
The shift from capital expenditure to operational expenditure has fundamentally redefined the financial landscape of modern technology organizations. As cloud environments scale, the "on-demand" pricing model, once celebrated for its agility, has increasingly become a source of financial friction for enterprises with established, predictable workloads. By 2026, cloud financial management, or FinOps, has matured from a reactive cost-cutting exercise into a proactive strategy focused on maximizing business value per dollar spent. Central to this evolution is the sophisticated orchestration of commitment-based discounts Reserved Instances, Savings Plans, and Spot Instances. While vendor marketing often highlights maximum potential discounts, the reality of production environments requires a more nuanced understanding of flexibility, utilization risk, and the "effective savings" achieved across AWS, Azure, and Google Cloud Platform (GCP).
The FinOps Paradox and the Shift Toward Rate Optimization
To understand the current state of cloud pricing, one must first acknowledge the Jevons Paradox in the context of infrastructure: as the efficiency of a resource increases, the consumption of that resource tends to rise rather than fall. When FinOps teams successfully optimize infrastructure, they do not simply reduce the bill; they unlock the ability for engineering teams to run more workloads, build more complex systems, and accelerate time-to-market. This transition from "Defensive FinOps" (cutting waste) to "Offensive FinOps" (investing for growth) is driven by rate optimization i.e the practice of reducing the per-unit cost of compute capacity.
Cloud cost is fundamentally a product of usage multiplied by rate. While usage optimization focuses on rightsizing and eliminating idle resources, rate optimization targets the price paid for each unit of capacity through contractual commitments. The challenge for the modern architect lies in the fact that these pricing models are not mutually exclusive but must be layered into a coherent, multi-cloud strategy that balances the need for maximum savings with the requirement for architectural agility.
AWS Commitment Architectures: The Primary Lever
Amazon Web Services (AWS) remains the most complex and robust ecosystem for rate optimization, offering a hierarchy of discount models that cater to varying degrees of predictability and risk. By 2026, the strategy for AWS spend has converged on a layered model that prioritizes Savings Plans for flexibility while retaining Reserved Instances for specific capacity requirements.
Reserved Instances: The Traditional Foundation
AWS Reserved Instances (RIs) have evolved since their inception in 2009. They represent a commitment to a specific instance configuration in exchange for a discounted hourly rate. Despite the rise of Savings Plans, RIs remain a vital tool for organizations requiring high-performance, stable baselines where capacity assurance is critical.
| RI Category | Scope of Flexibility | Marketplace Eligibility | Primary Advantage |
| Standard RI | Lowest; locked to instance family | Yes | Highest discount ceiling (~75%) |
| Convertible RI | Moderate; exchangeable across families | No | Architectural future-proofing |
The mechanism of an RI is essentially a billing trigger. When a running instance matches the attributes of a purchased RI such as instance type, region, platform, and tenancy the discounted rate is automatically applied. However, a significant architectural distinction exists between Zonal and Regional RIs. Zonal RIs provide a capacity reservation in a specific Availability Zone (AZ), ensuring that the requested capacity is available during times of peak demand or regional stress.Regional RIs do not guarantee capacity but offer "Instance Size Flexibility," allowing the discount to float across different sizes within the same family (e.g., an m5.xlarge RI can cover two m5.large instances).
A unique feature of Standard RIs is the AWS Reserved Instance Marketplace, which allows organizations to sell their unused reservations to other AWS customers. This provides a rare exit strategy for a fixed-term commitment, though it is subject to a 12% service fee and requires the RI to have been held for at least 30 days.
Savings Plans: The Flexibility Standard
Introduced in 2019, Savings Plans (SPs) moved the commitment from specific instance types to a consistent hourly spend in dollars (e.g., $10/hour). This shifted the burden of management from the engineering team to the billing engine.
| Savings Plan Type | Services Covered | Flexibility Scope |
| Compute Savings Plan | EC2, Fargate, Lambda | Any region, family, OS, or tenancy |
| EC2 Instance Savings Plan | EC2 only | Single family within a single region |
| SageMaker Savings Plan | SageMaker | Various SageMaker instance types |
Compute Savings Plans offer the greatest degree of freedom, allowing organizations to migrate from EC2 to Fargate or Lambda, or move workloads across regions, without losing their discount.The discount ceiling for Compute SPs is approximately 66%, identical to Convertible RIs. EC2 Instance Savings Plans offer deeper discounts (up to 72%) but are more rigid, mimicking the behavior of Standard RIs while retaining some size flexibility.
A critical operational nuance of Savings Plans is the 7-day return window. After purchase, a customer has exactly seven days to cancel or reduce the commitment. Beyond this point, the contract is immutable and non-transferable.This makes accurate forecasting essential, as "unused spend" in a Savings Plan is lost immediately and cannot be recovered via a marketplace.
