
Introduction
Data is everywhere as we enter the digital age. Information about customer interactions, website traffic, sales numbers, and other topics is continuously being thrown at businesses. Although this data provides a wealth of insights, its ever-increasing volume and complexity are too much for traditional databases to handle. The slow and frustrating nature of analyzing large datasets may affect your capacity to make decisions based on data. Herein lies the strength of cloud-based data warehouses such as AWS Redshift. This guide aims to provide you with the necessary knowledge to thoroughly understand AWS Redshift and its role in big data analytics. We'll delve into its functionalities, explore cost-saving strategies, and provide real-world use cases to illustrate its power.
Understanding Data Warehouses
A data warehouse is a central storage site created to store and analyze past data. Your raw data is converted into a structured format and arranged for effective querying and analysis. Consider it a specialized archive optimized for deep analysis, as opposed to transactional databases that are more concerned with day-to-day tasks. Data warehouses support in-depth analysis, enabling you to pull important insights, trends, and patterns from your data.
Benefits
- Trend Analysis: Examine past data to identify patterns over time, which will help you improve future plans and make data-driven predictions.
- Complex Queries: Data warehouses are built to handle complex queries efficiently, allowing you to explore your data from various angles and extract deeper insights.
- Separation of Concerns: Data warehouses guarantee the best possible performance for both by separating analytical tasks from transactional systems.
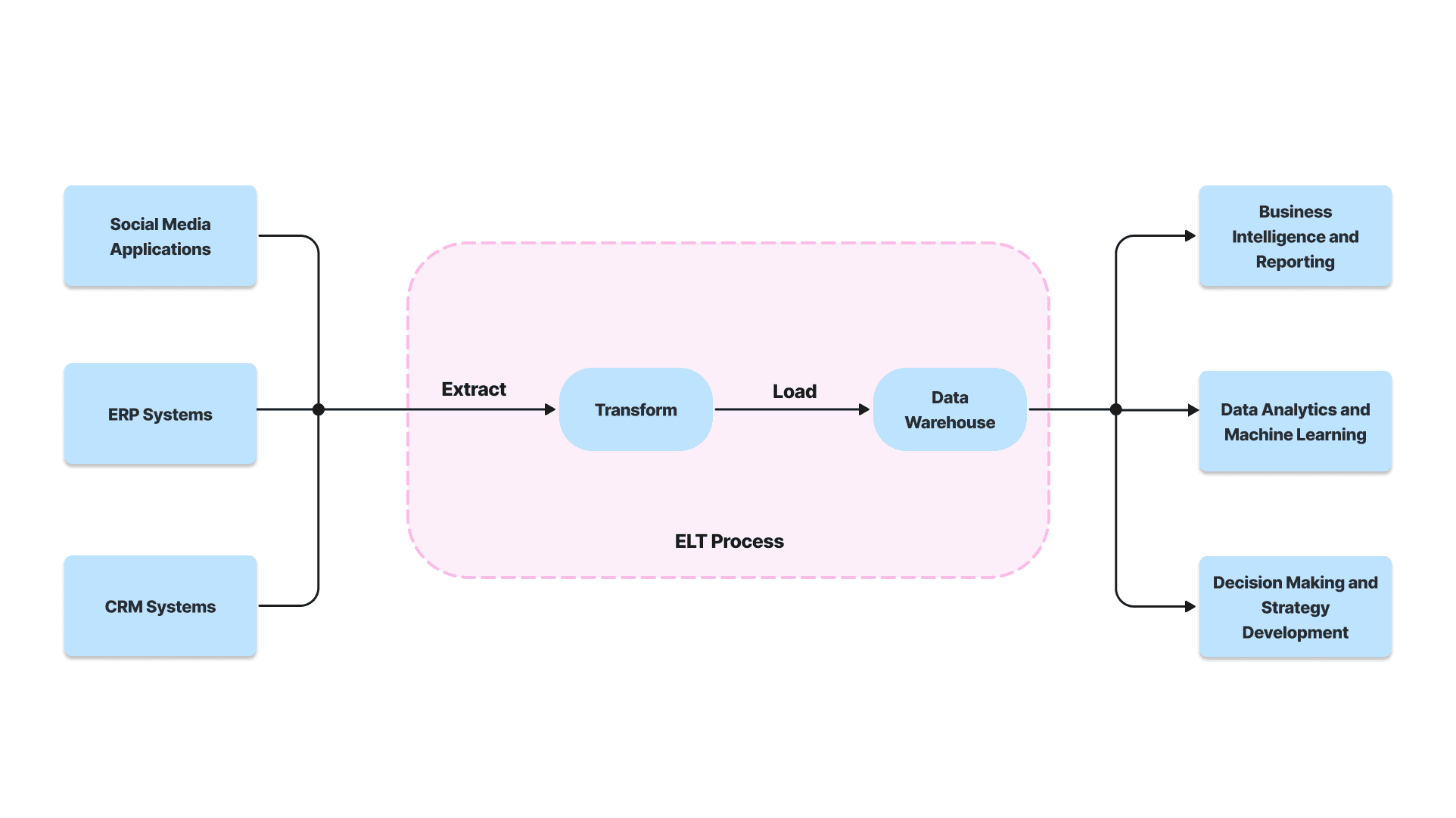
However, with the ever-growing volume and complexity of data, traditional data warehouses started to show limitations.
