
When a company decides to run AI in the cloud, the first question is usually the wrong one.
Teams spend months debating which cloud provider is best. They compare pricing pages, read benchmark posts, and pick a winner. Then they move their AI workloads there and find the problems six months later.
The bill is higher than expected. Legal flags a compliance issue because certain customer records cannot leave the organization. The model training job that ran fine in testing is now queued for three days because the GPU instance type is oversubscribed. And inference latency is too high for the real-time product the team is building.
None of those problems come from picking the wrong provider. They come from treating the cloud decision as a single answer that applies to every AI workload, when it is actually a different answer for each one.
In 2026, the real question is not which cloud is best. It is: which AI workload belongs where?
The sections below cover what public cloud, private cloud, and hybrid cloud each do well for AI, where each model breaks down, and how production teams are splitting their AI workloads across environments to get the best of each.
Why AI Workloads Change the Cloud Equation
Before comparing cloud models, it helps to understand what makes AI workloads different from standard application workloads.
A typical web application has predictable compute requirements. It scales linearly with traffic, stores data in relational databases, and can usually run comfortably on general-purpose servers. The cloud choice for that workload is relatively straightforward.
AI workloads are spiky, GPU-hungry, and sensitive to data location in ways that normal applications are not.
Workload patterns are unpredictable
Model training is a burst workload. A team might need 64 H100 GPUs for 72 hours to train a model, then nothing for two weeks. Over-provisioning for that peak on private infrastructure means paying for idle hardware most of the time.
Inference is the opposite. Once a model is in production serving real users, it needs consistent, low-latency responses around the clock. Sudden traffic spikes need to be absorbed without queuing.
Data location drives cloud strategy more than compute does
For a regular API, data lives in a database and the compute can be anywhere. For AI workloads, the training data, embeddings, model weights, and user prompts all have to be in the right place at the right time. Moving large datasets across cloud boundaries is slow and expensive. Regulations in healthcare, finance, and government often make it legally constrained as well.
According to IDC research from early 2026, 64% of enterprise infrastructure leaders now describe their setup as hybrid, combining private and public environments specifically because different AI workload phases demand different infrastructure characteristics.
The cost curve is non-linear
Public cloud GPU pricing has shifted significantly. In June 2025, AWS announced up to a 45% price reduction for several EC2 NVIDIA GPU-accelerated instances, including P5 H100-based instances. This made burst training and experimentation more accessible, but sustained production GPU usage can still become expensive at scale.. That makes experiments and burst training more accessible than a year ago. But at sustained production scale running hundreds of GPUs around the clock, costs compound fast. Private infrastructure starts to make economic sense when utilization is consistently high and predictable.
Public Cloud for AI Workloads
Public cloud means running AI on infrastructure owned and operated by a third-party provider: AWS, Google Cloud, Microsoft Azure, or specialized AI cloud providers like CoreWeave and Lambda Labs.
The core advantage is access without ownership. A team can spin up 128 H100 GPUs in minutes, train a model for three days, and shut everything down. No procurement cycle, no hardware refresh cycle, no facility costs.
Where public cloud genuinely wins for AI
- Model training and experimentation: Public cloud is the natural home for burst GPU workloads. Training runs that need large GPU clusters for a short period are exactly what public cloud was designed for. The pay-as-you-go model means teams only pay during active training.
- Access to managed AI services: AWS Bedrock, Google Vertex AI, and Azure OpenAI Service give teams access to frontier models and managed MLOps pipelines without building the infrastructure themselves. This accelerates time-to-production significantly for teams without dedicated AI platform engineering capacity.
- Global inference deployment: Public cloud has data centers in dozens of regions. For applications serving users worldwide, deploying inference endpoints close to users reduces latency in ways that a single private data center cannot match.
- Startups and early-stage AI teams: When a team is still figuring out the right model architecture, the right data pipeline, and the right serving strategy, the flexibility of public cloud outweighs the cost premium. Committing to private infrastructure before the AI strategy is clear is expensive.
- Specialized AI-optimized hardware: Newer accelerators like NVIDIA H200 and Google TPU v5 often appear in public cloud before they are available for private procurement. Teams that need the latest hardware for competitive model performance access it faster through public cloud.
