
Introduction
The ever-growing volume of data presents both challenges and opportunities for businesses. Extracting valuable insights from this data is crucial for informed decision-making, improved customer experiences, and gaining a competitive edge. Within the vast ecosystem of AWS services, two services stand out for data analytics: AWS Athena and AWS Glue. Both cater to data exploration and manipulation. While their names might suggest competition, they serve distinct yet complementary purposes. Understanding the core functionalities and ideal use cases of each service helps you make informed decisions and build a robust data analytics pipeline on AWS. This blog post delves into the details of Athena and Glue, guiding you through their strengths, limitations, and how they work together seamlessly.
What is AWS Athena?
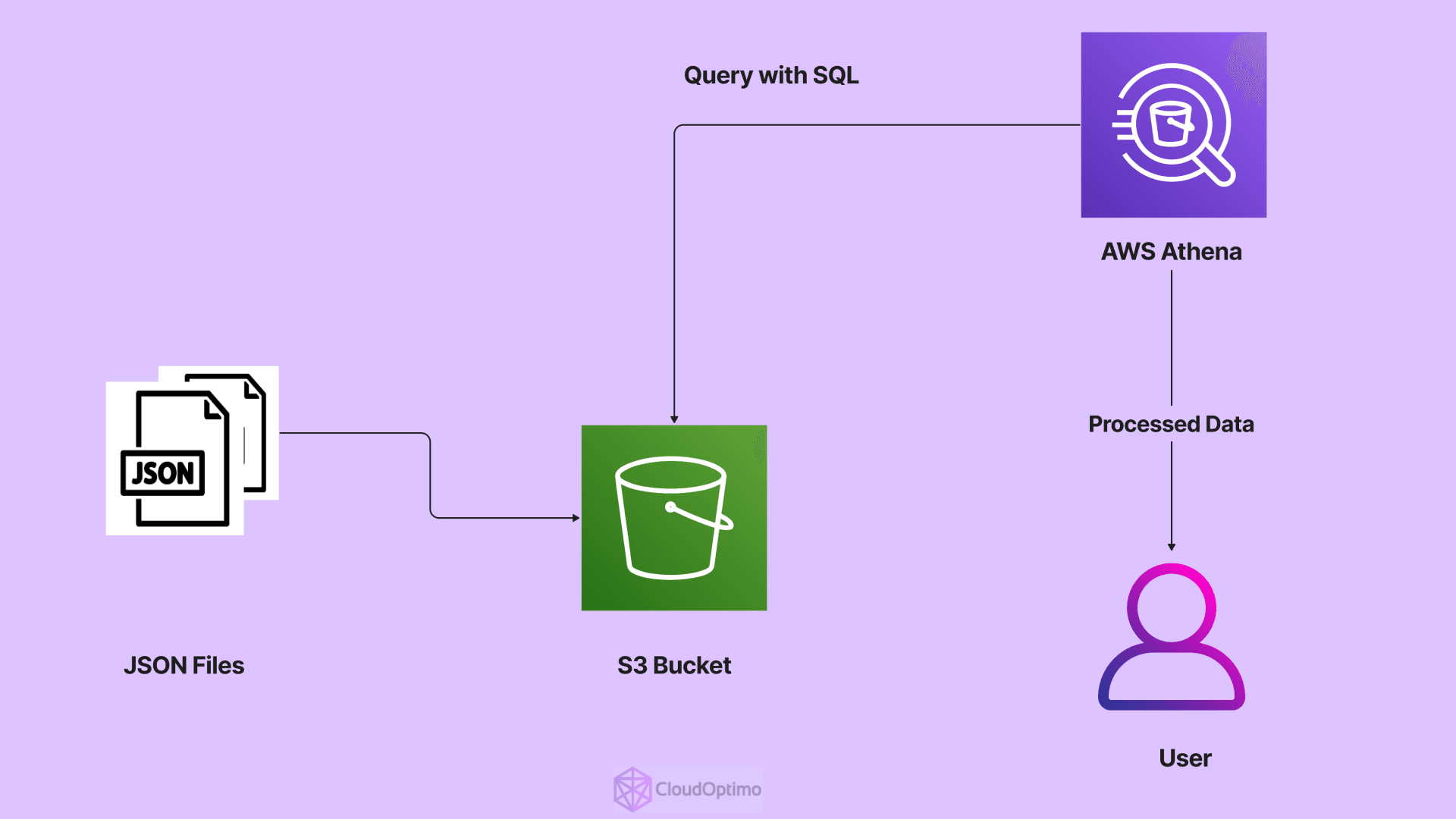
AWS Athena is a serverless, interactive query service designed for analyzing data stored in AWS S3. Imagine a vast data lake filled with information in various formats like CSV, Parquet, and ORC. Athena acts as a powerful search engine, allowing you to directly query this data lake using standard SQL. This eliminates the need for complex data warehousing or provisioning of servers.