Limitations
- High Costs: Setting up and maintaining on-premise data warehouses can be expensive, requiring significant investment in hardware, software, and IT expertise.
- Scalability Challenges: Scaling storage and processing power to accommodate growing data volumes can be complex and costly.
- Vendor Lock-In: Traditional data warehouse solutions may lock you into specific hardware or software vendors.
The need for a more scalable, cost-effective, and agile solution paved the way for the emergence of cloud data warehouses.
What is a Cloud Data Warehouse?
The concept of cloud data warehousing emerged in the early 2000s. However, it wasn't until the late 2000s and early 2010s, with the rise of powerful cloud computing platforms, that cloud data warehouses gained significant traction.
Here are some key milestones in the history of cloud data warehouses:
- Early adopters: Companies like Amazon and Google were among the first to introduce cloud data warehouse services like Redshift and BigQuery, respectively.
- Focus on scalability and cost-effectiveness: Cloud data warehouses offered a pay-as-you-go model, eliminating the upfront costs of traditional data warehouses. Additionally, the ability to scale storage and processing power on-demand made them ideal for handling big data.
- Increased adoption and innovation: As cloud technology matured and more vendors entered the market, cloud data warehouses became a mainstream solution for businesses of all sizes.
Traditional Data Warehouse vs. Cloud Data Warehouse
Here's a table comparing traditional data warehouses and cloud data warehouses:
| Feature | Traditional Data Warehouse | Cloud Data Warehouse |
|---|---|---|
| Deployment | On-Demand | Cloud-based |
| Scalability | Limited scalability | Highly scalable |
| Cost | High upfront costs (hardware, software, IT staff) | Pay-as-you-go model |
| Management | Requires dedicated IT staff | Managed by the cloud provider |
| Security | Requires in-house security measures | Cloud providers offer robust security features |
| Integration | Limited integration capabilities | Easier integration with other cloud-based services |
| Accessibility | Accessible only on-premise | Accessible from anywhere with an internet connection |
What is AWS Redshift?
AWS Redshift is Amazon's cloud-based data warehouse service. It allows you to store, process, and analyze massive datasets efficiently, helping you unlock valuable insights from your business history to make informed decisions.
Key Features
- Scalability
- Cluster Management: Redshift utilizes a cluster architecture. A cluster is a group of compute nodes working together to process your data. You have complete control over the size of your cluster.
- Effortless Scaling: Need to analyze a large dataset requiring significant processing power? Simply add more nodes to your cluster. Conversely, during periods of low demand, you can scale down by removing unnecessary nodes. This ensures you only pay for the resources you actively use.
- Cost-Effectiveness
- Pay-As-You-Go Model: Redshift's pay-as-you-go pricing structure eliminates upfront costs. You only pay for the compute resources (nodes) and storage you use per hour.
- Granular Cost Control: Multiple factors influence your Redshift bill. Choosing the right instance type based on your workload, optimizing storage options based on data access frequency, and scaling your cluster effectively can all lead to significant cost savings. We'll explore these strategies in detail later.
- Ease of use
- SQL Compatibility: Redshift leverages familiar SQL syntax, making it accessible to individuals with existing SQL knowledge. You can start querying data and generating insights immediately.
