
The Silent Failure That Costs You Hours of GPU Time
Picture this: your platform team deploys a distributed PyTorch training job requiring 64 GPUs across eight nodes. Pods start running. The monitoring dashboard shows green. Six hours later, you check the training logs and find zero progress.
Here is what actually happened. The default Kubernetes scheduler evaluated each pod independently. Workers 0 through 5 landed on available GPU nodes, while workers 6 and 7 remained pending because the cluster lacked sufficient GPU capacity. The training framework requires all eight workers to synchronize at a network barrier before a single forward pass can execute. As a result, the six scheduled workers sat idle, consuming expensive GPU resources and blocking other queued jobs while waiting for two pods that never started.
This is a common failure mode when applying microservices-oriented scheduling behavior to tightly coupled distributed workloads. The scheduler has no native concept of workload-level membership, so placing six of eight workers is treated as a successful scheduling outcome even though the distributed application cannot make progress.
Current Kubernetes enhancement proposals targeting v1.35 and v1.36 introduce early workload-aware scheduling primitives, including the Workload and PodGroup APIs, to explore group-aware scheduling for distributed workloads.
What Is Workload-Aware Scheduling in Kubernetes?
Workload-Aware Scheduling (WAS) in Kubernetes is a scheduling paradigm where the scheduler reads the collective shape, constraints, and lifecycle policies of an entire application group before making any placement decisions, rather than evaluating each pod in isolation.
At its core, WAS enables the scheduler to consider workload-level constraints in addition to individual Pod requirements. Instead of evaluating pods only one at a time, the scheduler evaluates whether the cluster can satisfy the collective resource and topology requirements of the full group. If it cannot, no pods are placed, and cluster resources remain available for workloads that can actually run.
In Kubernetes v1.35 and v1.36, WAS is being implemented through two new alpha primitives: the Workload API (a static policy template) and the PodGroup API (the runtime scheduling unit). The proposed native Kubernetes Workload API is distinct from the Workload resource used by Kueue, despite the similar naming.
Why the Default Scheduler Breaks Down for Distributed Workloads
The Kubernetes scheduler was built for independent, long-running microservices where scheduling any subset is better than none. Distributed workloads operate on fundamentally different logic. They consist of interdependent pods that often need to start together to establish communication channels (NCCL, MPI, ZooKeeper quorum), may require topology-aware placement for acceptable latency, and cannot make progress if critical participants are missing or misplaced.
Against these requirements, the default scheduler produces three recurring failure patterns.
Resource fragmentation: The scheduler places early pods onto nodes without verifying whether the remaining pods can also be placed. A distributed database might receive three replicas on high-performance SSD nodes and two on spinning disk, degrading write performance cluster-wide.
Partial scheduling deadlocks: Jobs that only partially schedule hold allocated resources indefinitely. Placed workers consume GPU memory while blocking other queued workloads. The cluster appears busy but is accomplishing nothing.
Destructive incremental preemption: When a high-priority job needs resources, the scheduler evicts pods one at a time. Removing a single worker from a lower-priority distributed job invalidates the entire job, triggers a full restart, and frees only a fraction of the capacity needed.
Reality Check: What Exists Today vs. What Is Emerging
Before going deeper, it helps to separate stable Kubernetes functionality from what is actively being introduced as alpha.
| Capability | Status |
| Kubernetes Scheduling Framework (PreEnqueue, Filter, Score, Reserve, Permit, Bind) | Stable since v1.19 |
| Ecosystem gang scheduling via Volcano, Coscheduling plugin, Kueue | Production-ready for many teams today |
| Workload API (scheduling.k8s.io/v1alpha1, introduced v1.35) | Alpha, requires feature gate |
| PodGroup API (scheduling.k8s.io/v1alpha2, introduced v1.36) | Alpha, requires feature gate |
| Native gang scheduling via GangScheduling feature gate | Alpha in v1.36 |
| Topology-Aware Workload Scheduling (TAS) | Alpha in v1.36 |
| Workload-Aware Preemption (KEP-5710) | Alpha in v1.36 |
| Native Job controller integration (KEP-5547) | Alpha in v1.36 |
If you need gang scheduling in production today, established tools like Volcano and Kueue carry a real maturity advantage. The native Kubernetes workload-aware scheduling primitives represent an important long-term direction for distributed workload scheduling, but they require careful feature gate management and rigorous staging validation before production use.