Strengths of Athena
- Simplicity: One of Athena's biggest strengths is its user-friendliness. It boasts a straightforward web console and leverages familiar SQL syntax. This makes it accessible to a broad range of users, including data analysts, business intelligence (BI) professionals, and even those with limited coding experience. With Athena, you can start querying your data right away without needing to learn a new programming language.
- Cost-Effectiveness: Athena operates on a pay-per-query model, eliminating upfront infrastructure costs. You only pay for the resources consumed when you run queries. This makes it a budget-friendly option for exploratory data analysis or for scenarios with unpredictable usage patterns.
- Scalability: Athena is designed to handle large datasets efficiently. It automatically scales to accommodate complex queries and massive data volumes. This ensures smooth operation even when dealing with terabytes or petabytes of information. It can handle your data workloads without compromising performance.
- Performance: Athena is optimized for querying large datasets stored in columnar formats like Parquet. This translates to fast query execution times, enabling rapid insights generation.
- Security: Security is a top priority for any data storage and processing solution. Athena integrates seamlessly with AWS IAM. This allows for granular control over data access and permissions. You can define exactly who can access your data and what actions they can perform, ensuring the security and privacy of your sensitive information.
Ideal Use Cases for Athena
- Ad-hoc Analysis: Athena is perfect for exploratory data analysis and uncovering trends within your data lake.
- Data Exploration: Analysts can leverage Athena to slice and dice data, identify patterns, and gain a deeper understanding of their information assets.
- Business Intelligence (BI): Athena can be integrated with BI dashboards for real-time data visualization, enabling data-driven decision-making.
- Cost-Sensitive Workloads: For one-off queries or workloads with unpredictable usage patterns, Athena's pay-per-query model offers a cost-effective solution.
What is AWS Glue?
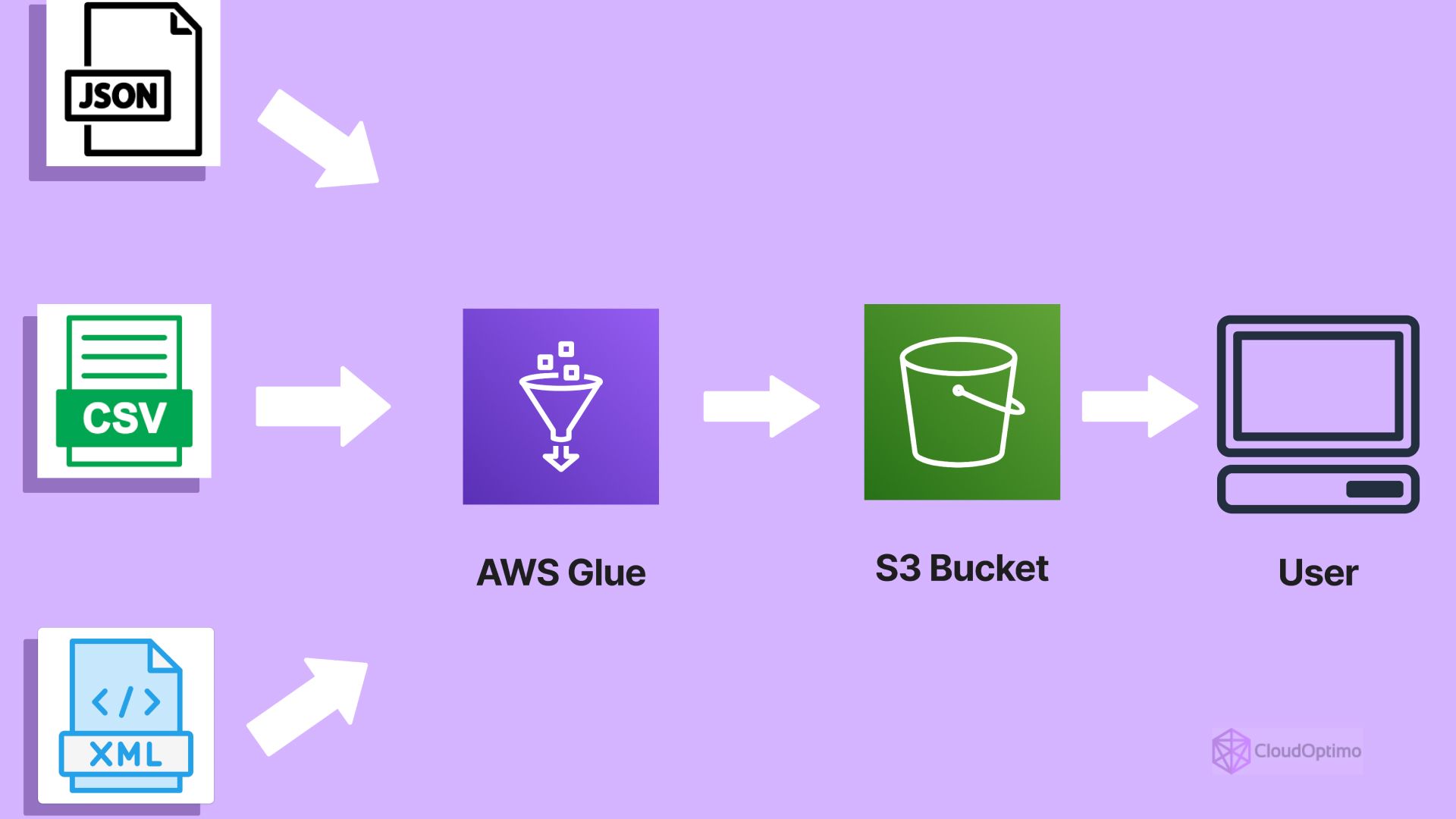
While Athena excels at interactive querying, AWS Glue is a fully managed ETL (Extract, Transform, Load) service. ETL processes involve extracting data from various sources, transforming it into a usable format, and loading it into a target data store. Glue simplifies these processes by providing a visual interface and pre-built components for data integration.
Strengths of Glue
- Data Integration: Glue excels at seamlessly integrating data from diverse sources. It can connect to relational databases, data streams, web crawls, and even legacy data formats. This makes it a powerful tool for bringing together data from various parts of your organization into a centralized location.