Spot Instances: Managing the Interruption Frontier
Spot Instances represent AWS’s excess, unused capacity and are offered at discounts of up to 90% off the on-demand rate. Unlike RIs or SPs, Spot is not a commitment but a market-based pricing model where the price fluctuates based on supply and demand.
The primary risk associated with Spot is preemption. AWS can terminate a Spot instance with a two-minute warning if it needs the capacity for on-demand or reserved customers. By 2026, AWS has introduced more granular tools to manage this risk, including "Spot Interruption Metrics" in the EC2 Capacity Manager and "Spot Placement Scores," which help architects identify the Availability Zones and instance families with the lowest likelihood of interruption.
Interruption frequency is a pivotal data point for architecting fault-tolerant systems. While the average interruption rate across all regions is historically below 5%, specific, high-demand instance types can see much higher preemption rates.
| Interruption Frequency Bucket | Percentage of Instance Types |
| Low Interruptions (<5%) | 35.71% |
| Moderate (5-20%) | 23.81% |
| High Interruptions (>20%) | 40.48% |
Successful Spot strategies utilize "Capacity-Optimized" allocation strategies, which automatically select instances from the most stable capacity pools. For organizations running GKE or EKS, tools like "Karpenter" or "Ocean" can orchestrate these shifts dynamically, moving workloads to newer Spot pools or falling back to on-demand capacity when Spot is unavailable.
Azure Commitment Models: Licensing and Regional Constraints
Microsoft Azure’s approach to commitments mirrors AWS in many respects but is deeply integrated with the Microsoft enterprise software ecosystem.
Azure Reserved VM Instances (RIs)
Azure RIs offer discounts up to 72% for a three-year term.A defining characteristic of Azure’s model is its focus on regional lock-in. An Azure Reservation is typically tied to a specific VM series and region.However, Azure provides "Instance Size Flexibility," which allows the discount to float across different VM sizes within the same family and region.
| Feature | Azure Reservation |
| Max Discount | 72% (90% with Spot) |
| Commitment Term | 1 or 3 Years |
| Cancellation Policy | 12% termination fee; $50k annual limit |
| Licensing Benefit | Stackable with Azure Hybrid Benefit |
The Azure Hybrid Benefit is a significant differentiator. It allows organizations to repurpose their existing Windows Server and SQL Server on-premises licenses for cloud VMs, which can lead to a combined discount of up to 80% when paired with RIs.
Azure Savings Plan for Compute
Launched as a direct response to AWS Savings Plans, the Azure Savings Plan for Compute is a spend-based model ($/hour) that covers VMs, AKS, App Service, and Functions.The discount ceiling for Azure Savings Plans is lower than RIs, capped at approximately 65%.
A major "gotcha" in the Azure ecosystem is the rigidity of the Savings Plan contract. Unlike Azure RIs, which can be cancelled for a fee, Azure Savings Plans have a "zero cancellation" policy. Organizations are legally bound to pay the hourly commitment for the full term, regardless of usage.This makes the "under-commitment" strategy even more critical in Azure than in AWS.
Google Cloud Platform: Automation and Intelligence
Google Cloud (GCP) has historically taken a more automated approach to discounts, seeking to reduce the operational burden on the customer.
Committed Use Discounts (CUDs)
GCP offers two distinct types of CUDs:
- Resource-Based CUDs: These require a commitment to a specific amount of vCPU and memory in a single region. They offer the deepest discounts—up to 55% for standard machines and 70% for memory-optimized types.
- Spend-Based (Flexible) CUDs: These are committed at the billing account level and provide flexibility across regions and services, including GKE and Cloud Run. The discounts are lower, reaching approximately 46% for a three-year term.
Sustained Use Discounts (SUDs)
A unique feature of GCP is the Sustained Use Discount. These are automatic, usage-based discounts applied to Compute Engine resources that run for more than 25% of a billing month. SUDs require no upfront commitment and act as a "safety net," rewarding long-running VMs with a discount of up to 30%.
GCP Spot VMs
GCP Spot VMs offer discounts between 60% and 91% compared to standard rates. One key advantage of GCP Spot is the lack of a 24-hour maximum runtime, which was a limitation of the older "preemptible" model. GCP Spot VMs can run indefinitely until they are preempted, though they receive a shorter termination notice (30 seconds) compared to AWS (2 minutes).