The Scheduling Foundation and the Two-Object Model
The Kubernetes Scheduling Framework, stable since v1.19, exposed the scheduler's internal pipeline to plugins via well-defined extension points. This made group-aware scheduling possible without replacing kube-scheduler entirely.
Kubernetes v1.35 introduced the alpha Workload API, while subsequent alpha development in v1.36 expanded the workload-aware scheduling model around Workload and PodGroup resources. These capabilities remain under active development and may evolve between releases. Enabling them requires specific feature gates on both kube-apiserver and kube-scheduler, including GenericWorkload (Workload API), GangScheduling (PodGroup scheduling cycle), WorkloadAwarePreemption (KEP-5710, alpha), and TopologyAwareWorkloadScheduling (alpha). At the time of writing, all are disabled by default in Kubernetes v1.36.
Workload Object and PodGroup Object
The two-object model separates policy from runtime state deliberately.
The Workload object is a static policy template defining how a group of pods should be scheduled: placement strategy, topology requirements, and lifecycle rules. While the Job controller defines what containers run, the Workload resource defines how they are grouped and placed.
The PodGroup object represents the runtime grouping construct used by workload-aware scheduling features. carrying real-time status and conditions that the scheduler reads and updates each cycle.
Pods reference their group via spec.schedulingGroup.podGroupName, a reference that is immutable once set. If a pod references a PodGroup that does not yet exist, workload-aware scheduling logic can defer scheduling decisions until the required group metadata becomes available.
How PodGroup Gang Scheduling Works in Practice
The PodGroup spec.schedulingPolicy supports two modes. The basic policy enables best-effort grouping for observability.
The gang policy is designed to provide coordinated group admission semantics for distributed workloads. which is where the operational value for distributed workloads lives.
Here is a representative example using the alpha API:
# Alpha feature: requires GangScheduling feature gate apiVersion: scheduling.k8s.io/v1alpha2 kind: PodGroup metadata: name: spark-executor-group namespace: analytics-prod spec: schedulingPolicy: gang: minCount: 16 schedulingConstraints: topology: - key: topology.kubernetes.io/zone |
apiVersion: v1 kind: Pod metadata: name: spark-executor-0 namespace: analytics-prod spec: schedulingGroup: podGroupName: spark-executor-group containers: - name: spark-container image: apache/spark:3.5.0 resources: requests: cpu: "4" memory: "16Gi" |
The minCount: 16 field defines the minimum number of pods required for group admission. If the scheduler cannot satisfy the group's admission requirements within the configured waiting period, the workload can be requeued and any temporary reservations released.
The Three-Phase Scheduling Lifecycle
With GangScheduling enabled, the kube-scheduler coordinates placement through three phases.
