
1. Introduction
Retrieval-Augmented Generation (RAG) has become a widely adopted architecture for enterprise AI applications. By combining large language models (LLMs) with external knowledge sources, RAG helps deliver more accurate and context-aware responses.
However, moving from a proof of concept to production introduces new challenges, including scaling, retrieval performance, inference latency, security, and operational reliability. Managing these interconnected components requires a platform capable of supporting dynamic and distributed workloads.
Kubernetes has emerged as a strong foundation for production RAG deployments, providing automated orchestration, scaling, and resource management for retrieval services, vector databases, embedding models, and LLM inference workloads.
2. Understanding Production RAG Architecture
A production RAG system consists of several interconnected components that work together to generate responses grounded in enterprise data.
The process begins when a user submits a query. The retrieval layer searches relevant information from a knowledge base stored in a vector database. Documents are represented as embeddings generated through embedding models. Retrieved context is then combined with the user query and sent to an LLM inference service. The model generates a response using both its training knowledge and the retrieved information.
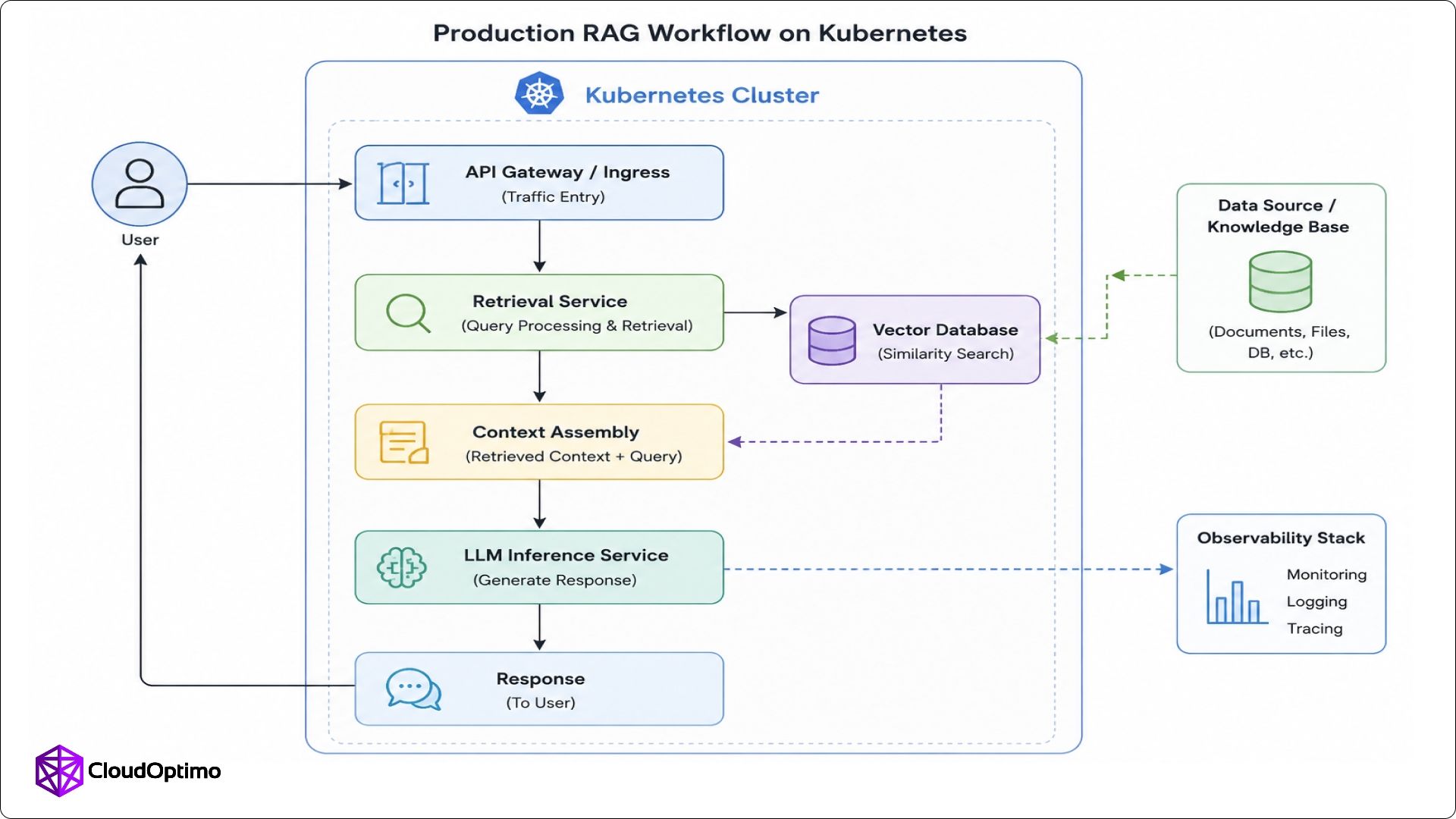
Production RAG Workflow on Kubernetes: The above architecture illustrates how a production RAG workflow on Kubernetes processes user queries through retrieval services, vector databases, context assembly, and LLM inference to generate grounded responses.