- ETL Workflows: Glue empowers users to create and orchestrate complex ETL workflows. It provides a drag-and-drop interface for building data pipelines, and Python scripting capabilities for more advanced transformations. This allows data engineers to automate the data preparation, ensuring consistency and efficiency.
- Data Transformation: Glue offers a rich library of built-in transforms for data cleansing, normalization, and feature engineering. Data cleansing involves removing errors and inconsistencies from the data. Normalization ensures that the data is structured consistently across different data sources. Feature engineering involves creating new data elements from existing ones to improve the effectiveness of machine learning models. With Glue's transformation capabilities, you can ensure your data is high-quality and ready for analysis.
- Apache Spark Integration: For large-scale data processing tasks, Glue leverages the power of Apache Spark, a popular open-source framework for large-scale data processing, ensuring efficient data manipulation. By integrating with Spark, Glue can handle complex data transformations and ETL workflows on massive datasets.
- Scalability: Just like Athena, Glue is designed to scale automatically. It can handle large data volumes and complex ETL workflows without compromising performance. This ensures that your data pipelines can keep pace with your growing data needs.
Ideal Use Cases for Glue
- Data Warehousing: Glue streamlines the process of building data warehouses from various data sources. A data warehouse is a central repository of structured data designed for analytics. Glue can help you extract data from various sources, transform it into a consistent format, and load it into your data warehouse, providing a clean and organized foundation for further analysis.
- Data Lake Management: Data lakes are large repositories of raw data in its native format. Glue can be used to define schemas, manage partitions, and enforce data quality rules within your data lake. Schemas define the structure of your data, partitions divide your data into manageable chunks, and data quality rules ensure that your data is accurate and consistent. By managing your data lake with Glue, you can ensure that your data is readily available and usable for Athena queries and other analytics tools.
- Machine Learning (ML) Data Preparation: Machine learning models require clean and well-structured data for optimal performance. Glue facilitates the preparation of data for machine learning models by handling data cleansing, feature engineering, and transformation tasks. Glue can help you ensure that your machine learning models have high-quality data to work with, leading to more accurate and reliable results.
- Complex ETL Workflows: When dealing with intricate data pipelines involving multiple data sources and transformations, Glue offers a robust and scalable solution. Glue's visual interface, pre-built components, and Python scripting capabilities make building and managing complex ETL workflows easier, even for those without extensive coding experience.