Where public cloud creates problems for AI
- Sustained workloads at scale: Running inference 24/7 on public cloud GPUs at production scale gets expensive fast.At sustained high utilization, public cloud GPU costs can become less economical than owned or dedicated infrastructure, especially when workloads run continuously instead of in short bursts. At dozens of GPUs for production inference, the public cloud bill grows into a significant line item that private infrastructure starts to challenge.
- Data sovereignty and compliance: Sending patient records, financial transaction data, or customer PII to a public cloud for AI processing triggers compliance obligations under GDPR, HIPAA, and sector-specific regulations. For some data types, this limits what public cloud can legally process.
- GPU availability constraints: During peak demand periods, specific GPU instance types get waitlisted. A team dependent on p4d or p5 instances on AWS for training may find them unavailable for days during high-demand periods.
- Data egress costs: Large model training runs require moving large datasets into the cloud. Egress fees when moving data out can create unexpected costs, particularly for teams iterating frequently between cloud training and on-premises analysis
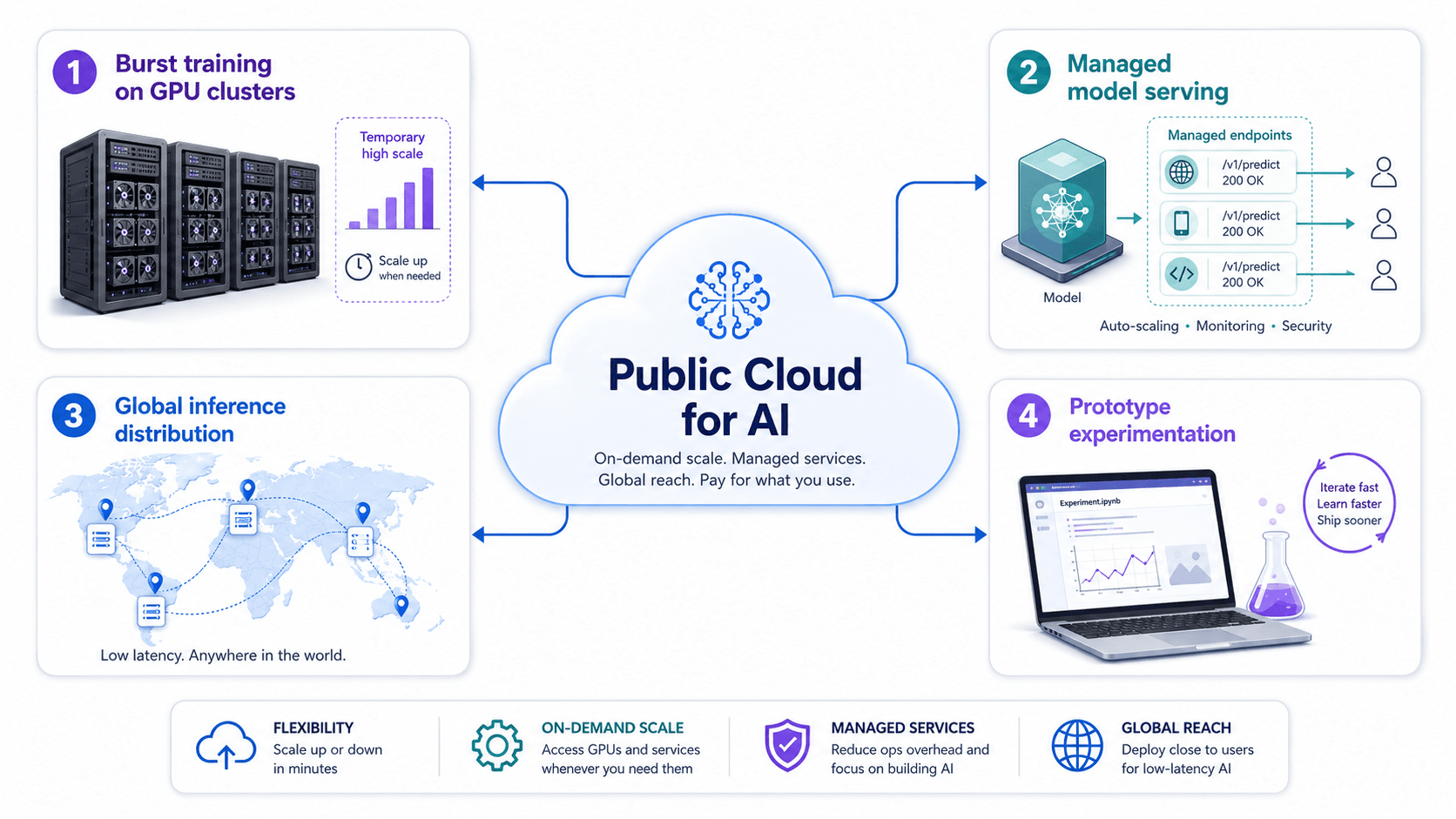 Public cloud AI use cases including burst GPU training, managed model serving, global inference, and fast experimentation.
