
1. Platform Positioning: Orchestrator vs Application Platform
Every organization that adopts containerized workloads eventually confronts the same foundational question: should we build a platform, or buy one? Kubernetes and OpenShift represent two distinct answers to that question and understanding the difference requires moving beyond feature lists to examine the role each system is designed to play.
1.1 What Kubernetes Actually Provides (CaaS Model)
Kubernetes is, at its core, a Container-as-a-Service (CaaS) orchestration engine. It schedules containers, manages cluster state, handles service discovery, enforces desired-state reconciliation, and ensures workload availability across a pool of compute resources.
What Kubernetes deliberately does not do is solve the entire application lifecycle. It provides primitives, not complete workflows. Capabilities such as CI/CD pipelines, container image registries, centralized logging, and developer-facing interfaces are intentionally left outside the core available through the ecosystem, but never prescribed by the platform itself.
This is not an oversight. It is a design philosophy. Kubernetes is built to be a composable foundation, and that composability is precisely what makes it powerful and demanding. Platform teams that choose Kubernetes accept the responsibility of assembling and maintaining a coherent operational stack from a wide field of options.
1.2 What OpenShift Adds on Top (PaaS Layer)
OpenShift extends Kubernetes into a full Platform-as-a-Service (PaaS). Rather than leaving platform teams to source and integrate individual components, OpenShift ships as a cohesive system, one where infrastructure management, deployment workflows, security controls, and operational tooling are pre-integrated and designed to function together from day one.
The practical effect of this is a significant shift in emphasis: away from infrastructure assembly and toward application delivery. Teams using OpenShift spend less time evaluating and wiring together ecosystem tools, and more time running workloads on a platform that is already production-ready.
This does not mean OpenShift removes choice entirely, it means it has made those choices in advance, with enterprise operational requirements as the guiding constraint.
1.3 Opinionated vs Unopinionated Systems
The distinction between Kubernetes and OpenShift is, at a deeper level, philosophical.
Kubernetes is intentionally unopinionated. It defines extension points and provides APIs, but deliberately avoids enforcing defaults on networking models, observability stacks, image management, or deployment tooling. Organizations are free and expected to construct the platform that fits their needs.
OpenShift is equally intentionally opinionated. It standardizes these decisions by providing predefined configurations and tightly integrated components. Customization remains possible, but the platform is explicitly optimized for consistency, predictability, and supportability at enterprise scale.
Neither posture is inherently superior. The right choice depends on whether an organization needs maximum flexibility or minimal operational variance, a trade-off that reveals itself most clearly in how platform teams spend their time.
1.4 When Each Model Emerges in Organizations
The choice between these two platforms tends to reflect organizational maturity and operational priorities more than any purely technical consideration.
Kubernetes is typically the choice of organizations with established platform engineering practices teams that have the expertise to evaluate tooling, build internal developer platforms, and absorb the long-term maintenance burden of a self-assembled stack. The reward for that investment is deep control and the ability to optimize the platform precisely for their workload profile.
OpenShift is more commonly adopted in environments where standardization, compliance, and time-to-production take precedence over maximum configurability. Regulated industries, large enterprises with distributed teams, and organizations without a dedicated platform engineering function frequently find that OpenShift's pre-integrated model dramatically reduces the gap between "cluster running" and "platform ready."
2. Core Architecture and Control Plane Design
While Kubernetes forms the orchestration foundation that OpenShift is built on, the two platforms diverge significantly in how they approach cluster architecture, lifecycle management, and the operational model for platform components. These differences are not cosmetic; they have real consequences for how clusters are deployed, maintained, and extended over time.
2.1 Kubernetes Control Plane Components
A Kubernetes cluster is divided into two primary layers: the control plane, which governs cluster state and makes orchestration decisions, and the data plane (worker nodes), which executes application workloads.
The control plane itself is composed of several modular, loosely coupled components. The API Server serves as the single entry point for all cluster communication. etcd maintains the authoritative state of the cluster as a distributed key-value store. The Scheduler assigns workloads to nodes based on resource availability and policy constraints. The Controller Manager continuously reconciles the actual state of the cluster against the desired state.
This modular design gives operators considerable flexibility in how clusters are deployed and managed. Components can be configured independently, replaced where necessary, and scaled according to operational requirements. That flexibility, however, comes with the expectation that teams understand each layer and take responsibility for the full operational stack.
2.2 OpenShift Architecture: Operator-Driven Design
OpenShift builds on Kubernetes by adopting an Operator-centric architecture as a fundamental design principle rather than an optional pattern. In OpenShift, nearly every core platform function from networking and storage to authentication and cluster updates is managed by an Operator that encapsulates operational knowledge in software and continuously reconciles the system toward its desired state.
Two components are particularly central to this model. The Operator Lifecycle Manager (OLM) governs the installation, update, and dependency management of Operators across the cluster. The Cluster Version Operator (CVO) treats the entire cluster as a single versioned unit, managing upgrades in a coordinated, rollback-capable manner.
The effect is a transformation of cluster management: what would otherwise be a collection of manual operational tasks becomes an automated, declarative system that the platform manages on behalf of its operators.
2.3 Immutable Infrastructure and Cluster Lifecycle Management
One of the more consequential architectural distinctions in OpenShift is its approach to node lifecycle management. OpenShift enforces immutability at the node level through Red Hat Enterprise Linux CoreOS (RHCOS), an operating system purpose-built for containerized workloads.
Rather than updating individual packages or configuration files on running nodes, RHCOS nodes are updated via image-based deployments; entire node images are replaced atomically. This approach eliminates configuration drift, makes rollback reliable and predictable, and ensures a consistent runtime environment across every node in the cluster.