- Intuitive Management Console: The web console allows for effortless management of Redshift clusters. You can monitor performance, configure settings, and perform administrative tasks without extensive technical expertise.
- Seamless Integration: Redshift integrates seamlessly with other AWS services like Amazon S3 for storage and Amazon QuickSight for business intelligence. This streamlines data management and analysis workflows.
These core features allow Redshift to deliver exceptional performance and affordability for big data analytics.
Redshift for Data Analysis Usecases
Once your data is stored in its scalable and secure environment, you can take advantage of its features to gain insightful business information. These are a few use cases:
Customer Behavior Analysis: Analyze years of sales data to uncover customer purchasing trends, understand product preferences, and refine your marketing campaigns for more precise targeting.
Imagine being able to identify which products customers frequently purchase together or which group of people are more likely to favor particular products. This allows you to personalize your marketing strategies and maximize customer engagement.
Data-Driven Marketing Strategies: Combine customer data with website traffic statistics to gain deeper insights into user behavior. This allows you to tailor your marketing tactics for higher conversion rates.
Let's say you notice a particular landing page on your website has a high bounce rate (users leaving without taking action). By analyzing user behavior on that page with Redshift, you can identify potential pain points and optimize the page for a better user experience, ultimately leading to more conversions.
- Supply Chain Optimization: Monitor inventory levels in real-time across your entire supply chain. This helps minimize obsolete stock, reduce stock-keeping costs, and enable proactive management. Redshift allows you to predict potential stock shortages and ensure you have the right products in the right place at the right time, ultimately streamlining your supply chain operations.
Social Media Sentiment Analysis: Analyze social media discussions to understand how customers perceive your brand, identify areas for improvement, and measure the effectiveness of your marketing initiatives.
Imagine having real-time access to consumer feedback on a new product launch or marketing initiative. Redshift allows you to track social media conversations and identify emerging trends, allowing you to refine your strategies and address customer concerns promptly.
Advanced Features and Considerations for AWS Redshift
While Redshift excels in core functionalities like scalability and cost-effectiveness, it offers a range of advanced features that cater to diverse analytical needs. Here's a glimpse into some of them:
- Distribution Styles: Redshift allows you to choose how data is distributed across nodes in your cluster. This selection can significantly impact query performance. Distribution styles like sort key and zone maps help optimize data locality for specific workloads.
- Workload Management (WLM): Managing workloads efficiently is crucial for performance optimization. Redshift's WLM allows you to prioritize queries, allocate resources effectively, and ensure smooth operation for various workloads running concurrently.
- Redshift Spectrum: This feature enables you to directly query data residing in your Amazon S3 data lake without physically loading it into Redshift. This can be cost-effective for analyzing cold data or data accessed infrequently.
- Redshift ML: Take advantage of built-in machine learning functionalities within Redshift to create, train, and deploy machine learning models directly on your data warehouse. This streamlines data preparation and model development workflows.
- Automated Management: Redshift offers features like automatic table optimization, vacuum deletes, and table sorting. These features automate maintenance tasks, ensuring optimal performance and reducing manual intervention.
Here are some additional considerations:
- Security: Redshift offers powerful security features to safeguard your data. Utilize access controls, encryption, and monitoring tools to ensure data privacy and compliance.
- Backup and Recovery: Regularly back up your Redshift clusters to prevent data loss due to unforeseen events. Explore options like automated snapshots and scheduled backups for comprehensive disaster recovery
- Monitoring and Logging: Closely monitor your Redshift clusters to identify potential performance bottlenecks and optimize resource usage. Use Amazon CloudWatch for detailed insights into cluster health and performance metrics.
By understanding these advanced features and considerations, you can unlock AWS Redshift's full potential and establish a robust data analytics environment for your organization.
Benefits of AWS Redshift
- Designed for Big Data: Redshift effortlessly handles massive datasets from gigabytes to petabytes. This makes it ideal for archiving and analyzing logs, sensor readings, and historical data, which can help us understand patterns and trends.
- Cost-effective Analytics: It works on a pay-as-you-go basis, which means there are no upfront infrastructure costs, unlike traditional data warehouses.