Public cloud AI use cases including burst GPU training, managed model serving, global inference, and fast experimentation.
Private Cloud for AI Workloads
Private cloud means AI infrastructure that an organization controls exclusively, whether on-premises in its own data centers or through dedicated hardware hosted in a colocation facility. No other organization shares the physical hardware.Private cloud used to be framed as the legacy option. That framing is changing. Organizations running substantial AI workloads at sustained utilization are looking at the numbers differently in 2026.
Where private cloud genuinely wins for AI
- Sustained, predictable GPU utilization: When an organization consistently runs AI workloads at high utilization, the economics flip. Private GPU infrastructure can become more economical when it is used consistently over a multi-year period, especially when utilization stays around 60 to 70 percent or higher.
- Sensitive data that cannot move: Banks running credit risk models over live customer transaction data. Hospitals training diagnostic AI on patient records. Government agencies processing sensitive operational data. These organizations cannot send raw data to a third-party cloud for processing. Private infrastructure is not a choice for them; it is a constraint.
- Regulatory compliance with hard data residency requirements: Under GDPR Article 46, data leaving the EU requires specific transfer mechanisms. HIPAA requires physical and technical safeguards over PHI. Some national regulations in financial services mandate that customer data never leaves a specific country. Private cloud makes compliance straightforward by keeping data where the regulation requires.
- Low-latency inference close to operations: Manufacturing plants running computer vision for quality control. Retail stores running recommendation models at point of sale. Edge scenarios where network latency to a public cloud data center would break the user experience. Private infrastructure positioned close to the operation solves this where public cloud cannot.
- Proprietary model protection: Companies that have invested in custom model training on proprietary datasets treat model weights as intellectual property. Running those weights on private infrastructure reduces the risk of them being exposed to third-party infrastructure operators.
Where private cloud creates problems for AI
- Upfront capital investment: A meaningful private GPU cluster requires substantial upfront capital. A multi-GPU server plus the supporting network fabric, storage, and management infrastructure is a major procurement decision. Hardware delivery and setup typically takes months from approval to first workload.
- Utilization risk: Private infrastructure makes sense at high utilization. If AI workloads are still experimental or inconsistent, the hardware sits idle while the depreciation clock runs. Public cloud only charges when the compute is running.
- Operational burden: Private cloud requires teams to manage hardware failures, driver updates, network configuration, cooling, power, and security. Public cloud shifts most of that responsibility to the provider. For organizations without dedicated infrastructure teams, this is a significant hidden cost.
Hardware refresh cycles: GPU generations change rapidly. The H100 that leads performance benchmarks today will have successors within a few years. Private hardware purchases lock organizations into a specific generation for three to five years. Public cloud makes newer hardware available without a procurement cycle.
