
Introduction
Big data is everywhere these days and there is often a huge amount of data that needs to be sorted through. Conventional approaches to handling this data often fall short. Amazon Elastic MapReduce (EMR) service and other cloud services can assist with that. EMR scales seamlessly to handle datasets of any size, allowing you to tackle even the most complex big data challenges.
Big Data: A Mountain of Information
Imagine a warehouse overflowing with boxes. Each box contains a piece of information, and there are just too many to sort through by hand. That's the challenge of big data—massive datasets that grow so large and complex that traditional data analysis tools can't handle it. It's like having a warehouse so packed you can't even open the door!
Properties of Big Data
Having a lot of data isn't the only element of big data. It involves the properties of that data, specifically its volume, variety, and velocity.
Volume:

This warehouse is enormous, filled with countless boxes representing the vast amount of data that businesses generate today. Traditional tools simply can't keep up with the sheer amount of volume.
Velocity:
New boxes arrive constantly, like social media posts and sensor readings. Traditional tools can't analyze this data fast enough to gain valuable insights.
Variety:

The boxes come in all shapes and sizes, just like big data. It can be structured data from spreadsheets, unstructured text from social media, sensor readings, and more. Traditional tools struggle with this variety.
Traditional data analysis tools become ineffective when dealing with big data due to these features.
The Big Data Challenge
Just like sorting a massive warehouse by a single individual is impossible, traditional programs struggle with the constant flow of big data, like social media posts and sensor readings. This data holds valuable insights, but traditional tools can't keep up. Imagine hidden patterns in social media trends or sensor readings that could revolutionize healthcare or optimize traffic flow. AWS EMR offers a powerful solution. It can efficiently sort and process this big data, unlocking the hidden gems of information within.
That's where distributed computing comes in. Think of it as splitting a giant pizza amongst friends. Distributed computing divides massive data tasks into smaller pieces, enabling multiple computers to work on them at once. It's similar to having a group of data analysts work together to process information quickly.
This powerful approach is the secret behind AWS EMR, a managed service built on industry leaders like Apache Hadoop, and Spark. These tools are like expert chefs, ensuring everything runs smoothly.
We can solve problems in the real world and improve our lives in many ways by discovering the hidden secrets of big data. Distributed computing is the key, and EMR provides the tools to get started.
What is AWS EMR?

Think of it as a professional organizer for your warehouse. EMR is a managed service by AWS that simplifies running powerful big data frameworks like Apache Hadoop and Spark. These frameworks allow you to process and analyze vast amounts of data to uncover hidden insights and the best part? It can be used without the need for technical expertise. Instead of putting together a physical computer cluster, AWS manages EMR, handling the complicated infrastructure so you can concentrate on what really matters—gaining knowledge from your data or deploying your machine learning models.
A large number of other popular open-source big data frameworks are also supported by EMR, such as:
- Presto: Provides interactive query speeds for data from multiple sources, including relational databases and S3.
- HBase: A NoSQL database designed to manage large datasets with fast read and write speeds.
- Flink: A framework for real-time analytics on data streams using stream processing.
- Hive: Offers capabilities for querying, analyzing, and summarizing data on sizable datasets kept in distributed storage.
AWS fulfills a range of big data processing requirements by providing multiple frameworks inside EMR.