Kubernetes, by contrast, leaves node lifecycle management entirely to the user. The platform makes no assumptions about the underlying operating system or update mechanism, which preserves flexibility but requires platform teams to implement and enforce their own consistency guarantees.
2.4 Extensibility vs Managed Abstraction
Kubernetes prioritizes extensibility above almost everything else. Custom Resource Definitions (CRDs) allow teams to extend the API to manage virtually any resource, making Kubernetes a viable foundation not just for application workloads but for infrastructure automation, database operators, and custom control planes.
OpenShift fully supports this extensibility model, but its architectural emphasis lies elsewhere: in managed abstraction. Core platform components are tightly integrated and lifecycle-managed through Operators, which reduces variability, limits unexpected interactions between components, and ensures that the full platform stack remains supportable within Red Hat's enterprise support model.
For most organizations, this is not a limitation, it is the point. The trade-off between maximum extensibility and operational predictability is, ultimately, another dimension of the same choice introduced in Section 1.
3. Security and Compliance Models
Security is frequently the deciding factor in platform selection, particularly in regulated industries where compliance obligations are non-negotiable and audit requirements are continuous. Kubernetes and OpenShift take fundamentally different approaches to security; one requires security to be deliberately constructed; the other enforces it from the start.
3.1 Kubernetes Native Security Capabilities
Kubernetes provides a solid set of foundational security primitives. Role-Based Access Control (RBAC) governs who can perform what actions against which API resources. Pod Security Admission the successor to the deprecated Pod Security Policies enforces workload isolation standards at the namespace level. Network Policies control traffic flows between workloads, allowing teams to implement micro segmentation within the cluster.
These capabilities are genuinely powerful, but they share a critical characteristic: they are all opt-in. By default, Kubernetes favors usability and broad compatibility over strict security enforcement. Clusters without explicit hardening are significantly more permissive than most production environments should be, and the burden of reaching a secure baseline falls entirely on platform teams.
3.2 OpenShift Security Defaults
OpenShift adopts a secure-by-default posture that inverts this dynamic. Rather than requiring security to be layered on after the fact, OpenShift enforces strict controls from the moment a workload is admitted to the cluster.
The primary mechanism for this is Security Context Constraints (SCCs), an OpenShift-native control plane that governs what a container is permitted to do at runtime. Out of the box, SCCs prevent containers from running as root, restrict access to host namespaces and kernel capabilities, and assign randomized non-privileged user IDs to workloads that do not specify one. Developers encounter these controls immediately which, by design, ensures that insecure workload patterns are identified and corrected early rather than discovered during a security audit.
3.3 Policy Enforcement Models
For organizations that require fine-grained, custom governance rules across their clusters, Kubernetes integrates well with external policy engines such as OPA Gatekeeper and Kyverno. These tools allow platform teams to define admission control policies as code, enforce naming conventions, require specific labels, and reject workloads that do not meet organizational standards.
OpenShift supports both tools and the broader policy-as-code ecosystem, but its built-in controls reduce the need for additional policy layers in many common scenarios. Teams running OpenShift often find that SCCs and the platform's default admission controls cover the majority of their governance requirements without additional tooling, reserving external policy engines for organization-specific rules that go beyond what the platform provides natively.
3.4 Multi-Tenancy and Isolation Strategies
Multi-tenancy in Kubernetes is implemented through namespaces, which provide logical boundaries between teams or applications. Effective isolation, however, requires combining namespaces with RBAC, network policies, and resource quotas each configured deliberately and maintained consistently across the cluster.
OpenShift extends this model through Projects, which wrap Kubernetes namespaces with a higher-level abstraction that includes preconfigured isolation defaults, automatically applied network policies, and integrated access controls. A new Project in OpenShift is isolated by default; a new namespace in Kubernetes is not. For multi-tenant environments, this distinction has significant operational consequences and directly affects the risk surface of shared clusters.
3.5 Supply Chain Security and Image Governance
Modern platform security no longer stops at runtime. Software supply chain integrity ensuring that only verified, scanned, and signed images reach production has become a critical control domain in its own right.
In Kubernetes, supply chain security is addressed through external tooling: image scanning solutions, signing frameworks such as Sigstore and Cosign, and admission webhooks that enforce image provenance at deploy time. These integrations are well-supported by the ecosystem and offer considerable flexibility, but they require deliberate assembly and ongoing maintenance.
OpenShift integrates image security more directly into the platform. Image Streams provide a layer of abstraction over container registries that enables change detection, automated rebuilds, and promotion workflows across environments. The integrated registry supports image signing and enforces trusted image policies at the cluster level, reducing the amount of external tooling required to achieve a governed software supply chain.
3.6 Compliance Readiness
For organizations operating in regulated environments healthcare, financial services, government compliance readiness is not a post-deployment concern. It must be built into the platform from the outset.
OpenShift includes a Compliance Operator that continuously evaluates cluster configuration against established regulatory frameworks, including CIS Benchmarks and NIST controls, and provides structured remediation guidance for identified gaps. This transforms compliance from a periodic audit exercise into an ongoing, automated process embedded in normal cluster operations.
Achieving equivalent compliance coverage in Kubernetes requires assembling and integrating multiple third-party tools, building custom audit workflows, and maintaining the logic that maps cluster configuration to specific regulatory requirements, a non-trivial investment that often underestimates the ongoing maintenance burden once deployed.
4. Operational Complexity and Cluster Management
If architecture defines how a platform is built, operations define how it behaves over time. The long-term cost of a platform is rarely determined by its initial setup it is determined by the cumulative effort required to maintain, scale, and evolve it under real production conditions over months and years.