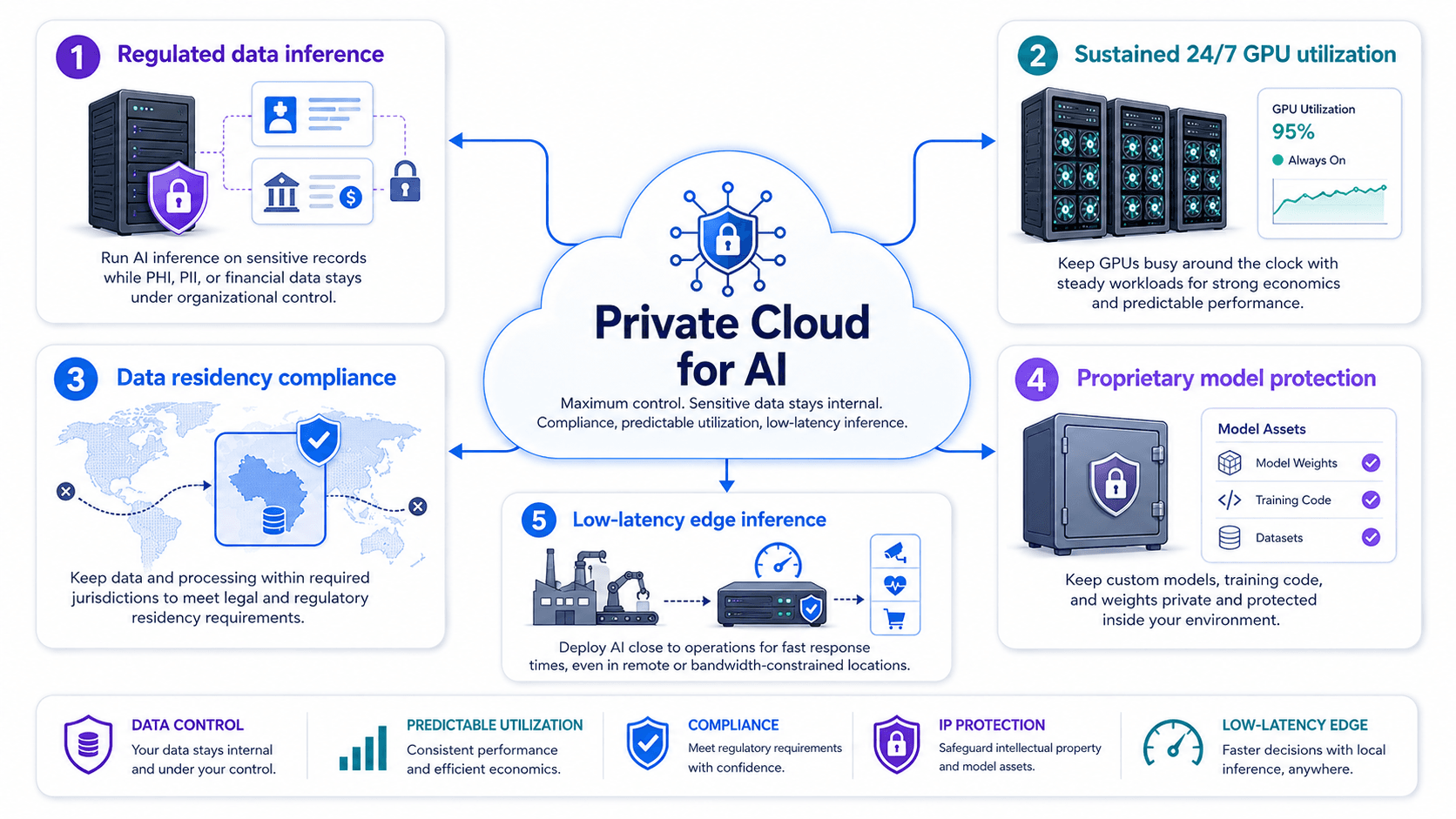 Regulated inference, data residency, model protection, and low-latency edge AI
Regulated inference, data residency, model protection, and low-latency edge AI
Hybrid Cloud for AI Workloads
Hybrid cloud means running different parts of an AI workload in different environments, treating public and private cloud as complementary rather than competing choices.
Recent enterprise infrastructure trends show hybrid environments becoming more common as teams split workloads by data sensitivity, utilization pattern, latency, and operational control. For AI specifically, hybrid is increasingly the default architecture for production systems, not a transitional state between old infrastructure and full cloud migration.
The core logic is simple: keep sensitive data and high-utilization inference on private infrastructure. Use public cloud for burst training, experimentation, and workloads without data restrictions.
How AI workloads split across hybrid environments
| AI Workload Type | Where It Runs in Hybrid | Why |
|---|---|---|
| Model training on proprietary data | Private cloud | Data never leaves the organization. Training happens on internal hardware. |
| Model training on anonymized or public data | Public cloud | No compliance restrictions. Burst GPU capacity on demand without idle hardware costs. |
| Production inference on sensitive data | Private cloud | Customer records, financial data, medical data stays within controlled infrastructure. |
| Production inference on non-sensitive data | Public cloud | Global reach, managed scaling, no hardware maintenance. |
| Burst inference during traffic spikes | Public cloud | Private infrastructure handles baseline. Public cloud absorbs the overflow. |
| Experimentation and prototyping | Public cloud | No long-term commitment. Flexible and fast. Cost-appropriate for uncertain workloads. |
| Fine-tuning on internal datasets | Private cloud | Proprietary training data and adapted model weights stay internal. |
| RAG with internal document stores | Private cloud or private edge | Sensitive documents in the retrieval pipeline cannot go through external APIs. |
Real examples of hybrid AI in production
Healthcare AI:
Patient records and DICOM images stay on HIPAA-compliant private infrastructure. AI models for diagnostic imaging are trained on anonymized datasets on public cloud GPU clusters. Trained model weights are then deployed back to hospital edge servers for real-time inference on patient data. The compute happens on public cloud. The sensitive data never leaves the hospital network.