Components of an EMR Cluster
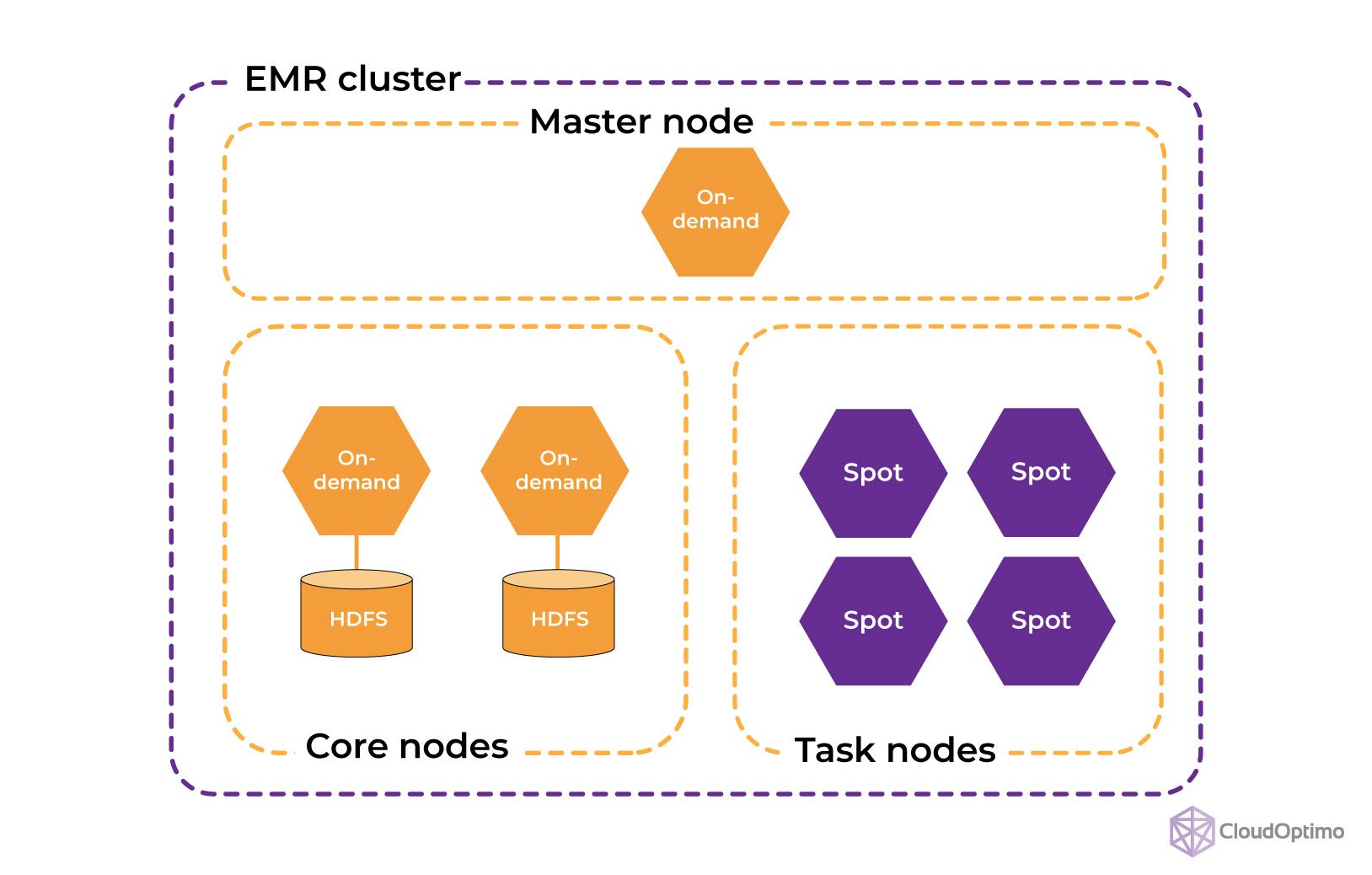
A cluster of EMRs consists of multiple essential parts, each with a distinct function in handling large amounts of data:
1. Master Node
All of the other instance’s tasks are organized by the master node, also referred to as the cluster's brain.
Responsibilities:
- Task Scheduling: This process receives task submissions, breaks them into smaller tasks, and assigns them to available Core or Task Nodes.
- Resource Allocation: Monitors health and resource availability of Core and Task Nodes, ensuring tasks are assigned to nodes with the necessary processing power and memory.
- Task Monitoring: Tracks the progress of running tasks, identifies failures, and retries them on healthy nodes if needed.
- Cluster Health: Monitors the overall health of the cluster, including node status and resource utilization.
Software:
- YARN Resource Manager: Schedules tasks and allocates resources across the cluster.
- HDFS NameNode: Provides the master directory for the filesystem and manages the mapping between files and their locations on DataNodes.
Use Case:
- Single point of contact for submitting jobs, monitoring cluster health, and managing applications running on the cluster.
- Critical for cluster coordination and ensuring smooth operation of distributed processing tasks.
2. Core Node
Core nodes in a cluster are its workhorses. Each core node typically holds a copy of the big data processing software, like Apache Spark.
Responsibilities:
- Data Storage: Core nodes act as distributed storage units using HDFS, ensuring data backup and fault tolerance.
- Task Execution: They receive tasks from the Master node, execute them using the processing power and installed frameworks (like Spark), and send results back.
Software:
- HDFS DataNode: Stores data blocks as instructed by the NameNode and replicates them across the cluster for fault tolerance.
- YARN NodeManager: Manages resources on the node, monitors container execution, and reports back to the Resource Manager.