- Performance and Speed: To deliver answers rapidly, it divides queries among multiple nodes using a massively parallel processing (MPP) architecture. You can now quickly and efficiently find the answers to your business questions
- SQL Powerhouse: It makes use of well-known SQL syntax, which enables business users and data analysts to query and analyze data with ease without having to pick up new languages.
Drawbacks of AWS Redshift
- Real-time Analytics: Complex data loading latency makes it a poor solution for real-time analytics, even though it excels at historical data analysis.
- Cost Management: While Redshift offers a pay-as-you-go model, managing costs can be complex. Factors like instance type selection, storage optimization, and cluster scaling all play a role in the final bill. Careful configuration and monitoring are essential to avoid unexpected costs.
Redshift Pricing Model
Redshift provides a flexible pay-as-you-go model. Since you are only paying for the resources you really use, this results in significant cost savings.
The key factors affecting your Redshift bill are as follows:
Instance Types
Redshift offers various instance types, each with different compute power and storage capacities. These instance types are categorized into families, with some popular examples being:
- DC2 family: Ideal for general-purpose workloads and offers a balance of price and performance.
- RA3 family: Optimized for frequently accessed data, utilizing a combination of SSDs and HDDs for cost-effective storage.
- Dense Storage (DS2) family: Designed for storing massive datasets with high storage capacity at a lower compute cost.
vCPU Memory Addressable storage capacity I/O Price Dense Compute DC2 dc2.large 2 15 GiB 0.16TB SSD 0.60 GB/s $0.33 per Hour dc2.8xlarge 32 244 GiB 2.56TB SSD 7.50 GB/s $6.40 per Hour Dense Storage DS2 ds2.xlarge 4 31 GiB 2TB HDD 0.40 GB/s $1.25 per Hour ds2.8xlarge 36 244 GiB 16TB HDD 3.30 GB/s $10.00 per Hour RA3 with Redshift Managed Storage ra3.4xlarge 12 96 GiB 128TB RMS 2.00 GB/s $3.606 per Hour ra3.16xlarge 48 384 GiB 128TB RMS 8.00 GB/s $14.424 per Hour The cost of an instance type is directly tied to its processing power and storage. So, if you have a smaller dataset and require less processing muscle, you can choose a more economical instance type.
Storage Size
Redshift charges for the amount of data you store in your cluster. There are two main storage options to consider:
- Amazon Redshift block storage: This is traditional storage associated with your Redshift cluster instances. Pricing varies depending on the instance type chosen.
- Redshift Managed Storage (RMS) (with RA3 instances): This option automatically manages frequently accessed data on SSDs for faster performance and stores less frequently used data in a cost-effective tier on Amazon S3. You'll pay a separate fee per GB per month for data stored in the RMS.
Node Hours
Redshift charges per hour for each node running in your cluster. This means you only pay when your cluster is actively processing data. You can scale your cluster up or down based on your workload demands, optimizing costs by shutting down idle clusters.
For more information on AWS Redshift pricing, you can refer to this link.
The Big Question: Cost Optimization in Redshift
While Redshift offers a cost-effective solution for big data analytics, there are ways to further optimize your spending. Here are some key strategies to consider:
Optimize Cluster Configuration
- Instance Selection: Based on your workload, choose the right instance type. Dense Storage instances are ideal for cost-effectively storing large datasets, while Dense Compute instances offer more processing power for complex queries.
- Resize Clusters: Scale your cluster size (number of nodes) to match your workload demands. Avoid running an oversized cluster during idle periods. Use auto-scaling features to automatically adjust resources based on usage.
- Utilize Concurrency Queues: Implement workload management (WLM) with concurrency queues. This lets you prioritize critical queries and allocate resources efficiently.
- Optimize Queries
- Denormalize Tables: For faster query performance, consider denormalizing some tables to reduce complex joins. This can be a trade-off between storage space and query speed.
- Optimize Query Design: Write efficient SQL queries that take advantage of Redshift's columnar storage and parallel processing architecture. Avoid unnecessary data scans and suboptimal joins.
- Use Materialized Views: Pre-compute frequently used complex queries by creating materialized views. This can significantly improve query performance for repetitive analytical tasks.
- Storage Management
- Compression: Utilize Redshift's built-in compression to reduce the data storage footprint. Experiment with different compression encodings to find the best fit for your data types.