Financial services:
A bank runs fraud detection models on private infrastructure because transaction data cannot leave the organization under internal policy and regulatory requirements. Model retraining, which uses anonymized transaction patterns rather than raw account data, runs on public cloud during off-peak hours. The bank gets public cloud elasticity for training without sending customer data outside its perimeter.
Retail AI:
A retailer runs recommendation engine inference on public cloud during normal operations, scaling automatically with traffic. During peak periods like major sale events, the system bursts aggressively into additional public cloud capacity without requiring permanent hardware. Customer purchase history used for personalization stays in private storage but the inference computation happens in cloud. This approach handled seasonal demand spikes without maintaining year-round peak capacity.
Where hybrid cloud creates problems
- Complexity of managing two environments: Hybrid requires orchestration between public and private infrastructure. Networking, identity management, data pipelines, and deployment automation all span two environments. The operational overhead is real and requires dedicated platform engineering.
- Data movement latency: When training on public cloud requires data from private storage, the transfer time becomes part of the training cycle. For very large datasets, this can be the dominant bottleneck rather than GPU compute.
Cost unpredictability in burst scenarios: Private infrastructure has predictable fixed costs. Public cloud burst capacity has variable costs. During unexpected traffic events, the public cloud bill can spike in ways that are hard to forecast.
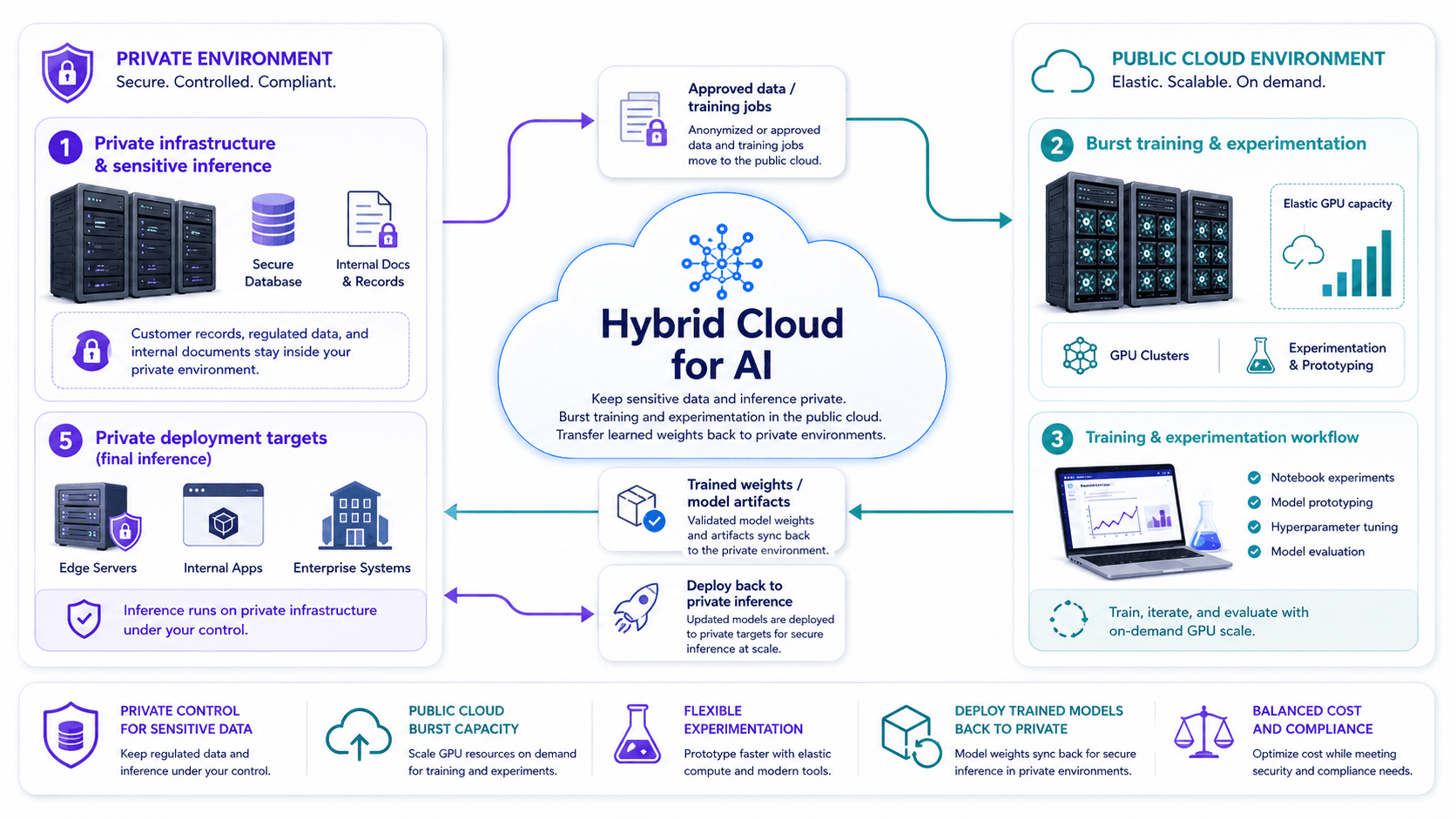 Private inference, public-cloud training, and secure private deployment
Private inference, public-cloud training, and secure private deployment
Direct Comparison: Public vs Private vs Hybrid for AI
| Factor | Public Cloud | Private Cloud | Hybrid Cloud |
|---|---|---|---|
| GPU access | On-demand, wide variety, newest hardware available fast | Fixed hardware, long procurement cycle | On-premises baseline, public cloud for burst and new hardware |
| Cost model | Variable, pay-per-use, scales up and down | Fixed CAPEX, predictable at scale, expensive when underutilized | Predictable baseline costs, variable burst costs |
| Data sovereignty | Depends on region and provider compliance certifications | Full control, data never leaves your infrastructure | Sensitive data stays private, non-sensitive can go to public cloud |