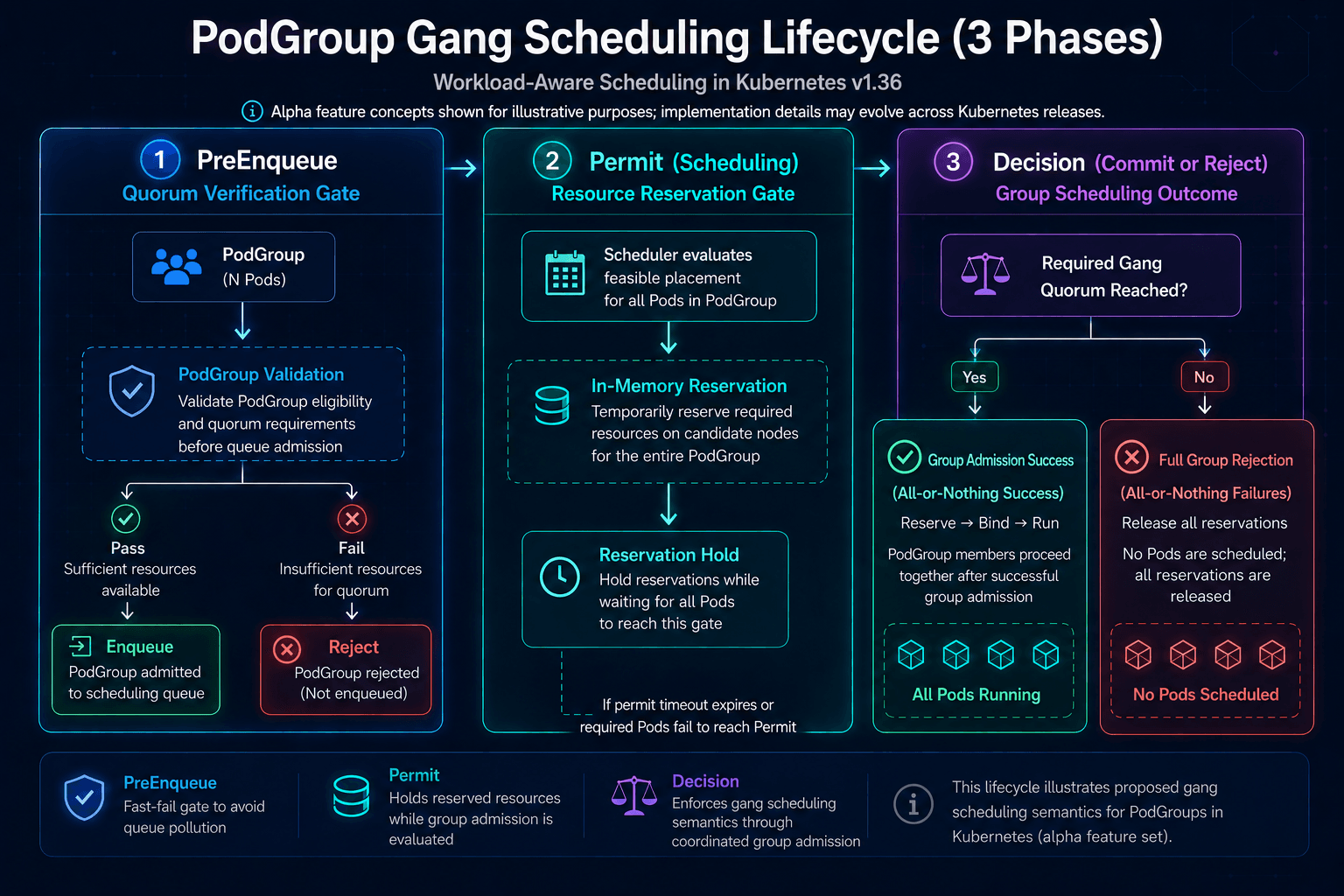
Phase 1: PreEnqueue Verification. Before workload members enter the active scheduling queue, workload-aware scheduling plugins validate PodGroup readiness and admission requirements. preventing incomplete workloads from flooding the queue.
Phase 2: Group Evaluation and Resource Reservation. Once quorum is confirmed, the group's pods enter the active queue sorted deterministically to prevent race conditions. The scheduler evaluates scheduling decisions using PodGroup-level context rather than considering each pod completely independently. Successfully placed pods are held at the Permit gate, with temporary resource reservations maintained through the scheduling cycle while admission decisions are evaluated. while the remaining pods are evaluated.
Phase 3: Group Admission or Requeue. If placements are found for at least minCount pods before the permit timeout expires, the scheduler proceeds with binding the admitted PodGroup members. If the admission requirements cannot be satisfied before the permit timeout expires, the workload may be requeued and temporary reservations released. This helps reduce resource fragmentation caused by partially admitted distributed workloads.