Unlike traditional applications, RAG systems contain multiple compute-intensive layers. The retrieval service, vector database, embedding generation service, and inference engine all have different resource requirements and scaling patterns. Production deployments must therefore treat each layer as an independent service while ensuring seamless communication across the entire pipeline.
Core Components of a Production RAG Platform
| Component | Purpose | Kubernetes Deployment Consideration |
| Retrieval Service | Processes user queries and retrieves relevant context | Stateless pods with horizontal scaling |
| Embedding Service | Converts content into vector embeddings | CPU or GPU-backed workloads |
| Vector Database | Stores and searches embeddings | Persistent storage and high availability |
| LLM Inference Service | Generates responses using the retrieved context | GPU scheduling and autoscaling |
| API Gateway | Routes incoming requests | Load balancing and traffic management |
| Observability Stack | Monitoring, logging, and tracing | Cluster-wide visibility |
This architectural separation enables organizations to optimize performance, availability, and cost while maintaining consistent user experiences.
3. Why Kubernetes is Well-Suited for RAG Workloads
Production RAG systems operate across multiple layers, including retrieval, embeddings, vector search, and inference. Each of these layers has different infrastructure requirements, making workload orchestration a critical part of production deployment. Kubernetes addresses this by providing a consistent control plane for managing complex AI workloads.
One of Kubernetes’ biggest advantages is declarative deployment management. Teams can define infrastructure states in configuration files, making deployments predictable and repeatable across development, staging, and production environments. This reduces operational inconsistency and simplifies version control for AI systems.
Resource scheduling is another important capability. Retrieval services often need CPU-optimized nodes, while embedding and inference workloads may require GPU-backed infrastructure. Kubernetes allows teams to schedule workloads based on these requirements, ensuring efficient resource allocation without unnecessary contention.
Kubernetes also provides built-in mechanisms for service discovery, load balancing, rolling updates, and self-healing. These capabilities help maintain stable communication between RAG services while improving deployment reliability. For example, if a retrieval service instance fails, Kubernetes automatically replaces it. If traffic increases, additional pods can be deployed to maintain application responsiveness.
Autoscaling further improves operational efficiency. Since RAG workloads often experience unpredictable traffic patterns, Kubernetes can dynamically scale services based on demand. This helps maintain application responsiveness while optimizing infrastructure usage during peak and low-traffic periods.
Fault tolerance is equally important in production environments. Kubernetes continuously monitors workloads and replaces failed pods automatically, reducing downtime and improving service reliability. Rolling updates also allow teams to deploy changes without disrupting live traffic.
For organizations operating across hybrid or multi-cloud environments, Kubernetes provides a consistent deployment model. This portability makes it easier to standardize infrastructure practices while supporting distributed AI workloads across regions and cloud providers.
4. Designing a Kubernetes-Based RAG Platform
Designing a production RAG platform on Kubernetes requires separating each functional layer into independent services. This architectural separation improves scalability, operational flexibility, and fault isolation.
The retrieval layer is typically deployed as stateless microservices responsible for processing user queries, performing reranking, and assembling relevant context. Because these services handle high request volumes, they are usually horizontally scalable.
Vector databases such as Milvus, Weaviate, or Qdrant should be deployed with persistent storage and replication strategies to ensure durability and high availability. These systems form the knowledge retrieval backbone of the platform.
Embedding services are often isolated into separate workloads because they consume significant CPU or GPU resources. This separation prevents embedding generation from affecting retrieval latency and allows teams to scale ingestion pipelines independently.
LLM inference endpoints represent the most compute-intensive part of the architecture. These workloads are commonly deployed on dedicated GPU nodes with autoscaling policies designed around token throughput and request concurrency.
Networking between these services must remain efficient and observable. Service mesh layers can improve internal traffic routing, policy enforcement, and distributed tracing, especially in larger production environments.