Use Case:
- Forms the backbone of the cluster’s storage capacity.
- Provides the distributed processing power for executing big data workloads in parallel.
3. Task Nodes
Task nodes are those that can be added or removed from the cluster on demand to handle fluctuating workloads.
Responsibilities:
- Provides additional processing power for highly demanding workloads.
- Executes tasks assigned by the YARN Resource Manager just like Core Nodes, but are typically configured with more powerful CPUs or GPUs for intensive computations.
Software:
YARN NodeManager: Same functionality as on Core Nodes.
Use Cases:
- Cost-Effectiveness: Task nodes are typically cheaper and less powerful instances compared to Core nodes. This makes them ideal for handling temporary workloads or scaling up processing power for short durations without incurring high costs.
- Elasticity: They can be easily added or removed from the cluster on demand, allowing you to adjust the cluster size based on real-time requirements.
Additional Components:
- EC2 Instances: EC2 Instances are the underlying virtual servers that make up the cluster nodes. EMR allows you to choose instance types with varying configurations (CPU, memory, storage) to meet specific workload requirements.
- Software Applications: EMR comes pre-installed with a wide range of popular big data frameworks like Apache Spark, Apache Hive, Presto, and HBase. You can also install additional tools and libraries using bootstrap actions to customize the cluster for your specific needs.
- Amazon S3: AWS S3 is often used as the primary storage for the cluster data lake. EMR provides an S3-compatible file system (EMRFS) for easy access to data stored in S3 buckets.
Choosing the Right Node Mix
The optimal mix of Master, Core, and Task Nodes depends on your specific workload:
- For smaller or predictable workloads: A single Master node with a few Core nodes might be enough.
- For larger workloads: To handle peak processing demands without going over budget, think about adding Task nodes.
By understanding the roles and capabilities of each node type, you can configure your EMR cluster for optimal performance, cost-efficiency, and scalability to tackle any big data challenge.
The EMR Ecosystem: The Big Data Toolbox
EMR works with other tools to perform various data analysis tasks. Here are two important ones:
- Apache Spark: Imagine this as the engine that runs your data analysis. Apache Spark is an effective tool for swiftly processing big datasets on several EMR cluster computers.
- Hadoop Distributed File System (HDFS): Consider this as a massive storage system made especially to hold enormous volumes of data. The EMR cluster can be compared to a distributed filing cabinet where all of your data is stored. Imagine you have a vast document collection, and traditional filing cabinets aren't enough. HDFS is like splitting the documents into smaller chunks and storing them across multiple cabinets (computers in the EMR cluster). This way, you can access any document quickly, even if it's spread across different cabinets.
