
Your ML model is only as good as the data feeding it. Yet in most production environments, the pipeline is the weakest link. Fragile ingestion scripts, ad-hoc schedulers, and environment drift quietly corrupt training sets long before anyone notices. By the time a model drifts in production, the damage is already done.
Kubernetes has become a widely adopted foundation for production MLOps platforms because it provides scalable execution, workload isolation, scheduling, and automation across the full data-to-model lifecycle. ETL for ML on Kubernetes is not just an architectural preference: it is a practical answer to the chronic fragility of pipelines that must feed production ML systems reliably, at scale, and on a budget.
This guide assumes familiarity with containers and Kubernetes basics. It focuses on production architecture decisions, reliability patterns, and operational practices for ML data pipelines: from primitives to security, cost control, and observability.
Why Kubernetes Excels for ETL in ML Workloads
Traditional orchestrators on VMs suffer three chronic problems: dependency drift between stages, resource contention between co-located jobs, and brittle scaling that requires pre-provisioned capacity. Kubernetes significantly reduces all three by design.
Containerized isolation: Your CUDA-enabled PyTorch transformation stage does not share a runtime with the lightweight Python extraction script beside it. Each stage runs in its own container with its own dependency tree and resource budget. Kubernetes manages execution, scheduling, and lifecycle. Distributed frameworks like Spark, Ray, or Dask still handle the actual computation inside those containers.
Elastic scheduling: It provisions GPU nodes for training only after loading completes, then terminates them immediately. There are no idle nodes burning budget overnight.
Unified operational model: When your data and ML training planes both live on Kubernetes, the entire stack is expressed in declarative YAML. This enables GitOps, audit trails, and rollbacks across the full pipeline.
Kubernetes Core Primitives for Building ETL Pipelines
Understanding which primitive to reach for, and why, separates a resilient pipeline from a fragile one.
Workload Controllers
Jobs are the backbone of batch ETL. Configure backoffLimit for retry behavior and podFailurePolicy to distinguish retriable errors (transient network timeout: exit code 1) from hard failures (bad credentials or schema mismatch: exit code 2). This prevents your retry budget from being wasted on failures that will never self-resolve. CronJobs wrap Job templates with a schedule. Generally, set successfulJobsHistoryLimit: 3 and failedJobsHistoryLimit: 1. Without these, the API server accumulates thousands of completed Job objects and degrades cluster performance over time.
Networking: Services and Network Policies
A ClusterIP Service in front of your feature store gives transformation pods a stable DNS endpoint regardless of pod churn. For low-latency intra-namespace calls, headless Services bypass kube-proxy entirely.
NetworkPolicies are strongly recommended in shared clusters. Kubernetes' flat network allows any pod to communicate with any other. This is a real risk if an internet-facing extraction pod is compromised. Apply a default-deny egress policy to your ml-data-pipelines namespace with explicit allow-lists: transformer pods egress to PostgreSQL on port 5432, and nothing else.
Storage: Volumes, PVCs, and Lakehouse Formats
PVCs backed by NVMe SSDs let pods stage and manipulate large datasets locally without network latency. Use ReadWriteOnce for single-pod scratch space; use ReadWriteMany when parallel Job pods need shared access. CSI integrations can simplify access to object storage in specific cases, but workloads should still treat object storage differently from traditional filesystems due to consistency and performance characteristics.
For large ML datasets, lakehouse formats (Apache Iceberg, Delta Lake, or Apache Hudi) add partitioning, schema evolution support, and transactional updates on top of object storage. This is exactly what production feature stores need. EmptyDir with medium: Memory is underused but effective for temporary buffers, avoiding unnecessary disk I/O before flushing to persistent storage.
GPU Scheduling
Use the extended resource syntax: nvidia.com/gpu: 1 under both requests and limits. This only works if the NVIDIA device plugin or NVIDIA GPU Operator is installed. Without it, Kubernetes cannot discover or schedule GPU resources. The GPU Operator is the recommended approach for managed environments as it handles driver installation and device plugin lifecycle. Apply node affinity rules and taints/tolerations to ensure CPU-only ETL pods never land on accelerator nodes. A misconfigured toleration scheduling a pandas groupby on an A100 is preventable and expensive.
Configuration and Secrets Management
ConfigMaps hold non-sensitive parameters. Secrets hold credentials, but Kubernetes Secrets are base64-encoded by default, not encrypted. Enable encryption at rest via EncryptionConfiguration and integrate an external secret manager (AWS Secrets Manager, Azure Key Vault, HashiCorp Vault via Secrets Store CSI) in production. Mount Secrets as read-only volumes; never bake them into images. ServiceAccounts follow least privilege: an Argo controller SA needs create/get/watch on Pods in ml-data-pipelines only.
