
1. Why We Use PVCs
Kubernetes was designed around the idea that compute should be disposable. Pods are routinely recreated during rolling deployments, autoscaling events, infrastructure maintenance, node failures, and cluster upgrades. That model works extremely well for stateless systems because failed workloads can simply be replaced without creating infrastructure complexity.
Stateful systems operate under very different constraints. A PostgreSQL database cannot lose its data because a Pod was rescheduled. A Prometheus server cannot discard historical metrics after a node restart. A production platform handling customer uploads cannot afford storage volatility during deployments or infrastructure failures.
This becomes one of the most important challenges in Kubernetes architecture.
How PVCs Solve the Problem
PersistentVolumeClaims (PVCs) exist to solve this challenge by separating application lifecycles from storage lifecycles. Even if Pods are recreated, rescheduled, or replaced, workloads can continue using the same persistent storage without losing application data.
Understanding PVCs properly is not just about learning Kubernetes objects.
It is about understanding how Kubernetes manages durable state in an environment where compute itself is intentionally temporary.
Kubernetes was never designed to make stateful systems simple.
It was designed to make them manageable at scale.
2. Why Kubernetes Needs Persistent Storage
Containers are temporary by nature, but application data usually is not.
Every container has a writable filesystem layer tied directly to the lifecycle of the container itself. If a Pod is recreated, Kubernetes may start the workload on an entirely different node with a completely new filesystem state.
This is one of the biggest architectural differences between traditional virtual machines and Kubernetes workloads. Virtual machines are generally treated as long-lived infrastructure, while Pods are replaceable scheduling units designed for orchestration flexibility and rapid recovery.
Containers Are Ephemeral by Design
Kubernetes also provides ephemeral storage mechanisms such as emptyDir, which survive only for the lifetime of the Pod. These are useful for cache data, temporary processing, scratch space, and short-lived application state, but they are not designed for durable workloads.
Another commonly misunderstood concept is ephemeral containers. These are temporary debugging containers used for troubleshooting running Pods and should not be confused with persistent application storage.
If an application needs data to survive Pod recreation, node failures, rolling deployments, infrastructure maintenance, or scheduling changes, the workload requires persistent storage.
This requirement is common for databases, monitoring systems, search platforms, CI/CD systems, analytics workloads, user-uploaded content, and machine learning pipelines where application reliability depends on durable data.
This is the fundamental storage problem Kubernetes persistent storage is designed to solve.
3. What PVCs Actually Solve
A PersistentVolumeClaim is not storage itself.
A PVC is a declarative request for storage.
That distinction matters operationally because it creates a clean separation between workloads and infrastructure.
Applications should not need to know:
- cloud disk identifiers
- NFS export paths
- SAN configuration details
- storage backend implementation logic
- infrastructure provisioning workflows
Instead, workloads simply declare:
- how much storage they need
- how the storage should be mounted
- what access behavior is expected
- That separation is what makes Kubernetes storage portable, scalable, and operationally manageable.which StorageClass should provision it
Kubernetes handles the rest.
This separation is one of the most important architectural ideas in Kubernetes storage:
- workloads consume storage
- infrastructure platforms manage storage
That abstraction allows the same application manifest to run consistently across AWS, Azure, GCP, on-premise datacenters, and enterprise storage systems without rewriting application-level deployment logic.
At runtime, Kubernetes introduces multiple layers between workloads and real infrastructure:
| Pod → PVC → PV → StorageClass → CSI Driver → Storage Backend |
Each layer exists for a reason.
The Pod consumes storage.
The PVC requests storage.
The PersistentVolume (PV) represents actual storage capacity.
The StorageClass defines provisioning policy.
The CSI driver communicates with the real storage platform and performs infrastructure operations such as provisioning, attachment, mounting, resizing, and deletion.
That separation is what makes Kubernetes storage portable, scalable, and operationally manageable.