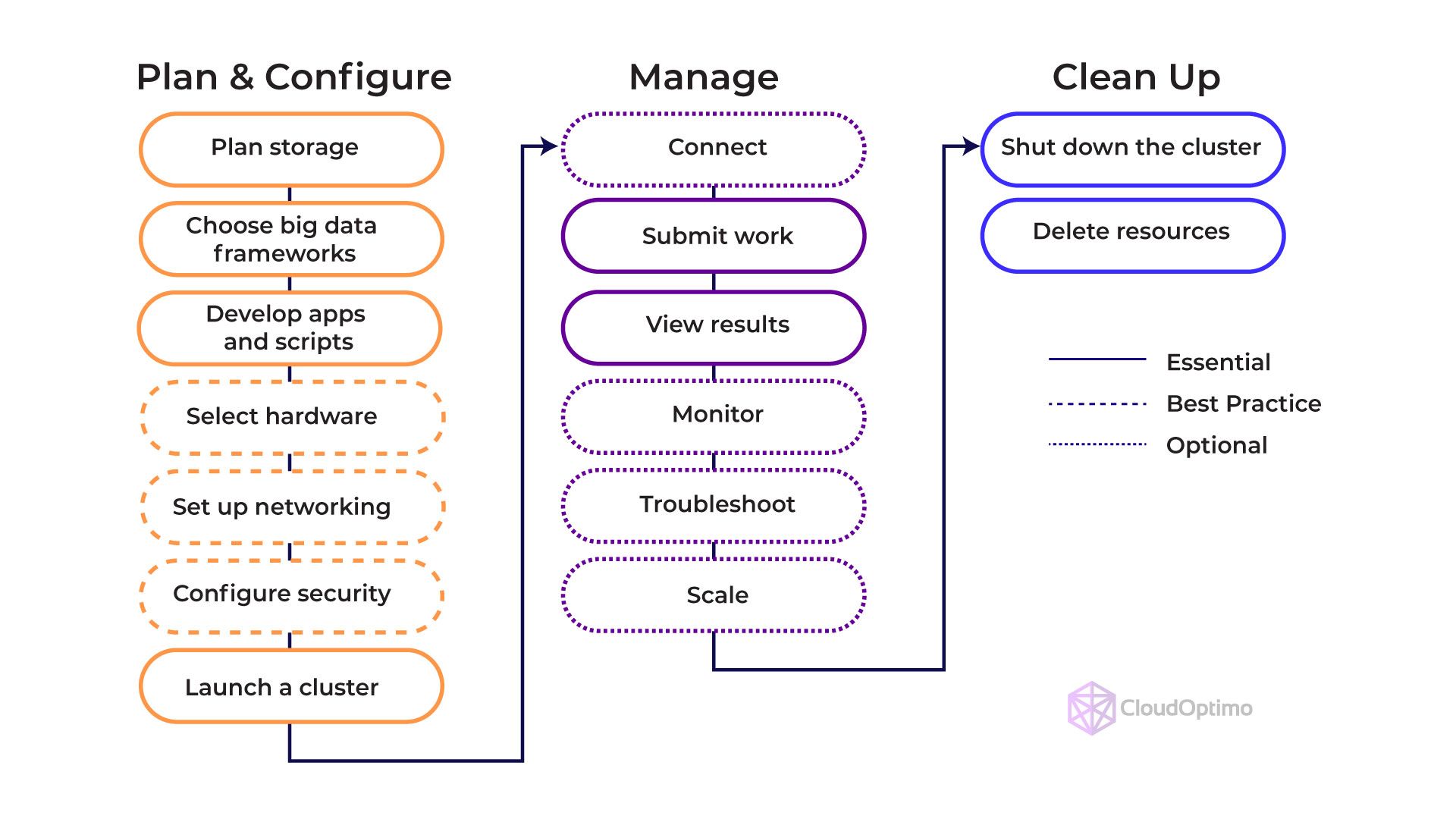
How does the EMR Cluster work
- Cluster Creation: You define the type and number of nodes (Master, Core, and Task) needed for your big data processing task and choose the software tools you want to use (like Spark). EMR supplies the necessary EC2 instances (virtual servers) in the cloud and configures them with the chosen software.
- Task Submission: You submit your big data processing job to the cluster. This task specifies the operations to be performed on your data.
- Task Scheduling and Execution: The Master Node takes your task, breaks it down into smaller tasks, and schedules them for execution on the available Core and Task Nodes.
- Data Processing: The Core Nodes and Task Nodes process the assigned tasks using the data stored in HDFS and big data software tools like Spark.
- Task Monitoring and Results: The Master Node monitors the progress of the tasks and gathers the results. Once the job is complete, you can access the output data and gain insights from your analysis.
The below diagram will clearly explain the AWS EMR workflow:
Benefits of AWS EMR
- Pre-built tools: No need to set up complex software from scratch. EMR offers ready-made clusters with popular big data tools like Apache Spark, Apache Flink, Presto and HBase ready to use.
- Flexible sizing: Need more processing power for a big project? Scale your EMR cluster up. Need less for a smaller task? Scale it down. Only what you use is paid for.
- Cost-Effective: EMR's pay-as-you-go model lets you optimize costs. You only pay for the resources you use, making it ideal for both occasional and frequent big data processing needs.
- Secure: AWS takes care of security, so your data stays safe with encryption and other features.
- Focus on results: With EMR managing the infrastructure, you can focus on analyzing your data and getting valuable insights for your business.
Ways to utilize EMR Service - Instance Groups and Fleets
While pre-configured clusters offer simplicity, EMR also provides for advanced users who require more control. You can configure custom clusters using two key concepts: Instance Groups and Instance Fleets.
1. Instance Groups
An EMR cluster is typically made up of several Instance Groups. Every Instance Group consists of a set of identical EC2 instances, each of which serves a particular purpose inside the cluster.
In the instance group of an EMR cluster, you can set up either Spot Instances or On-Demand Instances. Below is an explanation of each type:
Spot Instances
The maximum amount you are willing to pay per hour is specified when setting up AWS Spot Instances for an EMR cluster. After that, EMR will make an effort to start instances at the price you have bid. Since Spot Instances are interruptible, EMR can automatically launch new Spot Instances to replace interrupted ones, minimizing disruption to your cluster.