- Unload Unused Data: Regularly unload data that's no longer needed from your Redshift cluster to Amazon S3. This can save on storage costs while keeping the data readily accessible for future use.
- Redshift Spectrum: Consider using Redshift Spectrum to query data directly from your S3 data lake without loading it into Redshift. This can be cost-effective for infrequently accessed data.
- Cost-Saving Options
- Reserved Instances: Purchase reserved instances for predictable workloads. This can provide significant discounts compared to on-demand pricing.
- Scheduled Pausing: If your workload allows, consider pausing your Redshift cluster during off-peak hours. This can drastically reduce costs during periods of inactivity. For example, schedule your Redshift clusters to start and stop automatically based on your specific needs to further optimize your Redshift usage and streamline your workflow with CloudOptimo's Optimoscheduler.
- Pay-Per-Use: Take advantage of Redshift's pay-per-use option for variable workloads. You only pay for the compute resources you use, reducing costs during low-usage periods.
By implementing these strategies, you can optimize your Redshift usage and significantly reduce costs without compromising on performance or functionality.
When to Choose AWS Redshift?
Amazon Redshift is made for big data analytics. Here's a breakdown of when it's a good fit and when there might be better options:
Use redshift when:
- You're dealing with massive datasets. Petabyte-scale data is where Redshift's Massively Parallel Processing (MPP) architecture truly shines.
- You need fast querying for large datasets. Analyzing historical data or performing complex aggregations on big data is a sweet spot for Redshift.
- Your focus is on analytical workloads. Redshift excels at Online Analytical Processing (OLAP), which involves analyzing large sets of data to uncover trends.
Consider other options for :
- Smaller Datasets: For data that isn't massive (think terabytes or less), traditional relational databases like MySQL or PostgreSQL offered by RDS (AWS Relational Database Service) might be a more cost-effective solution. Redshift's power comes into play with petabyte-scale data, where its parallel processing architecture shines. For smaller datasets, the cost of managing a Redshift cluster might not be worthwhile.
- Frequent data modification is needed: Redshift leans towards read-heavy workloads (OLAP). For applications that involve frequent data inserts, updates, and real-time transactions (OLTP, or Online Transaction Processing), traditional databases like those offered by RDS are better suited.
- Bandwidth limitations exist: Transferring massive datasets to the cloud can be expensive, especially with bandwidth caps. If you have limited bandwidth availability, consider the cost implications of uploading your data to Redshift.
If your primary focus is on gaining insights from historical data, Redshift is an excellent choice. But for smaller datasets or frequent data updates, alternative solutions such as RDS might be more appropriate.
Consider an Alternative option for Redshift
Here are the key scenarios where we should consider alternative for Redshift such as RDS :
- Transactional workloads: RDS excels at Online Transaction Processing (OLTP) tasks. This includes frequently adding, updating, or deleting data in real-time, which is crucial for many applications. Redshift, on the other hand, is optimized for analyzing large datasets (OLAP) and might not be as performant for frequent modifications.
- Smaller datasets: For data that isn't massive (think terabytes or less), RDS can be a more cost-effective solution. Redshift's power comes into play with petabyte-scale data, where its parallel processing architecture shines. For smaller datasets, the overhead of managing a Redshift cluster might not be worthwhile.
- Simpler queries: If your queries are relatively straightforward and don't involve complex aggregations or joins across millions of rows, RDS can handle them efficiently. Redshift's strength lies in handling complex queries on massive data, but for simpler tasks, it might be overkill.
- Limited technical expertise: RDS offers familiar relational database engines like MySQL and PostgreSQL. If your team is more comfortable with these technologies and doesn't have the specialized knowledge required to manage Redshift clusters, RDS might be a more manageable option.
Here's a quick table summarizing the key points:
| Use RDS | Use Redshift |
|---|---|
| Frequent data updates (OLTP) | Big data analytics (OLAP) |
| Smaller datasets (terabytes or less) | Petabyte-scale data |
| Simpler queries | Complex queries on large datasets |
| Limited technical expertise (familiar with MySQL/PostgreSQL) | Need for specialized knowledge for Redshift clusters |
Note: The key is to identify the best tool for the job. Consider factors like data volume, query complexity, budget constraints, and your team's skillset to make an optimal choice. Unlock valuable insights and make informed decisions by choosing the right data warehousing solution.