4. How PVC Binding Actually Works
Understanding the PVC lifecycle from the control plane perspective makes Kubernetes storage behavior significantly easier to reason about.
The process begins when a workload or engineer creates a PersistentVolumeClaim.
Example:
| apiVersion: v1 kind: PersistentVolumeClaim metadata: name: app-data namespace: apps spec: accessModes: - ReadWriteOnce storageClassName: gp3-general resources: requests: storage: 20Gi |
At this stage, the claim usually enters the Pending state.
The Kubernetes Persistent Volume Controller continuously watches for unbound claims. Kubernetes then attempts to locate a compatible PersistentVolume that satisfies the requested requirements.
Matching is not based on size alone. Kubernetes also evaluates:
- access modes
- StorageClass
- volume mode
- selectors
- compatibility constraints
If a matching PV already exists, Kubernetes binds the claim directly to that volume.
If no compatible PV exists, Kubernetes may provision storage dynamically using the configured StorageClass. This is the operational model used in most modern Kubernetes platforms such as Amazon EKS, Google GKE, and Azure AKS.
This is where Kubernetes transitions from orchestration into infrastructure automation.
The StorageClass references a CSI provisioner, and the CSI driver communicates with the real storage backend. Depending on the environment, the driver may:
- create an AWS EBS volume
- provision an Azure Disk
- allocate a GCP Persistent Disk
- provision Ceph storage
- create NFS-backed storage
Once storage is created successfully, Kubernetes creates or updates the PersistentVolume object and binds it to the PVC in a one-to-one relationship.
The claim transitions from:
Pending → Bound
When a Pod references that PVC, Kubernetes schedules the Pod onto a node and the kubelet mounts the volume into the container filesystem.
That mounted path becomes the only location the application should treat as durable storage.
Everything outside the mounted path should be considered temporary.
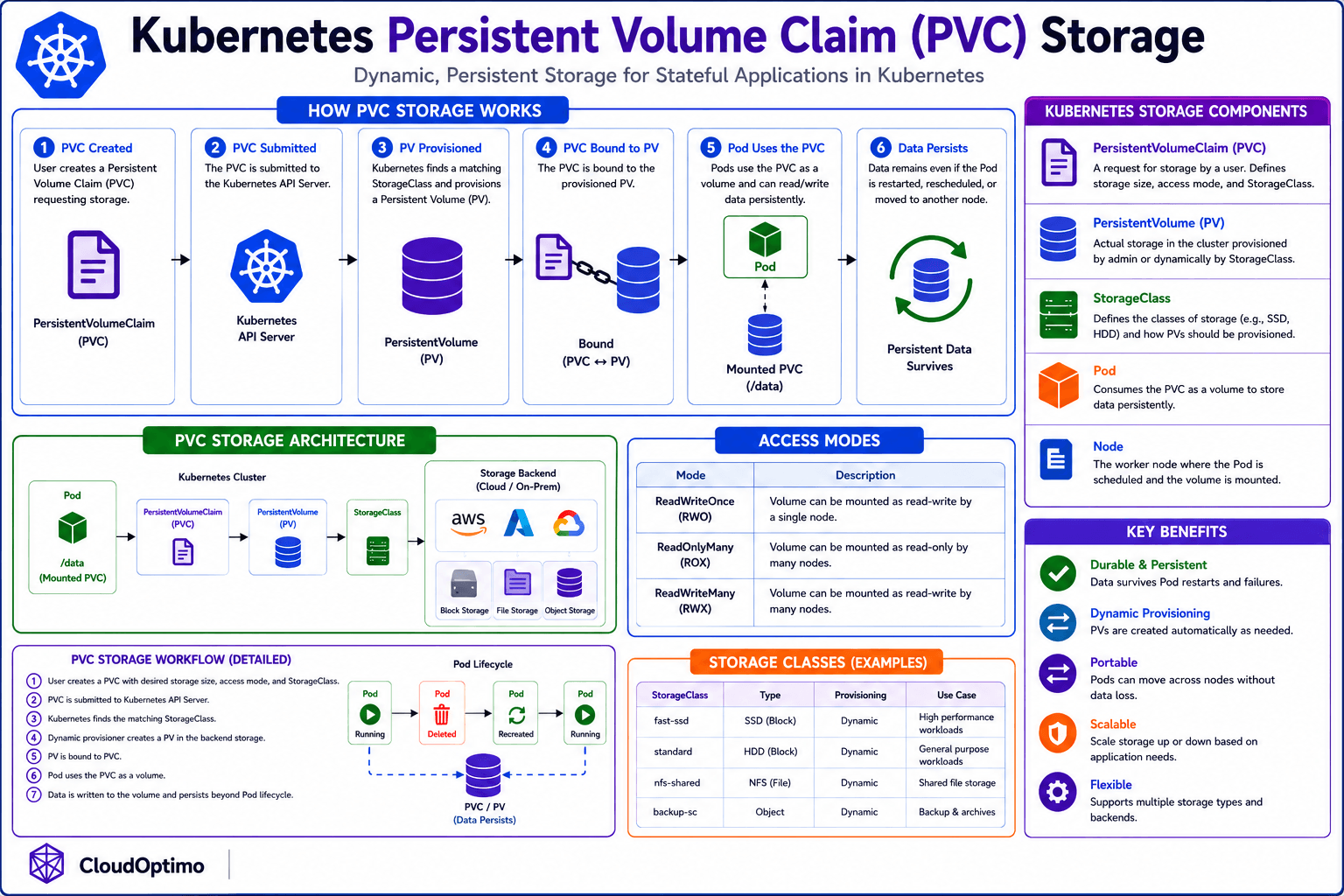
5. StorageClasses and Dynamic Provisioning
StorageClasses are where platform engineering decisions become operational policy.
A StorageClass controls:
- how storage is provisioned
- which backend is used
- reclaim behavior