Kubernetes and OpenShift diverge significantly in how they distribute that operational burden. One exposes operational complexity as a field of choices; the other absorbs much of it into the platform itself.
4.1 Cluster Installation and Upgrades
Installing a Kubernetes cluster is not a standardized process. Organizations can bootstrap clusters using tools like kubeadm, provision them through managed cloud services (such as EKS, AKS, or GKE), or automate the process entirely through Infrastructure-as-Code frameworks. Each path carries its own assumptions about networking, node provisioning, and security posture and none produces an identical result. Upgrades compound this complexity: control plane components, worker nodes, CNI plugins, and storage drivers must all be upgraded in a carefully coordinated sequence to avoid version skew, API deprecations, and unplanned downtime.
OpenShift takes a fundamentally different approach. Installation is handled through an opinionated, guided installer that produces a fully configured, production-ready cluster. Upgrades are managed as a single orchestrated operation through the Cluster Version Operator (CVO), which treats the entire cluster as one versioned unit. Platform teams do not coordinate individual component upgrades; they advance the cluster through a tested, signed upgrade channel. The coordination overhead that Kubernetes leaves to the operator is absorbed into OpenShift's own lifecycle machinery.
4.2 Day-2 Operations: Scaling, Patching, and Recovery
Day-2 operations are where the practical gap between the two platforms becomes most apparent.
In Kubernetes, scaling the cluster, patching nodes, rotating certificates, and recovering from node failures require a combination of external tooling and documented operational runbooks. The platform provides the APIs and the mechanisms (like the Cluster Autoscaler), but it does not prescribe how these capabilities should be assembled into reliable automated workflows. Platform teams design and own those workflows, which means they also own the failure modes.
OpenShift embeds these workflows natively. Node updates, certificate rotations, cluster self-healing, and scaling operations are continuously managed by Operators reconciling system state against a declared target. The result is not the elimination of operational work, but a meaningful shift in its character—from execution and coordination to supervision and exception handling.
4.3 Observability and Monitoring Integration
Observability is where the difference between a platform that is assembled and one that is integrated becomes especially concrete.
- Kubernetes exposes metrics endpoints compatible with Prometheus, logs consumable by Fluentd or Loki, and traces suitable for OpenTelemetry but it prescribes none of them. The monitoring stack must be selected, installed, configured, and maintained independently. Teams have full control, but carry full responsibility for producing a coherent observability layer.
- OpenShift ships with a pre-integrated, Prometheus-based monitoring stack configured by default. System-level metrics are collected immediately, curated dashboards are available from day one, and alerting rules for common failure conditions are preconfigured. This translates directly to a materially faster time-to-visibility.
4.4 Multi-Cluster and Fleet Management
At scale, managing a single cluster is never the final state. Organizations inevitably face the challenge of coordinating a fleet of clusters across multiple regions or cloud providers.
Kubernetes does not provide a native answer to fleet management. Organizations typically address this by layering in GitOps controllers (Flux, Argo CD) and cluster lifecycle tools (Cluster API). Assembling these into a coherent fleet management platform is a significant engineering investment.
OpenShift extends its operational model to the fleet level through Red Hat Advanced Cluster Management (RHACM), providing centralized visibility, policy enforcement, and lifecycle management. For enterprises managing tens or hundreds of clusters, this level of centralized control becomes an operational necessity.
5. Developer Experience and Application Lifecycle
Platform adoption does not succeed or fail at the infrastructure layer it succeeds or fails at the point where developers interact with it daily. Kubernetes provides low-level infrastructure control and expects teams to construct application workflows on top of it. OpenShift provides those workflows as a structured, first-class part of the platform.