Multi-Cloud Comparison and Arbitrage
For the multi-cloud organization, understanding the equivalent services across providers is essential for creating a unified FinOps governance model.
| Feature | AWS Equivalent | Azure Equivalent | GCP Equivalent |
| Spend Commitment | Compute Savings Plan | Savings Plan for Compute | Flexible (Spend) CUD |
| Resource Commitment | Standard RI | Reserved VM Instance | Resource-based CUD |
| Preemptible VM | Spot Instance | Spot Virtual Machine | Spot VM |
| Auto Discount | N/A | N/A | Sustained Use Discount |
| Termination Fee | Marketplace Resale (12%) | 12% Penalty (Capped) | None (Locked-in) |
Architecting for multi-cloud commitment management involves several risks, notably the "Egress Fee Trap." While organizations may attempt to move workloads to the cloud provider offering the lowest Spot price at a given moment, the cost of moving data out of the source cloud can easily negate any compute savings. Furthermore, volume discounts often require a high degree of spend concentration; splitting spend across three clouds may result in lower overall discounts than consolidating on one.
The Effective Savings Rate: The Only Metric That Matters
In the world of FinOps, the "Discount Rate" is a vanity metric. A 75% discount is irrelevant if it only applies to 10% of your fleet, or if your utilization of that discount is only 50%. To measure true ROI, organizations must track the Effective Savings Rate (ESR).
ESR is a single, standardized KPI that combines coverage, utilization, and the actual discount rate into one figure that represents the total percentage saved over the on-demand list price.
Calculating ESR
The formula for ESR is:
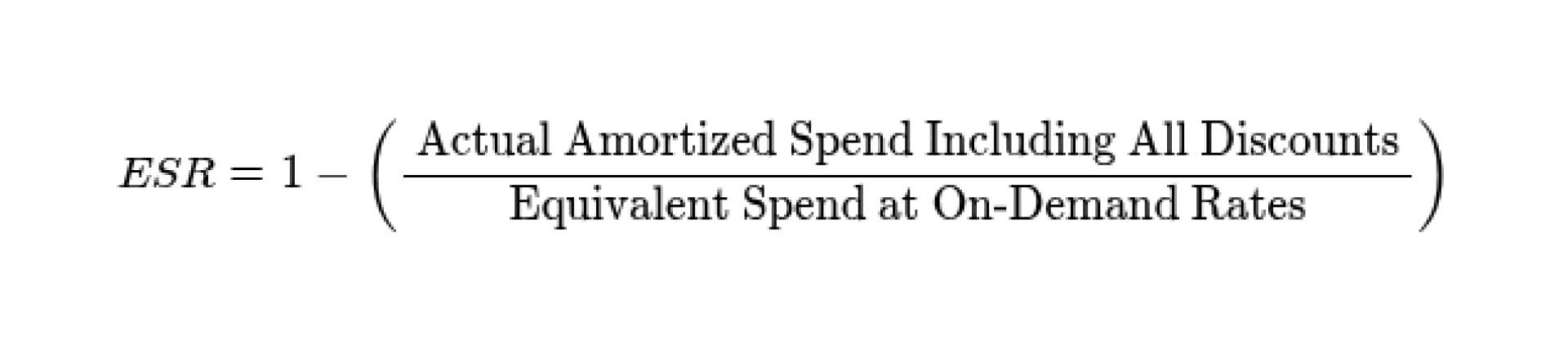
This metric is powerful because it highlights the cost of "shelfware"commitments that were purchased but not used.For instance, consider two companies:
- Company A: Has a 90% coverage rate but only 70% utilization of those commitments.
- Company B: Has a 60% coverage rate but 100% utilization.
Company B may actually have a higher ESR and a more efficient cloud operation because they are not paying for "air".
The ESR Benchmark and Impact
| Performance Level | ESR Range | Business Outcome (per $10M annual spend) |
| Crawl (Manual) | 10% - 18% | ~$1.5M Saved |
| Walk (Monthly Review) | 18% - 30% | ~$2.5M Saved |
| Run (Autonomous) | 35% - 50% | ~$4.5M Saved |
Moving from a 20% to a 35% ESR for a company with $100M in revenue and $10M in cloud spend translates to a 1.5% improvement in total operating margin.
Architectural Hybrid Strategy: The Waterfall Model
The most effective FinOps teams do not choose between RIs, Savings Plans, and Spot. They layer them in a "Waterfall" or "Tiered" strategy that matches the volatility profile of their workloads.
Tier 1: The Predictable Floor (3-Year RIs/Resource CUDs)
This layer covers the core, steady-state workloads—databases, mainframe emulators, and core infrastructure services—that are guaranteed to run 24/7/365. By committing to three-year terms for these specific resources, organizations capture the highest possible discount ceiling (70%+). This is where rigidity is an asset, not a liability.
Tier 2: The Evolving Baseline (1-Year Savings Plans/Spend CUDs)
This layer accounts for the application servers and microservices that form the baseline of the production environment but may be subject to architectural changes or regional shifts. Using one-year Savings Plans provides a "rolling" commitment that can be adjusted every 12 months as technology stacks evolve (e.g., migrating from x86 to ARM/Graviton).