- filesystem type
- expansion support
- topology-aware scheduling behavior
Example:
| apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: gp3-general provisioner: ebs.csi.aws.com parameters: type: gp3 fsType: xfs reclaimPolicy: Delete allowVolumeExpansion: true volumeBindingMode: WaitForFirstConsumer |
One of the most operationally important settings here is:
volumeBindingMode: WaitForFirstConsumer
Without this setting, Kubernetes may provision a zonal disk before scheduling decisions are finalized.
That is one of the most common causes of cross-zone attachment failures in production clusters.
With WaitForFirstConsumer, Kubernetes delays provisioning until scheduling decisions are known, allowing topology constraints, affinity rules, and availability zone placement to align correctly.
For zonal block storage systems, this is usually the safest production default.
Dynamic provisioning itself fundamentally changed Kubernetes operations.
Before dynamic provisioning became common, infrastructure teams often had to manually create storage volumes ahead of time. That model created coordination overhead and slowed down platform scalability.
Dynamic provisioning transformed storage into a self-service workflow.
That shift is one of the reasons Kubernetes became operationally viable for large-scale platform engineering.
6. PVCs in Stateful Workloads and StatefulSets
Why Stateful Workloads Need Dedicated PVCs
Kubernetes handles stateless workloads extremely well because stateless applications are designed to be replaceable.
Stateful systems behave very differently.
A database cannot suddenly attach to a different disk without consequences. A monitoring platform cannot afford inconsistent metrics storage during Pod rescheduling. Distributed systems require stable identities and predictable storage ownership to maintain consistency across replicas.
A Deployment mounting a single PVC may appear to work correctly when running one replica, but problems usually begin during scaling events. Most cloud block storage systems support read-write attachment from only a single node at a time. If multiple replicas attempt to use the same PVC incorrectly, Kubernetes can encounter multi-attach failures, scheduling conflicts, filesystem corruption risks, and inconsistent application state.