End-to-End Architecture for ETL-to-ML Pipelines on K8s
A production pipeline has six phases. Validation gates are as important as the compute stages:
- Extract: CronJob-triggered containers pull from databases, APIs, or event streams and land raw Parquet files in object storage.
- Validate (Raw): Schema contract checks run before transformation; bad records go to a dead-letter queue immediately.
- Transform: Parallel indexed Jobs process validated partitions, normalize data, and engineer features.
- Validate (Features): Statistical and schema checks on the transformed feature set before it touches the feature store.
- Load: A Job writes finalized features within a transaction boundary: your idempotency gate.
- Train: The orchestrator triggers the Kubernetes Training Operator, provisioning PyTorchJob workers across GPU node pools only after loading succeeds.
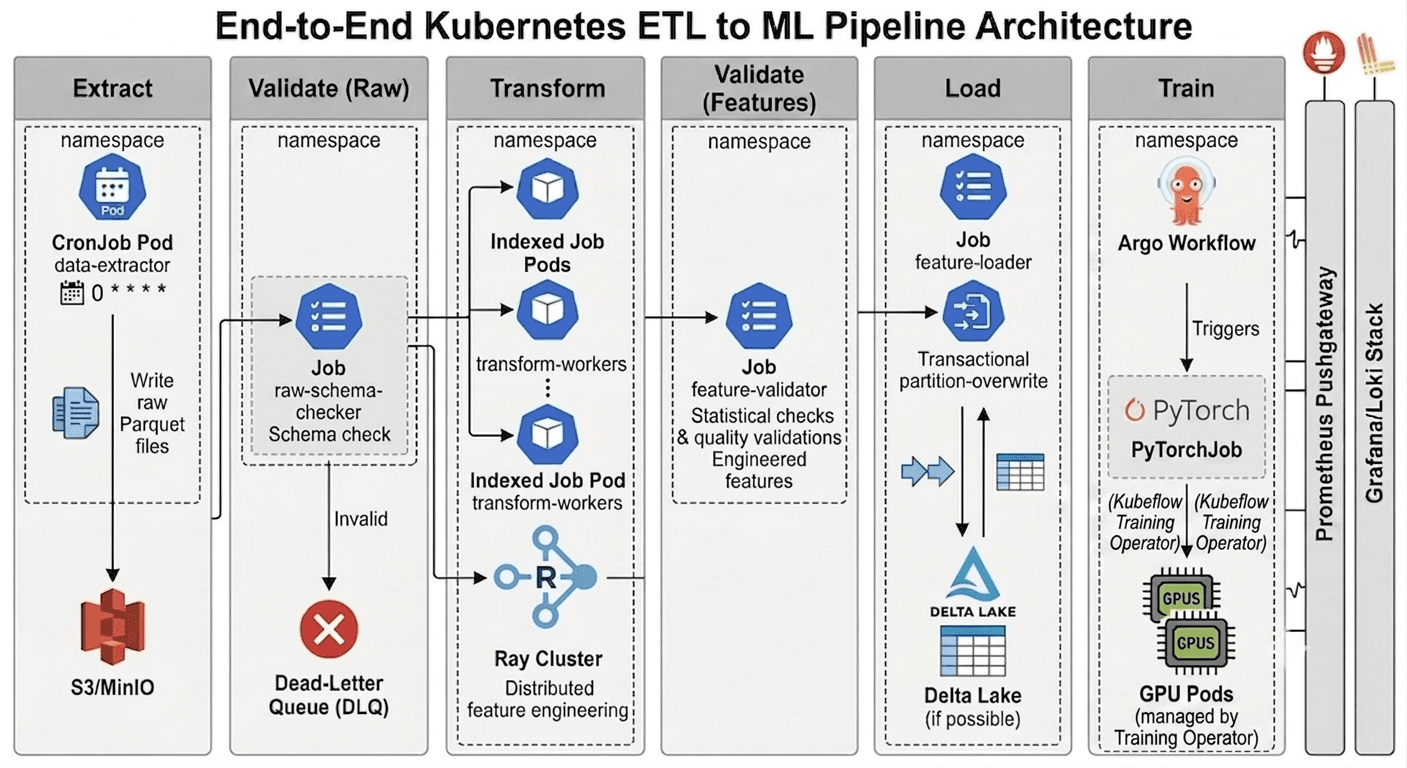
Figure 1: End-to-End MLOps ETL Pipeline Architecture on Kubernetes, featuring integrated validation, distributed transformation, and observability.
