
1. The Anatomy of a Deployment Failure
Consider a common production outage: a team ships a clean feature with a renamed column, code reviews pass, staging is perfect, and the CI/CD pipeline goes green. Yet, the moment the rolling deployment begins, the system floods with 500 errors and users are locked out.
The application logs reveal the culprit: column "username" does not exist.
This failure occurs because the new code is looking for a database structure that hasn't been finalized, or the migration ran too early, destroying a column that older, surviving pods still require to function. This is the reality of modern cloud infrastructure—it is not a database bug, but a failure to recognize that a container rollout is a gradual process rather than an instantaneous event.
2. The Fallacy of Atomic Deployments
Most deployment failures stem from a dangerous architectural assumption: that a deployment is an atomic event where the old version instantly vanishes and the new version takes over.
In a distributed, highly available system like Kubernetes, this is impossible. To ensure zero downtime, the platform deliberately runs old and new versions of your application side-by-side for a window of several minutes during a rollout. This is the Dual-Read/Write Window.
During this overlap, two entirely different generations of application code are hitting a single database schema simultaneously. As illustrated above, traffic routes to both the updated app pods and the legacy ones. If those two versions are structurally incompatible, the system breaks. Achieving zero downtime is not a database engineering problem; it is a distributed system coordination problem.
3. The Architectural Strategy: The Expand-Contract Pattern
To survive the dual-read/write window, you must decouple database schema changes from application code rollouts. The industry standard for this is the Expand-Contract (or Parallel Change) pattern, which breaks a single logical database change into three independent, backward-compatible phases deployed across separate release cycles.
Case Study: Renaming a Column Safely
Instead of executing a destructive, single-step column rename from user_name to full_name, the pattern orchestrates the change incrementally:
- Phase 1: Expand (Prepare the Schema): You add the new full_name column but leave the old one completely intact. You backfill historical data and set up a database trigger to automatically sync any incoming writes from the old column to the new one. The database has expanded to support both states.
- Phase 2: Deploy Code (The Overlap Window): You roll out the new application code. During the rolling update, legacy pods read and write to user_name (and the trigger copies it), while new pods read and write to full_name. Because both database structures exist simultaneously, zero errors occur during the transition.
- Phase 3: Contract (The Cleanup): Once telemetry confirms 100% of the old pods are dead and only new code is running, the old column is safely abandoned. You delete the sync trigger and drop the legacy user_name column.
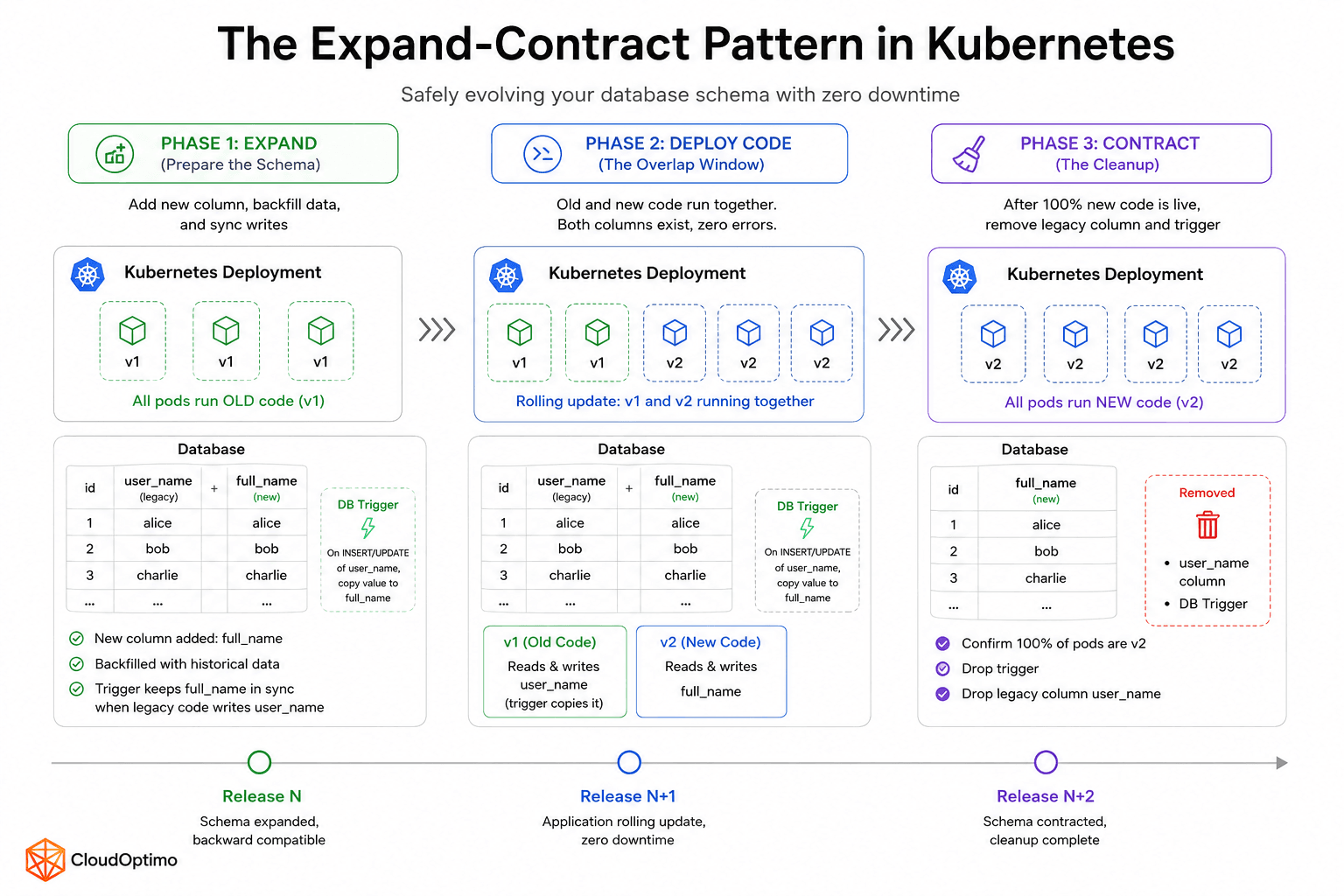
Fig. 3.1 Expand-Contract Pattern in Kubernetes
The Expand-Contract pattern applies not only to schema renames but also to constraint changes. One of the most common production incidents occurs when teams add NOT NULL constraints directly to large tables.