The issue is fundamentally architectural because Deployments are designed for interchangeable workloads, while stateful systems require stable identities and persistent storage relationships.
How StatefulSets Manage Persistent Storage
This distinction is exactly why Kubernetes introduced StatefulSets.
StatefulSets assign every replica its own dedicated PVC. Even if a Pod is recreated or rescheduled onto another node, Kubernetes preserves the relationship between the workload and its storage. This allows applications to retain stable data ownership, predictable startup behavior, and persistent network identities across failures and infrastructure changes.
StatefulSets also provide ordered deployment and scaling behavior, which becomes extremely important for databases, distributed systems, and clustered applications where startup sequencing and storage ownership must remain consistent.
This is why StatefulSets are commonly used for PostgreSQL, Prometheus, Kafka, Elasticsearch, ZooKeeper, and other distributed systems where durable storage consistency is critical.
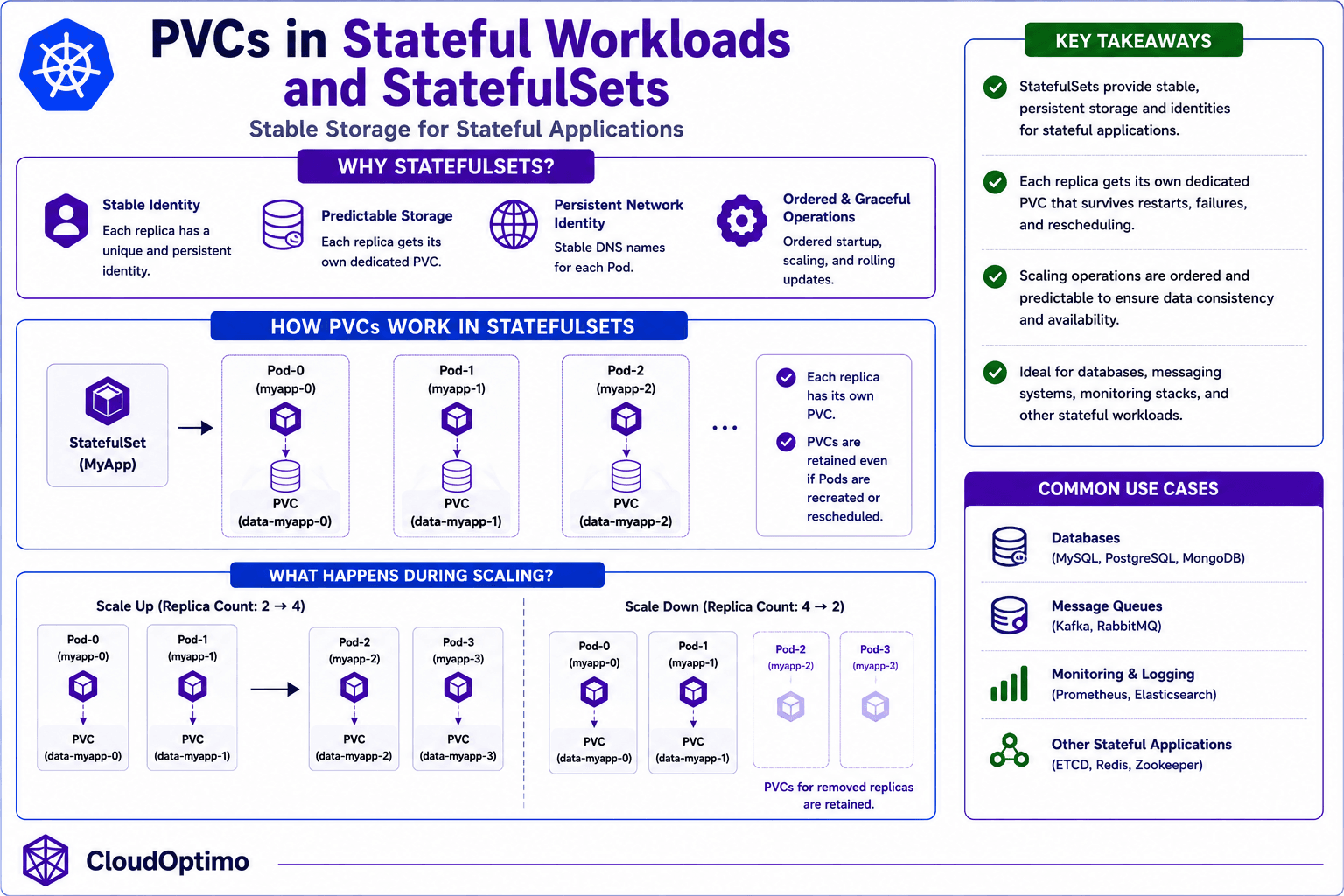
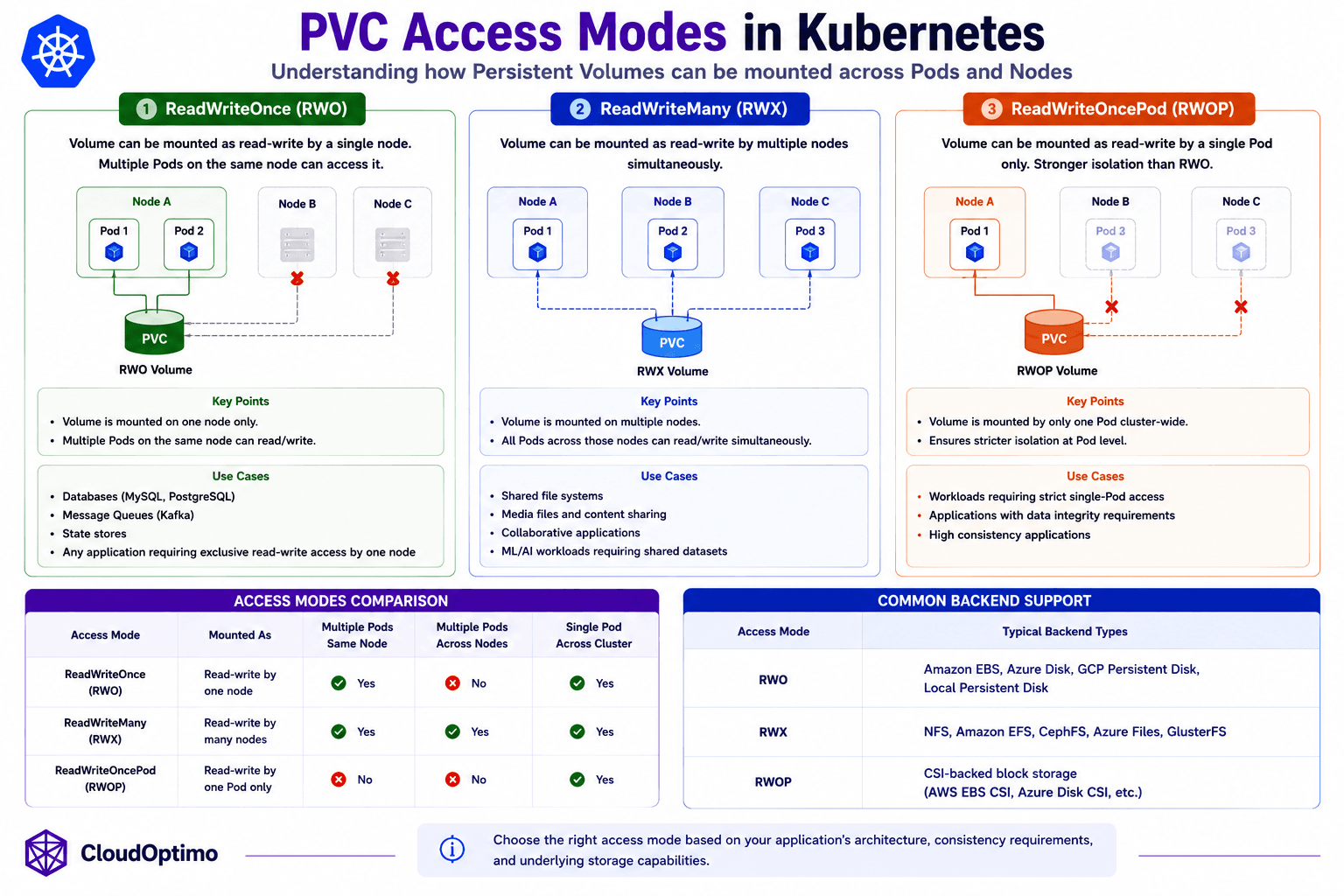
7. PVC Access Modes in Kubernetes
PVC access modes define how a Persistent Volume can be mounted across Pods and nodes inside a Kubernetes cluster.