Common pitfall: Writing directly from transformation to the training target skips the loading gate. When a transformation fails mid-write, your feature store holds a partial dataset with no rollback path. Always separate transform and load.
Step-by-Step Implementation Guide
Step 1: Containerize with Multi-Stage Builds
Multi-stage builds separate build from runtime and can significantly reduce image size by removing unnecessary build dependencies:
| FROM python:3.11-slim AS builder COPY requirements.txt . RUN pip install --user --no-cache-dir -r requirements.txt FROM python:3.11-slim COPY --from=builder /root/.local /root/.local COPY transform_features.py . USER 10001 ENTRYPOINT ["python", "transform_features.py"] |
Step 2: Define Resilient Jobs with Failure Policies
Exit with code 1 for retriable errors and code 2 for hard failures. podFailurePolicy inspects these codes and either retries or terminates immediately. Configure Ignore for the Disrupted pod condition so Spot preemptions do not burn retry attempts.
Pro Tip: Set memory limits 20–30% above measured peak. The OOM killer terminates silently with no actionable error: one of the hardest failure modes to debug in production.
Step 3: Orchestrate the DAG with Argo Workflows
Argo Workflows provides Kubernetes-native DAG coordination via CRDs for multi-stage pipelines:
| YAML dag: tasks: - name: extract template: run-extractor - name: transform dependencies: [extract] template: run-transformer arguments: parameters: - name: raw-data-path value: "{{tasks.extract.outputs.parameters.raw-path}}" |
When combined with Argo CD or Flux, DAG changes become reviewable pull requests. They are auditable, versioned, and rollback-safe.
Scaling, Reliability, and Production Best Practices
Idempotency: The Foundation
Use atomic partition replacement. Write to a deterministic path keyed by execution date (e.g., s3://feature-store/customer_features/date=2026-06-17/) and drop-and-replace that partition transactionally using Iceberg or Delta Lake. Never use now() or today() inside pipeline logic. Pass the execution date as an explicit parameter. For streaming pipelines, use consumer group offsets, checkpoints, or event IDs to track exactly-once processing. Without this, a restarted job produces duplicated features.
Data Lineage and Reproducibility
Can you answer which dataset version created this model? If not, you have a lineage gap. Track source data version, transformation code version (Git SHA), feature dataset version, and training parameters together for every run. OpenLineage and ML Metadata (MLMD) capture this provenance automatically when integrated with your orchestrator. MLflow and DVC handle dataset snapshots and artifact hashes. This makes debugging model regressions tractable and regulatory audits survivable.
GitOps Integration
Treat all pipeline manifests as code in Git. Argo CD or Flux continuously reconcile cluster state against the repo. Use Kustomize overlays for environment-specific settings (resource limits, failure thresholds) from a single base manifest, eliminating configuration drift between staging and production.
Cost Optimization
Spot or preemptible nodes for stateless ETL Jobs can cut compute costs significantly. Configure podFailurePolicy to ignore the Disrupted condition, implement job checkpointing, and set terminationGracePeriodSeconds long enough to flush state before shutdown. Vertical Pod Autoscaler in recommendation mode suggests right-sized resource requests. Use Cluster Autoscaler with node pool separation to scale GPU nodes to zero between training runs. A single idle A100 overnight can cost more than a full day of ETL compute.
Security Hardening
Beyond NetworkPolicies and RBAC, production pipelines need layered controls. Enforce Pod Security Standards (restricted or baseline profiles) to block privilege escalation and host path mounts. Integrate Trivy or Grype in CI to block images with critical CVEs. Use Kyverno or OPA Gatekeeper for cluster-wide admission policies: no latest tags, mandatory resource limits, required labels on Job specs. Enable EncryptionConfiguration at the API server and use an external secret manager rather than relying on base64-encoded Secrets.
Multi-Tenant Kubernetes Considerations
Namespaces alone are not sufficient for shared clusters. Apply ResourceQuota to cap CPU, memory, and GPU per team. Use LimitRange to set default requests and limits so unsized pods do not starve neighbors. PriorityClass controls eviction order between production training and experimental runs. For strong isolation, provision separate node pools per team with node affinity rules.
Monitoring: Prometheus, Loki, and Grafana
Prometheus Pushgateway is useful for short-lived batch jobs. Jobs push metrics (job_success, job_duration_seconds, job_processed_rows, job_retries_total) via HTTP POST before exiting. Complement with kube-state-metrics for Job-level status signals with zero application instrumentation. Loki can reduce logging costs by avoiding full-text indexing: it indexes only pod labels. Correlate metrics with Loki log streams in a single Grafana dashboard. Alert on: kube_job_status_failed > 0, job_processed_rows < expected_threshold, and job_duration_seconds > p99_baseline * 1.5.
