require accurate topology information in node labels and careful policy configuration.
In some enterprise environments, Apache YuniKorn is used in place of Volcano for the scheduler layer, offering a similar fair-share model with a different gang scheduling implementation and web-based queue visibility.
Kueue coordinates the organizational queue layer, and its relationship with Volcano is better understood as concurrent feedback loops than a sequential chain. Kueue's ClusterQueue and LocalQueue resources model team-level resource allocation, holding jobs that exceed quota before they reach the scheduling pool. Changes in queue depth feed back into Volcano's view of schedulable demand. As Kueue releases jobs, Volcano re-evaluates placement feasibility against current cluster state rather than processing each job as a discrete event. Submitting jobs directly to Volcano without going through Kueue bypasses quota enforcement entirely, which in shared clusters leads to the contention issues that multi-tenancy controls exist to prevent.
Multi-Tenancy in GPU Clusters
Shared GPU infrastructure is expensive enough that resource isolation between teams is an operational requirement, not a governance preference. An unthrottled research workload can easily consume enough capacity to degrade latency on production inference endpoints serving real traffic.
Namespaces and RBAC form the logical partitioning boundary. Each team operates in a dedicated namespace with role bindings controlling resource creation and modification. This creates a clean surface for quota enforcement and access auditing.
ResourceQuotas set hard GPU limits per namespace. A research namespace might be allocated a fixed number of physical GPUs or MIG slices, while development namespaces get smaller allocations. Quotas apply to both physical devices and time-sliced virtual accelerators where applicable.
PriorityClasses control preemption behavior. Production inference endpoints are assigned elevated priority classes with preemption policies set to PreemptLowerPriority. When a serving deployment needs additional capacity due to traffic growth, the scheduler evicts lower-priority training pods. Validating preemption behavior under realistic conditions before teams depend on it is worth the time; interactions with PodDisruptionBudgets and pod termination grace periods can produce unexpected outcomes.
Node taints protect GPU nodes from general CPU workloads. Tainting nodes with nvidia.com/gpu=present:NoSchedule prevents logging collectors, web proxies, and other CPU-bound workloads from occupying accelerator capacity.
The real challenge is balancing fairness with high utilization. Kueue's borrowing model lets jobs use unused quota from sibling queues up to a configurable ceiling, with borrowed capacity reclaimed when the original holder submits new work. Quotas set too conservatively leave hardware idle. Quotas set too permissively let workloads grow into borrowed capacity and then fail when it is reclaimed mid-run. Monitoring queue depth and per-namespace GPU utilization provides the signal needed to tune these allocations over time.
Common Production Failures: Cause, Impact, and Mitigation
Production GPU clusters create failure modes that rarely show up in standard application infrastructure. Here are the failure patterns seen most often in large clusters:
Storage I/O Bottlenecks:
Under standard POSIX storage paths, training data travels from remote storage over the network, through the CPU and system memory, then across the PCIe bus to GPU memory. This path can create CPU memory bandwidth constraints that limit data delivery rates, leaving GPU compute units in an I/O-bound idle state. GPUDirect Storage (GDS) reduces CPU involvement in supported configurations, enabling more direct memory access between NVMe storage and GPU memory. Enabling GDS requires configuring Mellanox OFED drivers and activating it in the GPU Operator's ClusterPolicy. Standard Python file reads do not use this path; applications need to explicitly invoke NVIDIA's cuFile API or libraries such as kvikio where supported.
Node Preemption During Training:
Teams using spot or preemptible instances accept the risk of sudden node termination. Jobs without checkpointing lose all progress since the last save. Asynchronous checkpointing to durable storage using GCSFuse or AWS FSx for Lustre reduces the blast radius. KubeRay integrates with these backends to halt worker pools on preemption, persist state, and restore from the last checkpoint when new hardware is provisioned. Checkpoint frequency should be calibrated to the expected preemption rate for the instance type in use.
RoCEv2 Network Saturation:
Synchronous gradient exchange during distributed training requires the network fabric to handle traffic bursts without drops. Reliable RoCEv2 operation in AI training environments commonly requires both Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) on the network switches. PFC prevents drops by pausing upstream senders when ingress buffers fill. ECN signals senders to reduce injection rates before buffers reach capacity, helping prevent the head-of-line blocking cascades that PFC alone can create. Running one without the other tends to introduce different classes of instability.