4. The "Not Null" Lockout Trap
Shifting to this mindset changes how you approach standard operational tasks, such as adding a NOT NULL constraint to a live table.
If you apply a native NOT NULL constraint to a table with millions of rows, the database must instantly validate every historical row to ensure compliance. To guarantee data consistency during this check, the database engine acquires an exclusive table lock. This lock completely freezes all incoming application reads and writes, resulting in API timeouts and cascading service degradation.
The Conceptual Fix
Instead of forcing the database to validate the past, present, and future of your data in a single locked transaction, you isolate the risks:
- Add the space first: Add the column as nullable. This is an instantaneous operation that requires no heavy lock.
- Fix the past slowly: Backfill historical rows in small, quiet background batches to protect database performance.
- Enforce the future first: Tell the database to enforce the constraint only on new rows moving forward (NOT VALID).
- Validate the past safely: Instruct the database to scan the historical rows using a background process that explicitly allows normal application traffic to continue reading and writing concurrently.
- Flip the switch: Once the database confirms the past is clean, finalize the constraint natively.
5. Infrastructure Discipline: Guarding the Gate
Because human discipline can fail under production pressures, your infrastructure and CI/CD pipelines must enforce these structural principles automatically.
- Distributed Locking: In a Kubernetes environment, multiple application pods can start simultaneously during scaling events, rolling updates, or cluster recoveries. If each pod attempts to execute migration scripts independently, they can compete for schema changes, resulting in migration failures, deadlocks, or even data corruption. To prevent this, migration frameworks such as Flyway and Liquibase use a shared database lock mechanism that ensures only one migration process can run at a time. Every other instance must wait until the active migration completes, creating a safe and predictable execution order.
- Hard Ordering (Sync Waves): Schema changes and application deployments must never occur concurrently without coordination. The database migration phase should complete successfully before Kubernetes begins rolling out application pods that depend on the new schema. This ordering can be enforced through GitOps Sync Waves, Helm hooks, Kubernetes Jobs, or CI/CD pipeline gates. By treating migrations as a prerequisite step rather than part of the application startup process, you guarantee that every new pod launches against a database state it fully understands, eliminating an entire class of deployment failures.
This approach transforms database migrations from a best-practice recommendation into an enforceable deployment contract, ensuring that schema evolution remains safe, repeatable, and independent of human intervention.
6. The Ultimate Zero-Downtime Runbook
When database migrations are designed using backward-compatible principles, incident response becomes much simpler and safer. Instead of treating the application and database as a single deployment unit, you can manage them independently.
The Golden Rule of Rollbacks: If a deployment fails, roll back the application code (kubectl rollout undo)—not the database.
Here's why this approach works:
- The database was expanded, not replaced.
During the Expand phase, new schema elements are added without removing existing ones. This allows both old and new application versions to operate against the same database safely. - Old application versions remain compatible.
If the newly deployed application contains bugs or performance issues, Kubernetes can quickly restore the previous version. Because the old schema still exists, legacy pods continue functioning without any database changes. - Application rollbacks are fast and low-risk.
Rolling back a Deployment typically takes only a few minutes and does not affect stored data. This makes it the safest first response during an incident. - Database rollbacks are expensive and risky.
Reverting schema changes can involve restoring dropped columns, reversing data transformations, or recovering lost records. Under production pressure, these operations significantly increase the risk of data corruption or data loss. - The Expand-Contract pattern decouples recovery actions.
Because schema evolution is backward-compatible, the application can move forward or backward independently of the database. This separation dramatically reduces operational complexity during outages. - Recovery becomes predictable.
Instead of debugging both the application and database simultaneously, teams can immediately restore service by rolling back the application and investigating the issue later.
7. The Zero-Downtime Checklist
If you take away nothing else from this architectural shift, keep these four fundamental principles at the front of your mind during your next design review:
- Deployments Are Processes, Not Events: Never assume your code changes and database changes happen simultaneously. Design every schema evolution with the expectation that old and new code will run side-by-side.
- The Three-Step Rule: If a database modification forces you to change even a single line of existing application code, it cannot be done in one deployment. It must use the Expand, Deploy Code, and Contract phases.
- Isolate the Future from the Past: When adding constraints like NOT NULL or foreign keys to large, live datasets, never validate historical records and future writes in the same transaction. Enforce the future instantly, and patch the past gradually.
Application-Only Rollbacks: Protect your data integrity by ensuring that your database migrations are always backward-compatible. If a rollout experiences anomalies, your immediate remediation should always be a safe application rollback—never an emergency database reversion.