Below are the factors to keep in mind before configuring spot instance:
- Cost-Effective: Compared to on-demand instances, spot instances can save a substantial amount of money. However, due to fluctuations in supply and demand in the AWS marketplace, prices are always subject to change .
- Interruptible: If the price of the market increases, AWS has the ability to stop Spot Instances. This may result in resource loss for your EMR cluster, which could have an effect on your deployment.
- You can also use CloudOptimo’s OptimoMapReducer to utilize spot instances and be worry-free about the disruptions spot instances face.
Your EMR cluster can be customized to meet the unique processing requirements and data volume of your organization by adjusting the kind, quantity, and arrangement of its instance groups.
On-Demand Instances
It's simple to add On-Demand Instances to your EMR cluster. At a set hourly rate, they offer reliable performance and availability. They are therefore perfect for demanding production workloads that call for reliable resources. Below are factors you need to consider:
- Reliable: There's never a shortage of on-demand instances, so your EMR cluster will always have the resources it needs to function without interruption.
- Regular Price: For on-demand instances, you pay a set hourly rate regardless of the workload or EC2 availability zone.
Considerations for Selecting Instance Types:
- Cost: When compared with On-Demand Instances, Spot Instances can save a lot of money. Still, prices vary according to demand.
- Availability: Spot instances may be interrupted if the market price increases, but On-Demand instances are always available.
- Workload Requirements: Consider your workload’s fault tolerance. Spot instances are a good option if your jobs can handle interruptions. Critical workloads requiring steady performance are better suited for on-demand instances.
Understanding the benefits and drawbacks of each instance type will help you set up your EMR cluster to operate at peak efficiency and at the lowest possible cost.
2. Instance Fleets
It offers another approach to managing EMR cluster compute resources. Instead of pre-defining the number of instances in an Instance Group, an Instance Fleet specifies a target configuration (instance type, price, etc.) and the EC2 instances are automatically provided and managed by AWS. This approach can be beneficial for:
- Cost Optimization: Within a fleet, you can specify multiple instance types with varying costs and capabilities. This lets you choose the most cost-effective option for each task within your workload. For instance, you can use powerful instances for demanding tasks and less expensive ones for simpler tasks, all within a single fleet.
- Availability: Fleets can launch instances across multiple Availability Zones, improving fault tolerance and ensuring your cluster remains operational even if an entire Availability Zone encounters an outage.
In an AWS Spot Fleet, you can add or modify both Spot and On-Demand instances, similar to EMR Instance Groups.
Spot Instances within the Spot Fleet
A group of Spot Instances that work together to help you provision and manage capacity more affordably is called a Spot Fleet. The operation of each kind of instance in a Spot Fleet is broken down as follows:
- Cost-Effective: Using Spot Instances in a Spot Fleet has several benefits, the main one being the significant cost savings over On-Demand Instances. Within the parameters you have specified, Spot Fleet automatically looks for the best available Spot Instance offers and launches instances in line with those findings.
- Interruptible: If the market price increases above your bid, Spot Instances within a Spot Fleet, like individual Spot Instances, may also become interrupted. In an effort to ease this, the Spot Fleet launches replacements automatically in order to keep your target fleet capacity.
- CloudOptimo’s OptimoMapReducer can be used to utilize spot instances for task nodes and be worry-free about the disruptions spot instances face.
On-Demand Instances in Spot Fleet
- Provides Base Capacity: Although Spot Instances are very cost-effective, they can be interrupted. Within your Spot Fleet, you have the option to set a base capacity for On-Demand Instances. This guarantees a certain degree of consistent capacity for your workload even in the event that Spot Instances are interrupted.
- Higher Costs: On-demand instances within a Spot Fleet are charged at their usual rate, which makes them more expensive compared with Spot Instances. However, they provide the reliability needed for critical tasks.
Selecting On-Demand vs. Spot Instances in a Spot Fleet:
- Cost is a Crucial Element: It's best to use Spot Instances in your Spot Fleet if cost is your top priority and your workloads can withstand disruptions.
- Consider Fault Tolerance: It's advised to add a buffer of On-Demand Instances to your Spot Fleet to ensure a certain amount of predictable capacity for workloads that can't withstand interruptions.
Spot Fleet Auto-Scaling: By using Spot Fleet Auto-Scaling, you can dynamically adjust the mix of On-Demand and Spot instances in your fleet according to real-time conditions. By doing this, you can maximize savings without sacrificing the capacity of your fleet.