| Compliance | Requires careful review of shared responsibility model | Straightforward for regulated data | Split by data sensitivity, requires clear data classification policy |
| Inference latency | Depends on region choice, managed scaling helps | Low if infrastructure is close to users or operations | Private for low-latency critical inference, public for distributed global serving |
| Scalability | Near-unlimited burst capacity | Limited by hardware on hand, requires procurement to scale | Private handles baseline, public handles burst |
| Operational overhead | Low, managed by provider | High, team responsible for all hardware and software | Medium to high, requires coordination across both environments |
| Model IP protection | Relies on provider security controls | Full control over model weights and serving environment | Private infrastructure for proprietary models, public for non-sensitive serving |
| Time to first GPU | Minutes | Weeks to months including procurement | Immediate for private capacity, minutes for public burst |
| Best for | Startups, experimentation, training, global inference | Regulated industries, sustained high utilization, sensitive data | Most enterprise AI systems at production scale |
How to Decide Which Model Fits Your AI Workload
The comparison table is useful, but the real decision comes from asking the right questions about each specific AI workload, not the organization as a whole. Most production AI teams end up with a mix. The decision framework looks like this:
Step 1: Classify the data the workload touches
- Does the workload process regulated data (PHI, PII, financial records, government data)?
- Are there hard legal requirements about where this data can be stored and processed?
- Does internal policy restrict this data from leaving the organization's infrastructure?
If the answer to any of these is yes, the training data and inference serving for this workload belong on private infrastructure or a sovereign cloud offering. Public cloud may still handle training on anonymized versions of the dataset.
Step 2: Assess the utilization pattern
- Is this workload running continuously at high GPU utilization (above 60 to 70 percent)?
- Or is it bursty, running intensively for short periods then going quiet?
Sustained high utilization favors private cloud economics. Bursty workloads favor public cloud pay-as-you-go pricing. Workloads that have a steady baseline with occasional spikes are the clearest case for hybrid architecture.