Choosing the correct access mode is extremely important because it directly affects workload scheduling, scaling behavior, storage attachment rules, and application reliability.
One of the most misunderstood concepts in Kubernetes storage is ReadWriteOnce (RWO). Many engineers assume it means only one Pod can use a volume. In reality, it means the volume can only be mounted as read-write by a single node. Multiple Pods running on the same node may still access the same volume simultaneously.
ReadWriteMany (RWX) allows multiple nodes to mount the same volume at the same time. This behavior is commonly required for shared filesystems and collaborative workloads. Technologies such as NFS, Amazon EFS, CephFS, and Azure Files are commonly used for these scenarios. Most cloud block storage systems do not support RWX natively because block devices are generally designed for single-node attachment semantics.
Kubernetes also supports ReadWriteOncePod (RWOP), which provides stricter single-Pod write guarantees for CSI-backed storage requiring tighter isolation controls.
8. Storage Lifecycle Management
Persistent storage is not just about provisioning disks.
It is also about managing the storage lifecycle safely in production environments.
One of the most important lifecycle configurations is the reclaim policy, which determines what happens to the underlying storage after a PVC is deleted.
Reclaim Policy | Behavior |
| Delete | Kubernetes automatically removes the underlying storage asset after the PVC is deleted |
| Retain | The underlying storage remains available for manual recovery, investigation, or cleanup |
This Reclaim Policy setting is extremely important in production systems. Accidentally deleting a PVC backed by a Delete reclaim policy can permanently remove the underlying cloud disk and its data.
Kubernetes also includes protection mechanisms to prevent accidental removal of in-use storage. If a Pod is actively using a PVC, Kubernetes postpones deletion and keeps protection finalizers attached until the volume is no longer mounted by any workload.
Another critical operational capability is volume expansion. If the associated StorageClass enables:
allowVolumeExpansion: true
a PVC can be resized by increasing its requested storage value. This provides a significantly safer operational path than attempting emergency storage migrations during production incidents or unexpected traffic growth.
Security and Performance Considerations
Persistent storage introduces security and performance responsibilities that many teams underestimate.
From a security perspective, platform teams must consider filesystem ownership, encrypted volumes, RBAC permissions, snapshot access control, CSI driver credentials, and workload isolation policies. Kubernetes commonly uses fsGroup to ensure containers can properly access mounted filesystems with the correct permissions.
From a performance perspective, storage selection directly affects workload reliability and application behavior. Important considerations include IOPS limits, throughput constraints, SSD versus HDD behavior, network-attached storage overhead, and latency-sensitive workload requirements.
Choosing the wrong storage backend often becomes a hidden production bottleneck long before teams realize storage is the root cause.
9. Troubleshooting PVC Problems in Production
Storage problems in Kubernetes should always be investigated from the infrastructure layer first before debugging the application itself.