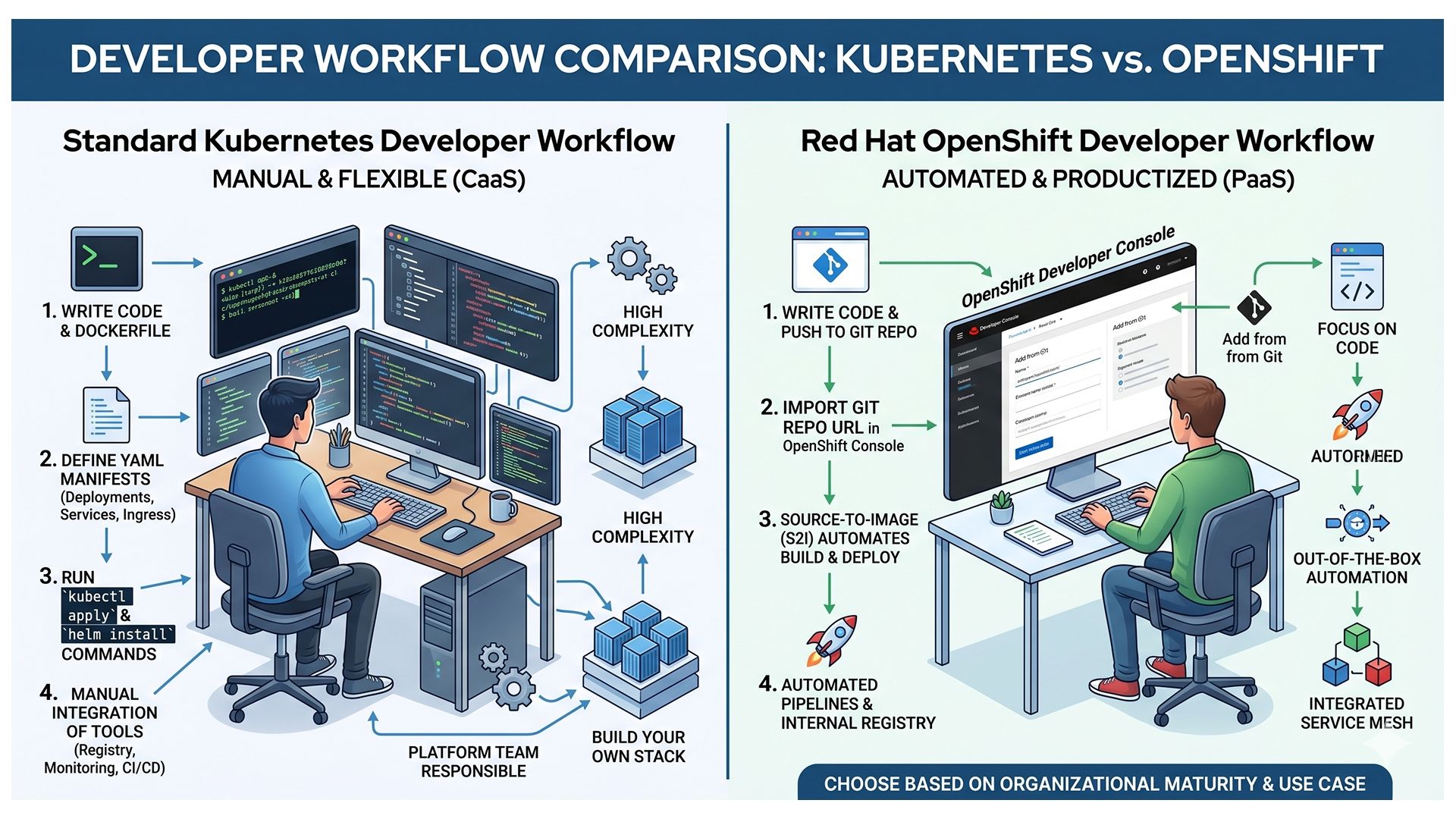 5.1 Kubernetes Developer Workflow
5.1 Kubernetes Developer Workflow
The standard Kubernetes developer workflow is built around the API and the command line. Developers interact with the cluster through kubectl, define workloads through YAML manifests, and package applications using Helm charts or Kustomize. CI/CD pipelines (Jenkins, GitHub Actions) are external systems requiring explicit integration.
The flexibility this model affords is genuine. Teams can design pipelines that precisely match their requirements. However, flexibility without organizational enforcement tends to produce fragmentation, inconsistent Helm chart quality, and a platform surface that is difficult to audit.
5.2 OpenShift Developer Console and Built-in Pipelines
OpenShift approaches developer experience by prioritizing abstraction over exposure. Its web console provides a dedicated Developer Perspective—a purpose-built interface where developers can deploy applications and monitor builds without touching a terminal.
The platform's Source-to-Image (S2I) capability extends this abstraction. Developers provide a Git repository URL; OpenShift detects the runtime, compiles the application, builds a container image, and deploys it automatically. Paired with OpenShift Pipelines (built on the Tekton framework), the application delivery workflow lives inside the platform rather than adjacent to it.
5.3 Internal Developer Platforms (IDPs) on Kubernetes
Organizations operating on vanilla Kubernetes frequently respond to its developer experience limitations by building Internal Developer Platforms (IDPs) using frameworks like Backstage.
These teams construct self-service portals that provide application templates and automated pipeline provisioning—essentially rebuilding the convenience layer that OpenShift delivers natively. The trade-off is one of control against cost: whether that cost is paid in vendor licensing or in sustained internal engineering time.
5.4 Abstraction vs Flexibility in Developer Workflows
Kubernetes surfaces infrastructure details directly to developers. That transparency is valuable for experienced practitioners but creates a steeper onboarding curve. OpenShift abstracts those details, accelerating onboarding and reducing cognitive load, but makes workflows that diverge from the platform's predefined patterns progressively harder to accommodate.
6. Workload Abstractions and Runtime Capabilities
Workload abstractions determine what the platform can run and how effectively it can do so.
6.1 Pods, Deployments, StatefulSets: Core Primitives
Kubernetes defines a composable set of workload primitives:
- Pods: The smallest deployable unit (one or more containers sharing a network and storage).
- Deployments: Managers for stateless applications, providing rollout strategies and scaling.
- StatefulSets: Managers for applications requiring stable network identities and persistent storage.
These primitives model behavior without prescribing implementation. OpenShift uses these exact same primitives natively; the distinction lies solely in how they are consumed (raw manifests vs. guided UI workflows).
6.2 Operators as an Application Abstraction Layer
For complex, stateful systems (databases, streaming platforms), basic primitives are insufficient. Operators emerge here as a crucial abstraction layer, extending the API to manage domain-specific lifecycle tasks (upgrades, backups, failovers) automatically.
In Kubernetes, Operators are an optional pattern adopted per-use-case. In OpenShift, they are the default mechanism for managing complex systems, heavily integrated through the built-in OperatorHub catalog.
6.3 Service Mesh and Advanced Networking
As applications decompose into distributed services, basic networking primitives become insufficient. Features like mutual TLS, traffic routing, and circuit breaking require a service mesh. In Kubernetes, this is delivered through separately maintained tools like Istio or Linkerd. OpenShift integrates these capabilities directly via OpenShift Service Mesh (a supported distribution of Istio), narrowing the capability gap but significantly reducing the integration and configuration overhead.