Step 3: Evaluate latency requirements
- Does this workload need sub-100ms response times for user-facing features?
- Is the inference happening close to a physical operation (factory, hospital, retail location)?
Low-latency requirements usually point toward private infrastructure or edge deployment close to the operation. Public cloud inference latency depends heavily on region selection and network path.
Step 4: Consider the team's operational capacity
Private cloud requires a team that can manage hardware, handle failures, update drivers, maintain networking, and operate the full stack. If the platform engineering team does not have that capacity today, starting on public cloud and moving specific workloads to private infrastructure as utilization and compliance needs justify it is the lower-risk path.
| A practical starting point: Most enterprise teams starting AI workloads in 2026 begin on public cloud for speed, then move high-utilization inference workloads and compliance-constrained data processing to private infrastructure as production use cases are proven. Hybrid becomes the natural steady state. |
The Data Sovereignty Factor in 2026
Data sovereignty has quietly become the factor that determines cloud architecture for more enterprise AI programs than cost or GPU access. It does not get as much attention as performance benchmarks, but it is the constraint that kills plans that looked good on paper.
Hyperscalers have responded to this by building sovereign cloud offerings. AWS launched its European Sovereign Cloud. Google and Microsoft have expanded regional compliance certifications. But sovereign cloud offerings often come at a premium. According to BCG analysis, some sovereign and government cloud offerings carry roughly 10% to 30% price premiums over standard public cloud regions, depending on provider and isolation requirements.
For regulated industries, that premium may still be cheaper than building private infrastructure. For organizations that need both AI compute scale and strict data sovereignty, the calculation varies by workload volume and regulatory jurisdiction.
The broader enterprise trend is a shift from cloud-first migration to workload-by-workload placement, where sensitive, regulated, or latency-critical AI workloads are evaluated separately from bursty and experimental workloads.
The clearest pattern emerging is workload-level data classification driving infrastructure placement decisions. Sensitive workloads stay private or sovereign. Non-sensitive workloads run on standard public cloud. The organization maintains a clear inventory of which workload type is which.
Cost Reality Check
Cloud pricing comparisons are easy to find and hard to trust. The right answer depends entirely on utilization rate, commitment model, workload type, and the operational costs that never appear on a provider pricing page.
Here is what the cost picture actually looks like across the three models.
Public cloud GPU costs
In June 2025, AWS announced up to a 45% reduction for several EC2 NVIDIA GPU-accelerated instances, including P5 H100-based instances. Percentage reductions make short-term experimentation and burst training more attractive, but they do not remove the need for workload-level cost modeling. Sustained production inference can still become expensive when GPUs run continuously.
Discount models such as Spot, preemptible capacity, reserved commitments, and savings plans can reduce compute costs compared with on-demand usage. However, they also introduce trade-offs around availability, interruption risk, commitment length, and workload flexibility. For AI workloads, teams should also model non-compute costs such as data transfer, storage, high-performance networking, observability, and managed service premiums.
Private cloud GPU economics
Private GPU infrastructure requires significant upfront capital. Hardware alone is a major investment before factoring in facility costs, power, networking, and the engineering team to operate it. Amortized over three years, the fully-loaded cost per GPU-hour depends almost entirely on utilization.
Private GPU economics depend heavily on utilization. When GPUs are used consistently for production workloads, owned or dedicated infrastructure can become more economical over time. When utilization is low or unpredictable, public cloud usually remains safer because teams pay only for active usage. The crossover point varies by hardware, financing, power, staffing, depreciation, and workload pattern.
Hybrid cost optimization
The economic case for hybrid is straightforward. Private infrastructure handles the predictable, high-utilization baseline where the economics favor ownership. Public cloud absorbs burst demand without requiring permanent hardware provisioned for peak load that only occurs occasionally. Retail teams serving steady-state inference from private infrastructure while bursting into public cloud for seasonal traffic spikes demonstrate this pattern clearly.
| Note: Percentage-based pricing changes vary by provider, region, instance family, commitment model, and availability. Use provider pricing pages and current quotes before making final infrastructure decisions. |
Quick Decision Checklist
Use this to quickly categorize an AI workload before making infrastructure decisions.