In many production incidents, the application is only exposing symptoms while the actual issue exists in storage provisioning, scheduling, volume attachment, filesystem permissions, or backend infrastructure behavior.
Start With Kubernetes Events and Storage Objects
The first step in troubleshooting should always be validating Kubernetes storage objects, cluster events, and volume attachment state.
Useful commands include:
| kubectl get storageclass kubectl get pvc -A kubectl get pv kubectl describe pvc app-data -n apps kubectl describe pod <pod-name> -n apps kubectl get events -A --sort-by=.lastTimestamp kubectl get volumeattachments.storage.k8s.io |
These commands help identify provisioning failures, attachment problems, scheduling conflicts, backend storage errors, and PVC binding issues before deeper application debugging begins.
Common PVC Failure Patterns
Most PVC-related production failures are operational rather than application-level.
Provisioning problems are commonly caused by incorrect StorageClass names, missing CSI drivers, incompatible access modes, or unavailable backend storage capacity.
Scheduling-related issues frequently involve topology conflicts, incorrect availability zone placement, missing WaitForFirstConsumer, or node affinity mismatches that prevent workloads from attaching to the correct storage backend.
Volume mount failures are often caused by filesystem ownership issues, missing fsGroup configuration, stale attachments, or multi-attach conflicts created by incorrect scaling behavior.
These problems are especially common in stateful systems where workloads depend heavily on stable storage attachment semantics.
Application-Level Storage Mistakes
In many production incidents, the storage platform itself is functioning correctly while the application uses the storage incorrectly.
Common mistakes include writing data outside the mounted volume path, mounting storage into the wrong directory, accidentally storing data inside temporary container filesystems, or making incorrect assumptions about shared-write behavior across replicas.
One of the most misleading production symptoms is apparent “data loss” after Pod recreation. In reality, the PVC often remains healthy while the application was writing data into a non-persistent container path instead of the mounted volume.
Understanding this distinction is extremely important because Kubernetes storage problems are not always infrastructure failures. Sometimes the issue is simply that the application never used persistent storage correctly in the first place.
10. Production Guidance
Running PVC-backed workloads reliably in production requires more than simply attaching storage to a Pod. Storage behavior must be designed intentionally because scheduling decisions, topology constraints, reclaim policies, and recovery expectations directly affect workload stability.
Storage Configuration and Scheduling
StorageClasses should always be configured explicitly instead of relying on cluster defaults. Explicit configuration prevents workloads from accidentally landing on incorrect storage tiers and makes infrastructure behavior far more predictable across environments.
For zonal block storage systems, WaitForFirstConsumer should be used to ensure topology-aware provisioning aligns correctly with scheduling decisions. Without it, Kubernetes may provision storage in an availability zone that does not match the eventual workload placement.
Stateful workloads should generally use StatefulSets instead of Deployments because databases, monitoring platforms, and distributed systems require stable identities and predictable storage ownership across Pod recreation events.
Reclaim policies should also be configured intentionally. Recovery expectations should determine whether storage is automatically deleted after PVC removal or retained for manual recovery and investigation.
Data Protection and Recovery
A PVC is not a backup strategy.
Persistent storage protects workloads from Pod recreation and rescheduling events, but it does not protect against accidental deletion, corruption, ransomware, application bugs, or operator mistakes.
Snapshots and backups should always exist independently from the running volume itself. Production-grade recovery planning should include snapshot automation, backup validation, restore testing, and documented recovery procedures before failures occur.
Monitoring and Storage Observability
Storage failures are often gradual before they become catastrophic.
Teams should continuously monitor free space, attach latency, disk saturation, filesystem usage, IOPS exhaustion, and mount failures because storage degradation frequently appears long before workloads begin failing.
In large-scale Kubernetes environments, proactive storage observability is just as important as CPU and memory monitoring because stateful workload failures are often rooted in underlying storage behavior rather than application logic alone.