6.4 Storage Orchestration and Stateful Workloads
Kubernetes addresses storage through Persistent Volumes (PVs), Persistent Volume Claims (PVCs), and Storage Classes, decoupling the application from the storage provider. However, teams must still manage the underlying storage system's performance and replication. OpenShift builds on this by offering OpenShift Data Foundation (ODF), delivering software-defined storage for block, file, and object access directly within the cluster, tightly managed by Operators.
7. Workload Evolution I: Virtual Machines on Kubernetes
One of the most consequential shifts in modern infrastructure is the convergence of containerized and virtualized workloads. Organizations are recognizing that containers and VMs can coexist within a unified orchestration layer.
Traditional Virtualization vs Kubernetes-Native Virtualization
| Aspect | Traditional Virtualization | Kubernetes-Native Virtualization |
| Control Plane | Separate hypervisor-based control plane (e.g., VMware vCenter) | Unified control plane within Kubernetes |
| Workload Types | Primarily virtual machines | Virtual machines and containers managed together |
| Management Model | Imperative (manual operations via UI or scripts) | Declarative (defined through YAML and APIs) |
| Infrastructure Stack | Dedicated virtualization layer separate from container platforms | Virtualization integrated into the container orchestration layer |
| Provisioning | VM provisioning through hypervisor tools and templates | VM creation defined as Kubernetes resources and applied declaratively |
| Scaling | Manual or policy-based scaling at VM level | Automated scaling integrated with cluster scheduling and policies |
| Networking | Managed through hypervisor-specific networking constructs | Uses Kubernetes networking model and plugins |
| Storage | Attached via hypervisor-managed storage systems | Uses Kubernetes storage abstractions (PVs, PVCs, StorageClasses) |
| Automation | Script-driven or vendor-specific automation tools | Native automation through controllers and Operators |
| Observability | Separate monitoring systems for VMs and containers | Unified observability across VMs and containers |
| Multi-Environment Consistency | Often varies across on-prem and cloud environments | Consistent model across hybrid and multi-cloud deployments |
| Operational Model | Separate teams for virtualization and container platforms | Converged operations under a single platform team |
7.1 Introduction to KubeVirt
KubeVirt is the CNCF project that makes this convergence possible. It extends the Kubernetes API, allowing virtual machines to be defined, scheduled, and managed alongside containers. A VM in a KubeVirt cluster is scheduled by Kubernetes, connected to the cluster network, and described by a manifest. The operational model is unified even when the workload types are not.
7.2 Running Legacy Workloads Alongside Containers
Not every application can or should be containerized immediately. Applications tied to specific kernel versions, legacy middleware, or restrictive licensing can continue running as VMs via KubeVirt, while newer services are deployed as containers on the exact same cluster. This allows for incremental modernization without the cost of maintaining two entirely separate infrastructure stacks.
7.3 OpenShift Virtualization Capabilities
OpenShift bundles and extends KubeVirt into a production-grade feature called OpenShift Virtualization. VMs are treated as first-class workloads subject to the same RBAC policies and network segmentation as containers. OpenShift adds robust tooling for live migrations, storage hot-plugging, and VM lifecycle management, fully supported by Red Hat.
7.4 Migration from Traditional Hypervisors
Migrating from legacy hypervisors (like VMware vSphere) to Kubernetes-based virtualization is an operational paradigm shift. Tools like the Migration Toolkit for Virtualization (MTV) provide structured support for importing VMs.
Ultimately, this shift transforms VMs from individually maintained, long-lived pets into versioned, declarative objects governed by modern GitOps workflows. For organizations operating at scale, this represents a massive opportunity to unify infrastructure under a single control plane.
8. Workload Evolution II: AI/ML and GPU-Oriented Infrastructure
If the previous evolution of Kubernetes focused on supporting stateful workloads and virtual machines, the current shift is being driven by artificial intelligence. AI and machine learning workloads introduce fundamentally different requirements, particularly around hardware utilization, scheduling, and distributed execution.
These workloads are not simply “another application type.” They reshape how clusters are designed, especially in environments where GPUs, high-throughput networking, and large-scale data pipelines are involved.
8.1 GPU Scheduling and Resource Management
Kubernetes was originally designed to schedule CPU and memory resources. Supporting GPUs requires extending the platform to recognize and allocate specialized hardware.
This is typically achieved through device plugins, which allow nodes to advertise GPU resources to the scheduler. Workloads can then request GPUs in the same way they request CPU or memory.
However, operating GPU-enabled clusters introduces additional complexity. Ensuring compatibility between drivers, runtimes, and container images becomes critical. More advanced scenarios—such as sharing GPUs across multiple workloads or optimizing utilization for inference—require additional layers of configuration and control.
OpenShift supports the same underlying mechanisms but provides more structured integration for GPU workloads, particularly in environments where consistency and operational predictability are required.
8.2 Distributed Training Architectures
Modern AI models are rarely trained on a single node. Training workloads are distributed across multiple machines, often requiring tightly coordinated execution and high-performance networking.
In Kubernetes, this involves configuring specialized communication layers and using controllers designed for distributed workloads. These controllers manage job coordination, failure handling, and resource allocation across multiple nodes.
While powerful, this model requires careful setup and tuning. Network performance, storage throughput, and workload orchestration must all align to avoid bottlenecks.
OpenShift simplifies parts of this process by integrating validated configurations and supported workflows, reducing the amount of custom setup required to run distributed training reliably at scale.
8.3 Building AI Platforms on Kubernetes
Running individual AI workloads is only part of the challenge. Most organizations need a complete platform for model development, training, and deployment.
In Kubernetes, this typically involves assembling multiple tools into a cohesive system. Frameworks such as Kubeflow provide pipelines and workflow orchestration, while systems like Ray enable scalable execution of Python-based workloads.