Choose public cloud when:
☐ The workload is experimental or utilization is unpredictable
☐ Data has no legal or policy restrictions on third-party processing
☐ GPU clusters are needed for short burst training runs
☐ Global inference deployment with low-latency across multiple regions is required
☐ The team does not have private cloud management capacity
☐ Access to managed AI services (Bedrock, Vertex, Azure OpenAI) adds significant value
Choose private cloud when:
☐ The data is regulated and legally cannot leave organizational control
☐ GPU utilization is consistently high and predictable
☐ Inference needs to happen close to physical operations with sub-100ms requirements
☐ Proprietary model weights need to be protected from third-party infrastructure access
☐ Three-year cost modeling shows private infrastructure is more economical at expected utilization
Choose hybrid when:
☐ Some data is regulated and some is not, and both types feed AI workloads
☐ Baseline inference load is predictable but traffic spikes require burst capacity
☐ Training can use anonymized data (public cloud) but inference must use raw data (private)
☐ The organization wants to start with public cloud speed and migrate proven workloads to private
☐ Multiple AI use cases exist with different data sensitivity levels
Common Mistakes Enterprises Make
Treating the cloud decision as organization-wide rather than workload-specific
"We are a public cloud company" or "we run everything on-premises" are infrastructure philosophies, not AI strategies. Different AI workloads have different requirements. Applying the same answer to all of them leads to either compliance failures (regulated data on public cloud) or unnecessary cost (experimental workloads on private hardware).
Underestimating operational overhead of private infrastructure for AI
GPU infrastructure management is significantly more complex than standard server management. CUDA driver updates, GPU health monitoring, network fabric for multi-GPU training, and the management of large model artifact storage all require specialized skills. Organizations that move to private cloud for AI without building this operational capacity often find the savings eroded by engineering time.
Ignoring egress costs in hybrid architectures
Moving large datasets between private storage and public cloud for training is slow and often expensive. A dataset that looks small for model training (a few terabytes) can generate significant egress charges when moved repeatedly during iterative training cycles. Hybrid architecture designs need to account for data movement costs and latency, not just compute costs.
Over-committing to reserved instances before workload patterns are clear
Public cloud reserved instances offer 30 to 40 percent savings over on-demand but require one-year or three-year commitments. Teams that commit before they understand their actual GPU utilization patterns often find themselves locked into capacity they are not using, or committed to instance types that do not match their evolved model requirements.
Assuming sovereign cloud is the same as private cloud
Sovereign cloud offerings from public cloud providers keep data within a jurisdiction but still run on infrastructure the provider controls. For organizations where data sovereignty means full control over the physical infrastructure, sovereign cloud may not be sufficient. The distinction matters for high-security workloads.
Frequently Asked Questions
Is public cloud or private cloud cheaper for AI?
It depends on GPU utilization. Public cloud is cheaper for bursty workloads with low average utilization. Private cloud can become cheaper when GPU utilization is consistently high, predictable, and the infrastructure can be amortized over multiple years. Public cloud is usually better for bursty, experimental, or uncertain workloads. Most production AI programs end up with both, using each where the economics favor it.
Can regulated data be processed on public cloud for AI?
Some regulated data can be processed on public cloud if the provider has the right compliance certifications and contractual agreements in place. HIPAA Business Associate Agreements are available from AWS, GCP, and Azure. However, some national regulations mandate data never leaves a specific jurisdiction, which may require private or sovereign cloud infrastructure. Legal review of specific data types and applicable regulations is necessary before making this decision.
What is the best cloud model for LLM training?
Public cloud is generally the preferred environment for LLM training because training runs are bursty workloads that benefit from on-demand GPU clusters. Private cloud is preferred when the training data is highly sensitive and cannot be sent to a third-party provider. Hybrid handles the case where some training data is sensitive (stays private) and some is not (processed on public cloud).
How do enterprises handle the hybrid cloud complexity?
Kubernetes has become the standard orchestration layer that works across both public and private environments, providing a consistent interface for deploying AI workloads regardless of where the underlying infrastructure runs. Organizations also use dedicated interconnects or VPN connections between private data centers and public cloud regions to reduce latency and egress costs on data movement.
When does hybrid cloud not make sense for AI?
Hybrid cloud adds operational complexity. For small teams or early-stage AI programs, that complexity is not justified. If all data is unrestricted and workloads are bursty, public cloud alone is simpler and more economical. If all data is highly regulated and workloads are steady-state, private cloud alone avoids the management overhead of bridging two environments.