Traditional Scheduling vs. Workload-Aware Scheduling
The table below captures where the two models diverge most meaningfully for distributed workloads.
| Architectural Dimension | Traditional Scheduling | Workload-Aware Scheduling (Alpha, v1.36) |
| Unit of Evaluation | Single, independent Pod | Pod-level scheduling informed by PodGroup and Workload-level constraints |
| Placement Goal | Maximize node spreading, individual resource fit | Coordinated group admission and topology-aware placement |
| Resource Reservation | Sequential; binds nodes step-by-step | Scheduler-assisted group reservation through Permit-based coordination |
| Primary Failure Mode | Resource fragmentation, partial scheduling deadlocks | Higher scheduling latency under heavy queue load |
| Preemption Model | Localized, pod-by-pod eviction | Group-level, workload-aware (KEP-5710, alpha) |
| Cluster Status | Default behavior in all Kubernetes versions | Opt-in via feature gates in v1.35 and v1.36 |
Three Production Scenarios Where WAS Helps Most
1. Large-Scale AI/ML Distributed Training
Distributed training on PyTorch or TensorFlow requires all workers to complete a collective all-reduce operation before each gradient update. A single missing worker stalls the entire run.
With GangScheduling enabled, platform teams configure PodGroups sized to the exact worker count. Combined with GPU node pools labeled by interconnect topology (NVLink, InfiniBand), this approach can help ensure training runs either start with all workers co-located on the correct hardware, or do not start at all, keeping GPU capacity available for jobs that can actually use it. In practice, this can meaningfully reduce the idle GPU time that partial scheduling typically produces.
2. Apache Spark on Kubernetes
Spark's driver-executor model is particularly vulnerable to partial scheduling. If the cluster runs out of capacity mid-executor-spawn, the driver holds its resources and waits indefinitely while blocking other jobs.
With the WorkloadWithJob feature gate enabled (KEP-5547, alpha), the Job controller automatically generates a Workload and PodGroup, injects spec.schedulingGroup references onto every executor pod, and sets the Job as owner for clean garbage collection on completion. No manual PodGroup wiring is required.
3. HPC and MPI Scientific Computing
MPI jobs are among the most topology-sensitive workloads on Kubernetes. Cross-availability-zone placement can render an MPI job effectively non-functional even when all pods show a running status.
Topology-Aware Workload Scheduling (TAS, alpha in v1.36) extends the PodGroup cycle with a three-phase algorithm: it groups candidate nodes by a topology key (such as topology.kubernetes.io/rack), scores each domain using NodeResourcesFit with MostAllocated bin-packing, then admits the PodGroup into the highest-scoring eligible topology domain. If no single domain satisfies minCount, the PodGroup is marked unschedulable rather than silently placing workers across racks.
Group-Aware Preemption: Reducing Priority Conflicts
Standard preemption in a distributed environment is often counterproductive. Evicting one worker from a lower-priority gang job invalidates the entire job and triggers a full restart, freeing only a fraction of the resources the incoming workload actually needs.
Workload-Aware Preemption (KEP-5710, alpha in v1.36) explores workload-level preemption policies for PodGroups. PodGroup Priority sets a single priority value that overrides individual pod priorities within the group, giving the scheduler a unified preemption signal. PodGroup Disruption Mode dictates whether pods can be preempted individually or only as an all-or-nothing unit.
The goal is to make preemption decisions using workload-level context, helping reduce the disruption caused by pod-by-pod preemption for distributed workloads.
Independent Pod Scheduling vs. PodGroups: Capabilities at a Glance
| Capability | Independent Pod Scheduling | PodGroups with Gang Policy (Alpha, v1.36) |
| Core API Resource | v1.Pod | scheduling.k8s.io/v1alpha2.PodGroup |
| Scheduling Decision | Non-atomic; bindings written immediately | Coordinated group admission after quorum requirements are satisfied |
| Quorum Enforcement | None; replicas start as scheduled | Admission is gated by PodGroup readiness and quorum requirements |
| Timeout Handling | Pods remain pending indefinitely | Workload may be requeued after permit timeout and temporary reservations released |
| Topology Constraints | Individual pod affinity and spread rules | PodGroup-aware topology placement policies (alpha) |
| Preemption Behavior | Individual workers evicted at random | Managed via group disruption modes (alpha) |
Platform Engineering Benefits: What You Can Expect
With feature gates enabled and appropriate staging validation, WAS may provide several operational benefits for distributed workloads.
Reduced GPU idle waste. Gang scheduling can reduce situations where partially scheduled workloads consume GPU resources without making useful progress.
More predictable batch runtimes. Co-locating workers within low-latency topology domains reduces the network variance that makes training job durations inconsistent run over run.