By structuring RAG components as independent Kubernetes workloads, organizations gain better control over scaling, resource allocation, and operational stability across the entire AI pipeline.
5. Storage and Data Management Strategies
Knowledge bases continuously evolve. Documents are added, updated, and removed over time, requiring efficient storage and synchronization mechanisms.
Vector indexes must remain consistent with source documents. Automated ingestion pipelines help process content, generate embeddings, and update vector databases without disrupting production workloads.
Persistent storage solutions ensure vector indexes survive pod restarts and infrastructure changes. Organizations should also establish backup and recovery procedures to protect critical knowledge assets.
As datasets grow, storage architecture becomes increasingly important. Effective data partitioning, indexing strategies, and lifecycle management policies contribute significantly to retrieval performance and operational efficiency.
A well-designed storage strategy ensures that RAG systems continue delivering accurate and relevant information even as enterprise knowledge repositories expand.
6. Performance Optimization for Production RAG Systems
Performance directly shapes the effectiveness of production RAG systems. Even when retrieval quality is high, inefficient pipeline execution can increase latency and reduce overall responsiveness.
At the application level, optimization starts with how data is structured and retrieved. Poor chunking strategies often create excessive vector entries, increasing search complexity and reducing retrieval precision. Well-balanced chunk sizes improve both context quality and retrieval speed.
Key optimization areas include:
- Chunking strategy and overlap control
- Vector index tuning
- Context compression
- Request batching
- Response caching
Vector search performance depends heavily on indexing methods and similarity search configuration. Choosing the right indexing strategy and limiting unnecessary retrieval depth can significantly reduce lookup time.
Prompt construction also plays an important role. Sending large context windows increases token usage and inference latency. Many production systems improve efficiency by compressing retrieved context and selecting only the highest-relevance chunks before inference.
Batching is another important optimization layer. Processing multiple embedding requests or inference calls together improves throughput and reduces resource fragmentation. Combined with intelligent caching for repeated queries, this helps lower end-to-end latency across the RAG pipeline.
Production optimization is not a one-time task. As workloads evolve, teams must continuously refine retrieval logic, prompt construction, and indexing strategies to maintain efficient performance.
7. Autoscaling Retrieval and Inference Layers
While performance optimization improves the efficiency of the RAG pipeline itself, autoscaling ensures the infrastructure can handle changing workload demands.
Retrieval and inference services behave very differently under load, which makes independent scaling essential.
Retrieval services are typically CPU-bound and respond directly to incoming request spikes. During high-traffic periods, additional retrieval pods may be required to maintain fast vector search and context assembly. Horizontal Pod Autoscaler (HPA) is commonly used here to scale based on CPU utilization or request throughput.
Inference services introduce a different scaling challenge. Large language models are GPU-intensive and often constrained by memory, token throughput, and queue depth rather than CPU usage. This makes traditional autoscaling less effective.
Many teams use Kubernetes Event-Driven Autoscaling (KEDA) to improve scaling accuracy by reacting to:
- Queue length
- Concurrent requests
- Token generation rate
- GPU utilization
GPU scheduling also becomes critical at this layer. Proper node pools, taints, and tolerations help ensure inference workloads are assigned to dedicated GPU nodes without competing with retrieval or embedding services.
Separating autoscaling policies for retrieval and inference enables better resource utilization. Retrieval layers can scale aggressively during query bursts, while inference layers scale more deliberately based on model-serving capacity.
This separation improves elasticity, maintains stable response times, and helps organizations manage infrastructure costs more efficiently as production RAG workloads grow.
8. Observability for Production RAG Workloads
Observability plays a critical role in maintaining reliable production RAG systems. Unlike traditional applications, RAG pipelines involve multiple interconnected layers, including retrieval services, vector databases, embedding models, and inference engines. This makes end-to-end visibility essential for identifying performance patterns before they impact users.
Instead of reacting to failures after they occur, engineering teams use observability to detect anomalies early and maintain predictable system behavior under varying workloads.
Important metrics to continuously monitor include:
- Retrieval latency
- Vector search duration
- Embedding generation time
- LLM inference latency
- Token consumption per request
- GPU utilization
- Queue depth for inference workloads
- Request success rate
Distributed tracing helps teams map how requests move across the RAG pipeline, making it easier to understand latency distribution across retrieval, embedding, and inference stages. This is especially useful when traffic increases or when infrastructure changes are introduced.
Logging also provides critical operational context. Structured logs can reveal unusual query patterns, prompt construction issues, token spikes, and service-level inconsistencies that may not immediately appear in standard metrics.