Athena and Glue Working Together
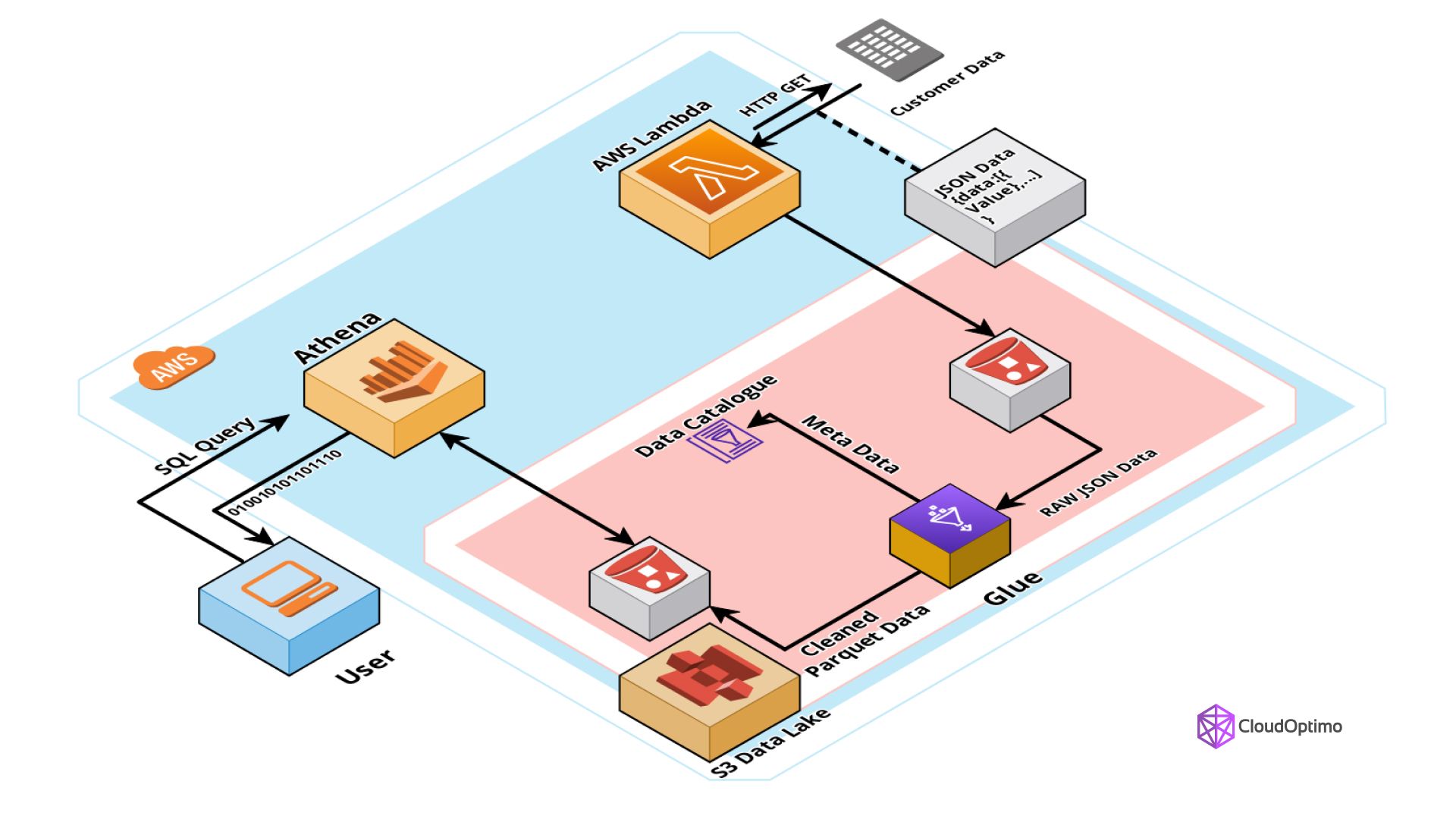
While Athena and Glue serve distinct purposes, they can be used together to create a powerful data analytics ecosystem. Here's how these services can complement each other:
- Glue Catalog as Schema Registry: Glue's Data Catalog can act as a central schema registry for your data lake. A schema registry is a repository that stores information about the structure of your data. Athena can leverage this schema information for accurate and efficient querying. By understanding the schema of your data, Athena can optimize query execution and return results faster.
- ETL Workflows for Optimized Athena Queries: Glue can be used to pre-process data and optimize its format for Athena. For instance, Glue can transform data into columnar formats like Parquet, which are more efficient for Athena to query. By optimizing the data format, Glue can significantly improve query performance within Athena, allowing you to get insights from your data faster.