These tools are powerful but require integration. Platform teams must design how data flows, how experiments are tracked, and how models move from training to production. The result is a highly customizable platform, but one that carries significant operational overhead.
8.4 OpenShift AI Capabilities and Enterprise ML Ops
OpenShift approaches this problem by providing a more integrated AI platform experience.
Capabilities for model development, pipeline orchestration, and deployment are packaged into the platform, allowing teams to move from experimentation to production with fewer integration steps. Notebook environments, pipeline tooling, and model serving are aligned with the platform’s existing security and networking controls.
This reduces the effort required to establish an enterprise-grade ML workflow, particularly in organizations where standardization and governance are critical.
9. Ecosystem, Tooling, and Extensibility
Both Kubernetes and OpenShift exist within the broader cloud-native ecosystem, but they interact with that ecosystem in fundamentally different ways. One prioritizes open-ended extensibility, while the other emphasizes curated integration.
This distinction shapes how platforms evolve over time and how much responsibility organizations take on when adopting new tools.
9.1 Kubernetes Open Ecosystem
Kubernetes operates as a foundation rather than a complete solution. To build a production platform, teams rely on a wide range of ecosystem tools.
Package management, deployment workflows, service mesh capabilities, and observability are typically implemented using independent projects. This allows organizations to select tools that best fit their requirements and replace them as needed.
The advantage is flexibility. The trade-off is the need to continuously evaluate, integrate, and maintain these components as part of the platform.
9.2 OpenShift Integrated Stack
OpenShift takes a different approach by curating and integrating many of these ecosystem tools into a unified platform.
Rather than requiring teams to assemble components individually, OpenShift provides pre-configured capabilities that are tested to work together. These integrations are managed through Operators, ensuring consistent lifecycle management across the stack.
This reduces integration effort and operational risk, particularly in environments where stability and supportability are priorities.
9.3 Vendor Lock-in vs Portability
The difference in ecosystem approach leads directly to the question of portability.
Kubernetes offers a high degree of portability at the infrastructure and tooling level. Applications built using standard APIs and open-source tools can be moved across environments with relatively few constraints, provided dependencies are managed carefully.
OpenShift maintains compatibility with Kubernetes APIs and container standards, so applications themselves remain portable. However, operational workflows often become aligned with platform-specific features. Moving away from the platform may require reworking these workflows rather than rewriting applications.
The distinction is less about code portability and more about operational dependency.
9.4 Managed Kubernetes vs OpenShift Offerings
The ecosystem discussion also extends to how these platforms are consumed.
Managed Kubernetes services handle control plane operations but leave most of the platform layer to the user. Teams are still responsible for selecting and managing the tools that run within the cluster.
Managed OpenShift offerings extend this responsibility further. In addition to infrastructure, the integrated platform components are also managed, providing a more complete operational model.
The difference lies in how much of the platform lifecycle is delegated versus retained internally.
10. Cost Structure and Total Cost of Ownership (TCO)
Cost comparisons between Kubernetes and OpenShift are often oversimplified. While Kubernetes is frequently described as “free” and OpenShift as “licensed,” this distinction captures only a small part of the total cost.
A more accurate comparison considers infrastructure spend, operational effort, and long-term scalability of the platform model.
10.1 Kubernetes: Infrastructure Cost vs Operational Overhead
Kubernetes itself is open-source and does not carry a licensing cost. Organizations primarily pay for the underlying infrastructure compute, storage, and network resources.
However, this model introduces significant operational overhead. Building and maintaining a production-ready platform requires specialized engineering effort. Integration, upgrades, security hardening, and observability all demand ongoing attention.
These costs are not always visible in initial estimates, but they scale with the complexity and size of the environment.
10.2 OpenShift: Licensing and Subscription Model
OpenShift follows a subscription-based model, typically priced per core or per vCPU. This represents a direct and predictable cost component.
In return, organizations receive an integrated platform with managed lifecycle operations, curated tooling, and enterprise support. The intent is to reduce the internal engineering effort required to operate the platform.
The financial trade-off is between paying upfront for a managed platform versus investing in internal capability.
10.3 The “Pricing Inversion” Explained
At smaller scales, Kubernetes often appears more cost-effective due to the absence of licensing fees. However, as environments grow, the operational burden increases.
Organizations frequently encounter a point where the cost of maintaining a self-managed platform—particularly in terms of engineering resources begins to exceed the cost of a licensed solution.
This shift is often described as a pricing inversion: initial savings are offset over time by operational complexity.
10.4 FinOps Considerations in 2026
Modern cost management extends beyond infrastructure totals to granular visibility and accountability.
Organizations increasingly need to attribute costs to specific workloads, teams, or business units. This requires aligning resource usage with financial reporting, enabling more accurate chargeback or showback models.
In Kubernetes environments, achieving this level of visibility typically involves integrating additional systems and correlating usage data with billing information.
OpenShift incorporates these capabilities more directly into the platform, simplifying cost attribution and enabling more consistent financial governance across multi-tenant environments.
11. Migration and Interoperability Considerations
In modern infrastructure, decisions are rarely permanent. Mergers, acquisitions, cost optimization drives, or shifts in IT strategy often require moving workloads between platforms. Because OpenShift is fundamentally built on Kubernetes, they share a common DNA. However, the operational layers built on top of them create unique friction points when moving in either direction.
11.1 Moving from Kubernetes to OpenShift
Migrating from standard Kubernetes to OpenShift is generally an "upward" migration. Because OpenShift is fully certified Kubernetes, standard Kubernetes API objects like Pods, Deployments, and Services will run on OpenShift natively.