Common Production Failures and Disaster Recovery
These failures hit teams repeatedly: schema changes in source systems load nulls silently when SELECT * is used; partial writes without transactions leave corrupt partitions; OOM kills from undersized limits produce no useful logs; unconfigured podFailurePolicy lets Spot preemptions burn retry budgets; and GPU nodes left running after training due to missing Cluster Autoscaler configuration.
On recovery: back up Argo Workflow metadata, store all manifests in Git, and enable object storage versioning on feature store buckets so a bad load can be reversed. Test your recovery path: an untested backup is not a backup.
Orchestration Tool Trade-Offs
| Evaluation Vector | Argo Workflows | Kubeflow Pipelines | Apache Airflow on K8s |
| Architecture | Kubernetes-native CRDs, minimal footprint | ML workflow orchestration with K8s-native execution | Standalone; KubernetesPodOperator triggers pods |
| Pipeline Definition | Declarative YAML or Python (Hera SDK) | Python DSL compiled to JSON/YAML | Pure Python DAGs on a persistent worker layer |
| ML-Specific Features | None native; delegates to external operators | Experiment tracking, model registry, artifact lineage | Minimal; requires third-party plugins |
| GitOps Integration | Excellent; pairs natively with Argo CD/Flux | Moderate; needs additional tooling | Limited; state lives in metadata DB |
| Operational Complexity | Low (single operator install) | High (multiple services, CRDs, storage dependencies) | Moderate (persistent DB, scheduler, web server) |
| Best For | Platform teams prioritizing GitOps | Data science teams needing integrated ML lifecycle | Enterprise teams managing legacy + cloud pipelines |
Mapping Kubernetes Primitives to the ETL-to-ML Lifecycle
| Pipeline Phase | Kubernetes Primitive | Rationale |
| Data Extraction | Job / CronJob / Deployment | CronJobs for batch; Deployments for streaming |
| Schema Validation | Job (validation gate) | Contract checks; routes bad records to dead-letter |
| Data Transformation | Indexed Job (Parallel) | Ephemeral workers per partition |
| Staging Storage | PVC (NVMe) + Lakehouse | Local block for speed; lakehouse for transactions |
| Configuration | ConfigMap / Secret + Manager | Decouples parameters; encrypts credentials |
| Data Loading | Job (with transaction guard) | Idempotent partition-overwrite; success gate |
| Model Training | CRD (PyTorchJob / TFJob) | Training Operator manages GPU workers |
| Pipeline Orchestration | Argo Workflow CRD | DAG coordination, parameters, execution |
| Autoscaling | HPA / VPA / Cluster Autoscaler | Right-sizes requests; provisions/deprovisions |
Frequently Asked Questions (FAQs)
How is data versioning managed within Kubernetes ETL pipelines?
Kubernetes does not handle data versioning; that lives at the storage and application layer. Lakehouse formats like Iceberg and Delta Lake provide time-travel natively. Register feature dataset version hashes or partition paths in MLflow or DVC, and pass them as output parameters from transform Jobs to training jobs for fully reproducible runs.
Argo Workflows or Kubeflow Pipelines: which is right for my team?
Platform-engineering-led teams prioritizing GitOps generally find Argo Workflows the stronger choice. Data-science-led teams needing built-in experiment tracking, model registry, and artifact lineage will find Kubeflow Pipelines worth the complexity. Avoid running both: the overlap creates confusion and doubles maintenance burden.
How do I prevent OOM terminations in large transformation Jobs?
Process data in batches or use lazy-evaluation frameworks like Polars or Dask. Set memory requests near your measured baseline and limits 20–30% above peak. Enable VPA in recommendation mode for data-driven sizing. If a single pod cannot fit the data, distribute partitions across indexed parallel Jobs rather than scaling one pod vertically.
What is the right strategy for schema evolution in production?
Define schema contracts using Avro, JSON Schema, Great Expectations, or Pandera as an explicit gate before transformation. Treat breaking changes (dropped columns, type mutations) as events that halt the pipeline, route bad records to a dead-letter queue, and trigger immediate alerts. Loud, fast failure beats silent corruption surfacing as model degradation hours later.
Why does standard Prometheus scraping not work for ETL Jobs?
Prometheus scrapes at fixed intervals. A fast ETL Job can spin up, process a batch, and terminate before a single scrape fires. Prometheus Pushgateway addresses this: Jobs push metrics via HTTP POST before exiting, and the Pushgateway holds them for the next scrape cycle. kube-state-metrics covers Job-level status signals from the Kubernetes API with zero application instrumentation.