By being aware of the factors of each instance type, you can efficiently configure your Spot Fleet to find a balance between workload requirements and cost efficiency.
Let's explore some of the more advanced features of the EMR now that you have a clear understanding of its fundamentals.
- Utilize cost-effective Spot Instances to support cluster provisioning. Spot Instances: These are discounted, unused EC2 instances, but they may experience interruptions. EMR can handle these interruptions and reschedule tasks to ensure your job is completed.
- IAM Roles and Access Control: EMR integrates with IAM roles to provide fine-grained access control to cluster resources and data. This ensures that only authorized users can access and manage the cluster.
Types of IAM Roles in EMR:
- EMR Service Role: This role grants permissions for the EMR service to provision cluster resources, manage applications, and interact with other AWS services on your behalf.
- EC2 Instance Profile Role: This role defines the permissions for the EC2 instances within your cluster. It allows them to access data stores, communicate with other services, and execute tasks as instructed by the EMR applications.
- Additional Roles (Optional): You can create custom IAM roles for specific purposes.
Real-World Use Cases and Benefits
Consider a social media company that wishes to examine user activity to improve its platform. A vast collection of user posts, likes, comments, and other interactions make up their dataset. This data is kept in Amazon S3, an AWS cloud storage service, which offers a cost-effective way to store big data before it's processed by EMR. It would be complicated and ineffective to analyze this data on a single computer using traditional techniques.
Here's where AWS EMR comes in. EMR lets you easily create and manage clusters of computing instances. These instances can be used to run big data processing frameworks like Apache Spark. Social media companies can use EMR to process their data stored on S3 using Spark. The process can be accelerated considerably by using Spark to split up the workload among the clusters and analyze the data in parallel.
This analysis can reveal hidden patterns in user behavior. The company might learn, for example, what kinds of posts receive the most interaction or how users from different age ranges use the platform. Afterwards, this information can be utilized to improve the social media platform's overall efficiency, customize the user experience, and suggest relevant content.
To make it short, EMR gives social media businesses the ability to use frameworks like Spark to analyze massive data kept on S3, revealing insightful information that helps them improve their platform and user experience. This is just one example of how EMR tackles real-world big data challenges in various industries.
To conclude, AWS EMR provides a strong and scalable platform for managing workloads involving large amounts of data. Businesses can concentrate on gaining insightful information from their data by using EMR to improve processes like provisioning, cluster management, and data processing.
Other examples of use cases are as follows:
| Use Case | Description |
|---|---|
| Log Analysis | Process and analyze large volumes of log data from web applications, servers, or other sources to identify trends, diagnose issues, or gain insights into user behavior. |
| Data Warehousing | Aggregate and store data from various sources for data analysis and reporting. EMR can handle data transformation, cleansing, and loading efficiently. |
| Scientific Computing | Perform complex simulations and calculations on large scientific datasets like weather forecasting models, or genome sequencing. |
| Machine Learning | Train and deploy machine learning models on massive datasets. EMR can parallelize the training process for faster model development. |
| Real-time Analytics | Process streaming data feeds for near real-time insights and analytics. EMR can be configured to handle continuous data ingestion and analysis. |
| Clickstream Analysis | Analyze user behavior and website/application usage patterns by processing clickstream data. EMR can help understand user journeys and optimize user experience. |
| Sentiment Analysis | Analyze social media data, customer reviews, or other textual content to understand sentiment and opinions. |
| Genomics Data Analysis | Handle large-scale genomics data analysis tasks for research in personalized medicine, gene expression studies, or other biological fields. |
| Financial Modeling | Perform complex financial modeling and risk simulations on large datasets. EMR can handle the computational demands of these tasks. |
| Fraud Detection | Analyze financial transactions or user activity data to identify patterns and anomalies indicative of fraudulent behavior. |
| Recommendation Systems | Process user behavior data to build recommendation systems that suggest products, content, or services to users. |
However, businesses looking to use big data on AWS in a more automated and simplified manner may look into OptimoMapReducer. In order to give you an even more efficient and user-friendly big data experience and help you quickly realize the full potential of your data by providing features to:
- Provide an overview of the cluster configuration to users through its user-friendly dashboard.
- Replace existing on-demand worker nodes with spot instances to reduce the cost spent on EMR clusters by up to 90%.
- Allow users to see a full list of running/terminated instances.
Ready to streamline your EMR experience and unlock data insights faster?
Start your free trial of OptimoMapReducer today!
Explore more at CloudOptimo!