The primary friction point developers encounter during this migration is OpenShift’s aggressive default security. Standard Kubernetes allows containers to run as the root user by default; OpenShift’s strict Security Context Constraints (SCCs) actively block this. Teams migrating workloads will often see immediate CrashLoopBackOff or permission errors until they either refactor their container images to run as non-root users or explicitly grant elevated privileges via SCCs.
11.2 Moving from OpenShift to Kubernetes
Migrating from OpenShift to standard Kubernetes (or a managed cloud service like EKS or GKE) is typically more complex. This is where the concept of "operational lock-in" becomes tangible.
While the core containers are portable, the supporting infrastructure is not. When you leave OpenShift, you lose its built-in CI/CD pipelines, integrated container registry, and proprietary routing layer. Platform teams must rapidly engineer replacements for these components using open-source alternatives (e.g., replacing OpenShift Pipelines with GitLab CI or Argo Workflows). The applications themselves will migrate smoothly, but the automated machinery used to deploy and monitor them must be completely rebuilt.
11.3 Translating Platform-Specific Resources
A successful migration requires translating platform-specific API resources. While many resources are identical, several critical components require direct translation:
- Networking: OpenShift relies heavily on Route objects to expose applications to the outside world. When moving to Kubernetes, these must be translated into standard Ingress resources or the modern Gateway API.
- Security Profiles: OpenShift's SCCs must be translated into Kubernetes Pod Security Admissions.
- Builds: OpenShift's proprietary BuildConfig and ImageStream resources (which power Source-to-Image) have no direct equivalent in standard Kubernetes and must be replaced by standard Dockerfiles and external CI pipelines.
OpenShift to Kubernetes: Resource Translation Reference
| OpenShift Concept | Kubernetes Equivalent | What It Represents | Key Differences |
| Route | Ingress / Gateway API | External access to services | Routes are simpler and tightly integrated in OpenShift; Kubernetes Ingress requires a controller, while Gateway API is more flexible but still evolving |
| Project | Namespace | Logical isolation of resources | OpenShift Projects include additional defaults (RBAC, quotas, policies) automatically applied; Kubernetes Namespaces are more minimal |
| ImageStream | Container Registry + Tags | Image lifecycle and tracking | ImageStreams track image changes and enable triggers; Kubernetes relies on external registries and CI/CD pipelines for similar behavior |
| Security Context Constraints (SCC) | Pod Security Admission + RBAC | Workload security policies | SCCs are OpenShift-specific and enforced by default; Kubernetes uses Pod Security Admission with a different model and requires explicit configuration |
| BuildConfig | CI/CD Pipelines (external tools) | Build and deployment automation | OpenShift supports source-to-image (S2I) builds natively; Kubernetes relies on external systems like Jenkins, GitHub Actions, or Argo |
| DeploymentConfig | Deployment | Application deployment controller | DeploymentConfig is OpenShift-specific and supports triggers; Kubernetes Deployments are more widely used and standardized |
| Service CA / Internal Certs | Cert Manager / External PKI | Internal TLS and certificate management | OpenShift auto-generates and manages internal certs; Kubernetes typically requires additional tools like cert-manager |
11.4 Hybrid and Multi-Cloud Strategies
Most enterprises today operate in hybrid or multi-cloud realities.
- With standard Kubernetes, achieving a consistent hybrid environment requires adopting a meta-control plane (like Google Anthos/GKE Enterprise or Azure Arc) to standardize the fragmented clusters running across on-premises servers and public clouds.
- OpenShift acts as its own multi-cloud equalizer. Because the OpenShift platform is identical whether it is deployed bare-metal in your basement, on AWS (ROSA), or on Azure (ARO), developers and operators experience the exact same interface, API, and tooling regardless of the underlying infrastructure. This makes OpenShift an exceptionally strong enabler of true multi-cloud portability.
12. Decision Framework: Choosing the Right Platform
Choosing between Kubernetes and OpenShift is not a question of which platform is superior. It is a question of fit between the platform's design philosophy and the organization's actual capabilities, constraints, and priorities. Both are valid approaches to running containerized infrastructure at scale. The difference lies in what each approach asks of the organization that adopts it.
12.1 Organizational Maturity and Skill Availability
The single most important factor in this decision is internal capability.
Kubernetes assumes a mature platform engineering function. Teams are expected to evaluate tooling, design integration patterns, establish operational standards, and own the platform's evolution indefinitely. For organizations with that capability, Kubernetes offers precisely the level of control that makes that investment worthwhile.
OpenShift reduces this requirement significantly. Organizations with limited platform engineering capacity, distributed teams without deep Kubernetes expertise, or leadership prioritizing faster adoption over maximum control will generally find that OpenShift's pre-integrated model delivers a production-ready platform without the equivalent staffing investment. The trade-off is straightforward: flexibility in exchange for reduced operational burden.
12.2 Regulatory and Compliance Requirements
In regulated industries, compliance is not a configuration concern, it is a first-order platform requirement.
Kubernetes can be hardened to meet strict regulatory standards, but doing so requires assembling dedicated tooling, maintaining audit workflows, and continuously validating configuration against evolving requirements. Compliance becomes a sustained engineering effort in its own right.
OpenShift embeds many of these controls by default. The built-in Compliance Operator, secure-by-default security posture, and tested integration patterns reduce both the initial effort to reach compliance and the ongoing cost of maintaining it. For organizations where regulatory alignment is a primary constraint, this difference is rarely marginal.
12.3 Scale and Workload Profile
The composition of an organization's workload portfolio matters as much as its scale.