Silent GPU Hardware Failures:
Hardware faults such as XID 31 memory errors can leave the host OS and Kubernetes node reporting as healthy while the GPU produces incorrect results. Standard liveness and readiness probes keep reporting containers as running, so failures may not surface until job outputs are audited. Node Problem Detector (NPD) deployed as a DaemonSet monitors driver logs for critical error events and automatically taints affected nodes with nvidia.com/gpu=unhealthy:NoSchedule, triggering a workload drain to healthy nodes. The NVIDIA DCGM Exporter provides continuous visibility into accelerator-level metrics including compute utilization, memory usage, and error counters that standard Kubernetes monitoring tools do not expose.
Kubernetes vs. Managed ML Platforms
Managed platforms such as AWS SageMaker, GCP Vertex AI, and Azure Machine Learning address a real operational gap: they let teams run training and inference workloads without building platform engineering infrastructure. The trade-offs become more relevant as workload complexity and scale increase.
| Dimension | Kubernetes-Native Stack | AWS SageMaker | GCP Vertex AI | Azure Machine Learning |
| Ops Complexity | High; platform team owns drivers, networking, and upgrades | Low to medium; AWS decides the infrastructure layer | Low; strong managed experience with AutoML tooling | Low; Azure-native integration with managed training clusters |
| Control and Customization | Full control over scheduling, batching, quantization, and custom kernel configurations | Limited to approved runtimes and SageMaker APIs | Standard managed containers; limited deep engine customization | Moderate; VM-level configuration with some constraints |
| Portability | Runs on any cloud or bare-metal environment | Tightly coupled to AWS APIs, IAM, and S3 | Closely integrated with GCS, BigQuery, and GCP networking | Deep integration with Microsoft 365 and Entra ID |
| Team Ownership | High; full stack owned by platform team | Low to medium; shared responsibility with AWS | Low; managed layer handled by Google | Low; managed layer handled by Microsoft |
Managed platforms work well for teams in early stages, working with a limited number of production models, or without a dedicated platform engineering function. The operational burden of self-hosted Kubernetes AI infrastructure is real.
The shift toward Kubernetes-native infrastructure in many organizations happens when customization requirements outgrow managed platform constraints, or when workloads need to span multiple cloud providers in ways that platform-specific APIs cannot cleanly accommodate. Neither approach is universally right; the decision depends on team capacity, workload complexity, and how much runtime control the use case actually needs.
Kubernetes AI Infrastructure Trends in 2026
Several architectural developments in 2026 have moved Kubernetes closer to the requirements of production-scale AI systems, reducing friction that previously required custom operators or workarounds built on top of the underlying control plane model.
Dynamic Resource Allocation (DRA) graduated to General Availability in Kubernetes 1.34 and Red Hat OpenShift 4.21. It replaces the legacy Device Plugin framework, which could only express GPU requests as integer counts, with a structured system for declaring hardware requirements with richer attributes. Under DRA, the NVIDIA driver publishes device information via ResourceSlice custom resources, and workloads request configurations via ResourceClaim or ResourceClaimTemplate evaluated natively by the scheduler using Common Expression Language (CEL). This helps reduce scheduling inflexibility that previously required workarounds in many configurations, supporting attribute-based filtering, prioritized fallback allocations, and intra-pod GPU sharing in supported setups. GPU Operator v26.x has further matured DRA support, with more stable ResourceSlice lifecycle management and improved CDI integration compared to earlier v25.x releases.
Gateway API Inference Extension has brought increasing standardization to model serving ingress. The InferencePool resource groups serving endpoints, and the Envoy-based ext-proc gateway can route requests by model name or dynamic LoRA adapter based on parsed OpenAI-format payloads. Token-aware rate limiting at the gateway layer supports per-namespace budget management, useful for tracking consumption in multi-tenant inference environments.