Tier 3: Fault-Tolerant Clusters (Spot Instances)
Non-critical environments (Dev/Staging), CI/CD runners, and large-scale batch processing (data lakes, ML training) are moved exclusively to Spot. Automation tools are used to ensure that if a Spot pool is depleted, the workload can either pause or temporarily fail over to a higher-cost tier without breaking the business process.
Tier 4: The Burst Buffer (On-Demand)
The final 10–15% of the capacity remains on-demand. This is the most expensive layer, but it prevents the "over-commitment trap." It is cheaper to pay full price for a few hours of seasonal peak capacity than to commit to a year of capacity that is only needed 5% of the time.
Realistic Scenario: Optimizing a $100,000 Monthly Compute Spend
Consider a technology company with a monthly AWS compute bill of $100,000, currently operating on 95% on-demand instances. The environment consists of 200 EC2 instances across three regions, with a mix of production web servers, background workers, and development environments.
Step 1: Rightsizing and Cleanup (Savings: $22,000)
Before purchasing any commitments, the team performs a 14-day utilization audit. They find that 40% of their instances are running at less than 10% CPU utilization. By resizing these instances (e.g., moving from m5.2xlarge to m5.large) and deleting "zombie" resources like unattached EBS volumes and abandoned snapshots, the monthly baseline spend is reduced to $78,000.
Step 2: Locking in the Production Baseline (Savings: $18,000)
The team identifies that their production floor—the absolute minimum compute required even at 3:00 AM—is $40,000. They purchase a 3-year Compute Savings Plan for $20,000/month of that spend. This reduces the cost of that layer by ~45%, bringing the bill down to $60,000.
Step 3: Moving Non-Prod to Spot (Savings: $10,000)
The company implements automated start/stop schedules for development environments (running only 9 AM–6 PM) and migrates their stateless CI/CD runners to Spot Instances. This reduces the cost of the dev/test layer by 80%.
Final Outcome:
The total monthly spend is reduced from $100,000 to $50,000, achieving a 50% cost reduction without any degradation in performance or reliability. The Effective Savings Rate (ESR) has improved from 0% to approximately 40%.
Common Mistakes in Rate Optimization
Even with the right tools, several structural mistakes can derail a cloud optimization program.
1. The "Locking in Waste" Error
Purchasing a 3-year reservation for an oversized instance is the most common mistake. Once the reservation is made, the organization has no incentive to rightsize that instance, effectively "cementing" inefficiency into the budget.The rule is simple: Rightsize first, commit second.
2. Treating Discounts as Guaranteed Savings
A 70% discount is a potential saving, not a guarantee. If the utilization of that reservation drops below 50%, the organization is actually paying more than if they had stayed on-demand. This is the "Utilization vs. Discount Paradox".
3. Ignoring the "Use it or Lose it" Mechanism
Savings Plans and RIs are calculated on an hourly (or in some cases, per-second) basis. If you commit to $10/hour and only use $8 of compute between 2:00 PM and 3:00 PM, that $2 of commitment is gone forever. It does not roll over to the next hour.
4. Running Mission-Critical, Stateful Apps on Spot
While Spot offers the highest savings, using it for a primary database or a single-instance legacy application is an architectural failure. Spot is only for "disposable" or highly redundant infrastructure.
Best Practices for Continuous FinOps Governance
To sustain these savings, FinOps must be an ongoing practice, not a one-off audit.
- Implement Unit Economics: Move beyond total spend and track "Cost per Transaction" or "Cost per Customer." This helps distinguish between "good spend" (scaling for growth) and "bad spend" (inefficiency).
- Decentralize Accountability: Ensure that engineering teams have visibility into the cost of their architectural choices. Use "Showback" or "Chargeback" reports to map cloud costs back to specific product teams.
- Adopt Autonomous Management: In 2026, the complexity of managing thousands of commitments across multiple clouds exceeds human capacity. Leading organizations use ADM platforms to rebalance their commitment portfolios hourly, ensuring that they are always maximizing their ESR while minimizing lock-in risk.
- Monthly Optimization Reviews: Conduct a "look-back" every 30 days to analyze anomalies, review commitment expiration dates, and adjust forecasts based on the product roadmap.
Conclusion: The Path to Architectural Efficiency
The comparison between Reserved Instances, Savings Plans, and Spot is not a matter of which "saves more" in isolation, but which creates the most value when integrated into a mature architectural strategy. Reserved Instances provide the deep discounts required for a predictable baseline, Savings Plans offer the agility needed for modern, evolving stacks, and Spot Instances provide the extreme cost efficiency required for fault-tolerant scaling.
As cloud providers continue to innovate in their pricing models, the burden of optimization shifts from manual intervention to architectural design and algorithmic management. Organizations that master the Effective Savings Rate will not only see lower cloud bills but will gain a fundamental competitive advantage: the ability to reinvest those savings into the next generation of innovation. In the cloud-first era, financial efficiency is no longer a back-office function—it is a cornerstone of high-performance engineering.