Kubernetes is well-suited to environments running large-scale, homogeneous workloads where platform teams have the expertise to optimize infrastructure behavior precisely for their use case. The flexibility it offers is most valuable when there is sufficient engineering capacity to exercise it deliberately.
OpenShift aligns more naturally with mixed workload environments, modern stateless applications, stateful systems, legacy services being modernized, and potentially virtualized workloads all managed within a single platform. Where consistency and integrated management are more operationally valuable than granular customization, OpenShift's opinionated model is an asset rather than a constraint.
12.4 Long-Term Platform Strategy
At a strategic level, this decision reduces to a familiar question: build or buy.
Kubernetes provides a flexible, open foundation that organizations shape to their requirements. That flexibility is genuine and powerful, but it carries a long-term obligation: the platform must be continuously developed, maintained, and evolved by internal teams. The total cost of that investment is frequently underestimated at the point of adoption.
OpenShift offers a standardized, vendor-managed platform with defined support boundaries and a predictable upgrade lifecycle. It narrows the organization's degrees of freedom in exchange for reducing the engineering surface it must own.
The question worth asking is not which platform has more features, but which model aligns with where the organization intends to invest. The answer to that question more than any technical comparison is what should drive the decision.
13. Frequently Asked Questions
Q. What is the fundamental difference between Kubernetes and OpenShift?
Kubernetes is a container orchestration engine it provides the core primitives for scheduling workloads, managing cluster state, and handling service discovery. It is deliberately minimal, leaving networking models, observability stacks, CI/CD tooling, and security policies as open decisions for the platform team.
OpenShift is a complete platform built on top of Kubernetes. It does not simply add tools to the orchestration layer it integrates and manages those tools as a cohesive system, with predefined security defaults, an Operator-driven architecture, and a supported upgrade lifecycle. The difference is less about features and more about where operational responsibility sits: with the platform team in Kubernetes, and substantially with the platform itself in OpenShift.
Q. Can Kubernetes be made to do everything OpenShift does?
Yes in principle. Given sufficient time, tooling, and engineering capacity, a Kubernetes platform can be assembled that covers most of what OpenShift provides natively. Many large organizations have done exactly this.
The practical question is not capability but cost. Building and maintaining that platform requires sustained investment in integration, testing, and operational discipline. OpenShift represents a decision to purchase that investment rather than build it. Whether that trade-off is favorable depends entirely on what an organization's platform engineering team is sized and skilled to take on.
Q. When should an organization choose Kubernetes over OpenShift?
Kubernetes is the stronger choice when an organization has a mature platform engineering function, needs deep control over infrastructure design, and is prepared to own the long-term evolution of the platform. It suits teams running large-scale, performance-sensitive, or highly customized workloads where the flexibility to optimize every layer of the stack is genuinely valuable and where the staffing exists to exercise that flexibility responsibly.
Q. When does OpenShift make more sense?
OpenShift tends to be a better fit when standardization, compliance, and time-to-production carry more weight than maximum configurability. It is commonly preferred in regulated industries, large enterprises with distributed teams, and organizations that cannot dedicate a dedicated platform engineering team to assembling and maintaining a custom stack. If the goal is to run applications rather than to build a platform, OpenShift's pre-integrated model removes a significant category of work from the equation.
Q. Is OpenShift more secure than Kubernetes by default?
Yes out of the box, OpenShift enforces a significantly stricter security posture. Its Security Context Constraints prevent containers from running as root, restrict access to host resources, and assign non-privileged user IDs automatically. A freshly provisioned Kubernetes cluster, by contrast, applies permissive defaults that require deliberate hardening before they are appropriate for production.
It is important to note that Kubernetes can be configured to reach a comparable security level. The distinction is not capability, it is baseline behavior. OpenShift requires teams to justify exceptions to secure defaults; Kubernetes requires teams to construct those defaults in the first place.
Q. Are applications portable between Kubernetes and OpenShift?
Most containerized application workloads are portable. Standard Kubernetes API resources Deployments, Services, ConfigMaps, StatefulSets run on both platforms without modification.
The friction in migration is rarely at the application layer. It surfaces in the surrounding platform constructs: OpenShift's Route objects, BuildConfigs, and ImageStreams do not have direct Kubernetes equivalents and must be translated or replaced. SCCs must be mapped to Pod Security Admission policies. Integrated pipelines must be reconstructed using external tooling. Applications move relatively easily; the operational environment they depend on does not.
Q. Is Kubernetes cheaper than OpenShift?
The honest answer is: it depends, and the comparison is rarely straightforward.
Kubernetes carries no licensing cost, which makes its initial price point appear significantly lower. But the total cost of operating a self-assembled Kubernetes platform spanning tooling, integration engineering, ongoing maintenance, and the headcount required to sustain it is frequently higher than it appears at adoption time.
OpenShift introduces a subscription cost but reduces the engineering surface an organization must own. At sufficient scale, or in organizations where platform engineering time is expensive and scarce, OpenShift's total cost of ownership can compare favorably to a self-managed Kubernetes stack. A rigorous cost comparison needs to account for operational labor, not just licensing a calculation that Section 10 of this guide addresses in detail.
Q. Does OpenShift create vendor lock-in?
Partially, and the nature of that lock-in is worth understanding clearly.
At the application layer, there is minimal lock-in. Containerized workloads remain portable to any Kubernetes-compatible environment. At the platform layer, however, OpenShift-specific constructs, its build system, routing model, integrated registry, and Operator ecosystem represent real dependencies that require effort to migrate away from. This is best described as workflow lock-in rather than application lock-in: moving workloads is feasible; rebuilding the operational environment they run in is the substantive cost of migration.