KubeAI and KubeRay have both matured considerably. KubeAI (v0.23.2) runs on vanilla clusters without Knative or Istio dependencies and includes prefix-aware load balancing that can improve cache hit rates in LLM serving configurations with shared prompts or RAG context. KubeRay's continued development has strengthened Kueue integration and improved fault tolerance for long-running distributed jobs.
NVIDIA's KAI Scheduler has also gained attention in dedicated AI cluster environments. Built specifically for GPU workloads, it coordinates bin-packing, gang scheduling, and fair-share allocation with GPU topology awareness at the scheduling decision level. It is not yet as broadly deployed as Volcano in general-purpose clusters, but is worth evaluating for organizations running homogeneous NVIDIA hardware at scale.
A notable shift in 2026 is the increasing overlap between Kubernetes and HPC-style scheduling capabilities. Features that traditionally required dedicated HPC schedulers such as Slurm, including topology-aware placement, gang scheduling, and tight network fabric integration, are now supported in production Kubernetes deployments. Many organizations running both HPC and cloud-native workloads are consolidating toward a single Kubernetes-based control plane, though this convergence varies across deployment environments and hardware configurations. For organizations with geo-distributed GPU capacity, projects such as Karmada and Liqo are being evaluated for multi-cluster workload federation, though production adoption for distributed training specifically remains limited and warrants careful validation before use.
Frequently Asked Questions (FAQs)
Why are distributed PyTorch training pods stuck in Pending state when using the NVIDIA DRA driver on Kubernetes?
This is commonly caused by a version mismatch or missing prerequisite. Verify the cluster is running Kubernetes v1.34.2 or later with GPU Operator v26.3.1 or later, and that the legacy Device Plugin has been explicitly disabled. Container Device Interface (CDI) needs to be active in containerd or CRI-O, nodes require the nvidia.com/dra-kubelet-plugin=true label, and the NVIDIA driver should be version 580 or later. Running both the Device Plugin and DRA simultaneously creates scheduling conflicts that surface as Pending pods with misleading event messages.
What is the practical difference between Kueue and Volcano for GPU scheduling on Kubernetes, and should both be used together?
They handle different control layers. Kueue controls organizational quota enforcement and job admission, deciding which jobs enter the scheduling pool based on team allocations. Volcano coordinates scheduler-level gang scheduling and DRF-style fairness, continuously reacting to cluster state changes as jobs enter and leave the pool rather than processing each as a discrete pipeline event. Using Kueue without Volcano means gang scheduling for distributed workloads must be handled separately or not at all. Using Volcano without Kueue bypasses quota enforcement, which in multi-tenant clusters commonly leads to resource contention. Deploying both together, as layered and interacting control systems, is a common pattern in production AI clusters.
When is KubeAI the right choice for LLM serving on Kubernetes versus KServe or Triton?
KubeAI is well-suited for platforms primarily serving LLMs where minimal operational dependencies matter. It runs natively without Istio or Knative, and its prefix-aware load balancing is built for LLM inference patterns. KServe or Triton are generally a better fit when the serving environment includes diverse model types beyond LLMs, multi-framework pipelines, or ensemble serving configurations that need more flexible runtime support.
Is configuring both PFC and ECN on network switches actually necessary for RoCEv2 in distributed AI training?
In practice, yes, for high-throughput distributed training over Ethernet. PFC prevents packet drops during burst events by pausing upstream senders when buffers fill. Without ECN, relying on PFC alone introduces head-of-line blocking cascades that can freeze unaffected ports on the same switch. ECN signals senders to reduce injection rates before buffers reach capacity, reducing the conditions that trigger PFC. Running only one of the two tends to trade one class of network instability for another.
What is a practical starting configuration for multi-tenancy on a shared Kubernetes GPU cluster?
A reasonable baseline includes namespace-level ResourceQuotas with explicit GPU limits per team, a two-tier PriorityClass structure separating production inference from research and development, and GPU node taints that block CPU-only workloads from occupying accelerators. Before teams depend on preemption behavior in production, validate it under realistic conditions: interactions with PodDisruptionBudgets and termination grace periods can produce unexpected results. Once baseline isolation is stable, Kueue's borrowing policies let unutilized quota be used by other teams without permanently removing it from the original allocation.