Cleaner multi-tenant preemption. With KEP-5710, high-priority workloads can preempt more cleanly. Workload-level preemption policies aim to reduce cluster churn caused by pod-by-pod eviction decisions.
Engineering Reality Check: What Actually Works in Production Today
Before committing to native WAS primitives, it helps to be clear-eyed about the current landscape.
Native alpha primitives (v1.36) carry real risk. Breaking API changes are possible between releases. Group-level evaluation increases control plane overhead, so monitor scheduler CPU during high-load periods. Maintain a dedicated staging environment that mirrors production before any rollout.
Kueue is a production-ready Kubernetes-native queuing system with capabilities such as hierarchical resource quotas and fair-share scheduling. It manages when jobs enter the scheduling queue but does not replace the scheduler's placement logic, making it a complement to native WAS rather than a substitute.
Volcano is a mature CNCF batch system with queue weights, Dominant Resource Fairness, and job-dependency graphs. Fully production-ready for HPC and deep learning today. The trade-off is that Volcano replaces kube-scheduler entirely, which can delay access to core Kubernetes scheduling improvements and adds operational complexity for heterogeneous clusters.
Apache YuniKorn offers strong hierarchical queue management and dynamic resource reservation. Its Scheduling Framework plugin mode is deprecated (removal in v1.9), so production use requires standalone mode, bypassing the default scheduler.
For heterogeneous clusters mixing microservices and batch workloads, tracking the native WAS direction makes sense. For teams focused primarily on HPC or large-scale training, Volcano's maturity is a meaningful practical advantage today.
Trade-Offs and Adoption Challenges
Control plane overhead. Group-level evaluation is more expensive than scheduling pods individually. In high-churn clusters, this can degrade scheduler throughput. The opportunistic batching optimization in v1.35, which reuses node feasibility calculations for pods with identical scheduling requirements, helps, but control plane sizing deserves attention as adoption grows.
Reduced placement flexibility. Strict gang constraints can leave jobs pending even when aggregate cluster capacity exists. A job requiring 16 GPUs within a single rack stays unschedulable if each rack holds only 8 GPUs, regardless of how many GPUs are available cluster-wide. Node pool configurations must align with expected workload profiles.
Autoscaler alignment is an important operational consideration. A permit timeout shorter than node provision time can create a loop where workload admission fails just as new nodes become available.
Autoscaler tuning should be validated against your cloud provider, node provisioning characteristics, and scheduler configuration. Appropriate settings vary significantly across managed Kubernetes platforms, self-managed clusters, GPU environments, and different autoscaler implementations.
Also align permitWaitingTimeSeconds with expected node provisioning times in your environment and validate the behavior under realistic scale-out scenarios before production rollout.
Frequently Asked Questions (FAQs)
- When should my team consider PodGroups?
Consider PodGroups when running tightly coupled distributed jobs where partial scheduling causes deadlocks or significant resource waste: distributed training, fixed-parallelism Spark jobs, MPI workloads. Idle pods waiting for peers, or GPU utilization showing active but no training output, are the clearest diagnostic signals.
- Do I need to create PodGroups manually?
Not always. With the WorkloadWithJob feature gate enabled in v1.36 (alpha, KEP-5547), the Job controller automatically generates the Workload and PodGroup for fixed, indexed Jobs where parallelism equals completions. For other workload types, you create the PodGroup manually and reference it via spec.schedulingGroup.podGroupName in each pod's spec.
- Is gang scheduling always the right policy for AI workloads?
For synchronous distributed training, in most cases, yes. Many distributed training frameworks require all workers to participate before useful progress can be made, and a missing worker can stall or significantly degrade the training run. For workloads with dynamic executor allocation, such as certain Spark configurations, the basic PodGroup policy often offers better flexibility with less scheduling overhead.
- What are the most common production pitfalls?
The permit timeout and autoscaler timing mismatch is the most frequent silent failure. The second is node pool misconfiguration where topology or gang constraints cannot be satisfied by any single pool, leaving jobs permanently pending. Validate both scenarios explicitly in staging before enabling WAS features on a production cluster.