A mature observability strategy allows engineering teams to establish performance baselines, set alert thresholds, and detect system degradation early. In production RAG environments, this proactive visibility often becomes the difference between stable performance and unpredictable user experiences.
9. Security and Governance Considerations
Production RAG systems often access proprietary business information, making security a critical requirement.
Authentication and authorization controls should protect AI APIs and internal services. Kubernetes secrets management capabilities help secure credentials and sensitive configuration data.
Network policies can restrict communication between services, reducing the attack surface within the cluster. Role-based access control ensures users and services only receive the permissions necessary to perform their functions.
Governance is equally important. Organizations should maintain visibility into data sources, document access patterns, and AI interactions. Comprehensive audit trails support compliance initiatives while improving operational transparency.
By integrating security throughout the platform architecture, teams can build trustworthy and resilient AI systems.
10. Cost Optimization Strategies
As RAG workloads grow, infrastructure efficiency becomes increasingly important. Retrieval services, vector databases, embedding models, and LLM inference endpoints can generate significant compute costs if resources are not managed effectively.
Right-sizing workloads helps eliminate resource waste. Teams should continuously evaluate CPU, memory, and GPU utilization to ensure infrastructure aligns with actual demand.
Autoscaling contributes significantly to cost optimization by allocating resources dynamically based on workload requirements. Storage optimization strategies, including efficient indexing and data lifecycle management, further reduce operational expenses.
Organizations should also monitor model utilization patterns and identify opportunities for batching, caching, and workload consolidation.
Cost optimization is most effective when treated as a continuous operational practice rather than a periodic review exercise.
11. Best Practices for Running Production RAG Workloads on Kubernetes
Running production RAG workloads successfully requires more than deploying containers and scaling infrastructure. Organizations must establish architectural and operational practices that support long-term reliability, performance, and maintainability.
One important practice is maintaining a clear separation between retrieval, embedding, vector search, and inference services. Each component has different resource requirements and scaling characteristics. Isolating them enables teams to optimize infrastructure independently while preventing one workload from affecting another.
Observability should be implemented from the beginning of the deployment lifecycle. Monitoring metrics such as retrieval latency, vector search duration, GPU utilization, token generation throughput, and request success rates provides visibility into platform health. Early detection of bottlenecks helps teams maintain consistent application performance as workloads grow.
Automation is equally important for production environments. Infrastructure provisioning, application deployment, configuration updates, and scaling policies should be managed through Infrastructure as Code (IaC) and CI/CD pipelines. Automated workflows reduce operational overhead and improve deployment consistency across environments.
Organizations should also establish regular performance testing processes. Simulating realistic traffic patterns helps validate autoscaling behavior, infrastructure capacity, and response times before new features reach production. This proactive approach supports predictable performance under varying workloads.
Finally, knowledge bases should be treated as continuously evolving assets. Automated ingestion pipelines, validation checks, and document lifecycle policies help ensure that retrieval systems provide relevant and up-to-date context for AI applications.
By combining strong operational practices with Kubernetes-native capabilities, organizations can build RAG platforms that remain scalable, reliable, and efficient as AI adoption expands.
12. Frequently Asked Questions (FAQ)
1. Why are my Kubernetes pods healthy, but RAG responses are still slow?
This usually means the bottleneck exists inside the application layer rather than the Kubernetes infrastructure. Common causes include slow vector similarity search, oversized chunks, inefficient reranking, or overloaded embedding pipelines.
A frequent production check looks like:
resources: requests: cpu: "2" memory: "4Gi" limits: cpu: "4" memory: "8Gi" |
If resource requests are too low, pods may throttle under load even if they appear healthy.
2. Why does HPA not scale my LLM inference pods properly?
Many teams initially configure autoscaling based on CPU metrics, which often fails for GPU-heavy inference workloads. CPU usage may remain low while GPU memory and token queues become saturated.
Instead of:
metrics: - type: Resource resource: name: cpu |
Teams often move to queue-based or GPU utilization metrics using KEDA.
A common production symptom is:
"HPA shows 30% CPU, but inference latency is still 15 seconds."
3. Why is the vector database latency increasing after adding more documents?
This often happens when the vector index grows too quickly due to aggressive chunking strategies. Small chunk sizes combined with high overlap can create millions of redundant embeddings.
Typical example:
chunk_size = 200 overlap = 100 |
This increases search overhead significantly.
Common fixes include:
- Increasing chunk size
- Reducing overlap
- Rebuilding indexes periodically