- Data Lake Management for Athena: As mentioned earlier, Glue can be used to define schemas, manage partitions, and enforce data quality rules within the data lake. This ensures that data is readily available and usable for Athena queries. By maintaining a clean and organized data lake, Glue can streamline the data analysis process with Athena.
| Scenario | Description | Services Used |
| Optimizing Athena Query Performance | Pre-process data in Glue (e.g., transform to Parquet) to improve query speed in Athena | Glue (data transformation), Athena (data querying) |
| Building a Data Lake with Data Governance | Use Glue to define schema, manage partitions, and enforce data quality rules in the data lake | Glue (data lake management), Athena (data querying) |
| Data Exploration and Analysis Pipeline | Extract data from various sources with Glue, transform it, load it to S3, and then use Athena for interactive exploration and analysis | Glue (ETL), Athena (data querying) |
Real-world Scenarios
- E-commerce Customer Analysis
- Data Sources: Imagine you have data from various sources - web server logs (tracking customer behavior on your website), product data feed (containing product information), and customer purchase history (all stored in S3).
- Glue ETL Workflow: Glue orchestrates and performs the following tasks:
- Extracts: Glue retrieves data from each source mentioned above.
- Transforms: Glue cleanses the data by removing any errors or inconsistencies. It also transforms the data into a consistent format for analysis. For example, it might normalize product categories (e.g., grouping all shirts) for easier comparison.
- Loads: Finally, Glue loads the transformed and cleansed data into a designated S3 bucket, making it ready for Athena to analyze.
Athena Analytics: Data analysts can leverage Athena to query the transformed data in S3. They can analyze various aspects of customer behavior, such as:
- Identifying popular product combinations (e.g., what products are frequently bought together?)
- Understanding customer demographics (who are your typical customers?)
Insights from Athena can be used to:
- Optimize marketing campaigns by targeting specific customer segments.
- Personalize product recommendations based on past purchases.
- Financial Fraud Detection
- Data Sources: Imagine you have transaction data from your internal database, customer information, and even external fraud watchlists (maintained by third-party services).
- Glue ETL Workflow: Glue orchestrates :
- Extracts: Glue extracts from all the sources mentioned above.
- Transforms: Glue prepares the data for analysis by calculating transaction amounts, assigning risk scores based on pre-defined rules, and identifying suspicious transactions based on data quality checks.
- Loads: Finally, Glue loads the clean and transformed data set into S3.
Athena Analytics: Data analysts can now leverage Athena to query the transaction data in S3 and identify transactions with:
- Unusual patterns (e.g., a sudden surge in purchases from a new location)
- Amounts exceeding predefined thresholds.
A key advantage of Athena is its ability to join data from various sources. This allows analysts to create an overview of potential fraudulent activities. For instance, Athena can join transaction data with customer information and external watchlists to identify high-risk customers or flag transactions linked to known fraudulent activities.
Benefits of Using Glue and Athena Together
- Streamlined Data Analysis: Glue automates the data preparation tasks, saving you time and effort. Athena allows for quick and easy querying of the prepared data.
- Cost-Effective: Both Glue and Athena offer a serverless pay-per-query model, meaning you only pay for the resources you use.
- Scalability: They can handle massive datasets efficiently, making them ideal for organizations dealing with big data.
By leveraging Glue and Athena together, you gain a powerful combination for unlocking valuable insights from your data, ultimately leading to better decision-making in various real-world scenarios.
Choosing Between Athena and Glue
Now that you've seen how Athena and Glue work together to create a robust data analytics environment, let's see how choosing the right service for your specific needs works. This understanding will empower you to make informed decisions about your data analytics pipeline.
| Feature | Athena | Glue |
| Primary Use | Ad-hoc querying, data exploration, and cost-effective analysis of data in S3 | Building & managing ETL workflows, data transformation, data lake management |
| Data Sources | Primarily S3 data (CSV, JSON, Parquet, ORC, Avro) | Various sources (databases, data streams, web crawls, legacy data) |
| Data Processing | Limited; basic filtering and aggregations | Extensive transformations (cleansing, normalization, feature engineering) |
| Cost Model | Pay-per-query; ideal for unpredictable workloads or occasional use | May have fixed costs for running ETL jobs; consider frequent, complex workflows |
| Coding | Primarily SQL; user-friendly web console | May require Python scripting for complex transformations |
| Scalability | Scales automatically handle large datasets and queries | Scales to handle large data volumes and complex ETL workflows |
Here's a case-driven approach to guide your decision:
Scenario 1: Ad-hoc Exploration and Cost-Conscious Analytics
If your primary focus is querying data stored in S3 for quick insights and exploration, with cost-effectiveness as a major consideration.
- Ideal Choice: AWS Athena
- Reasoning: If your primary focus is querying data stored in S3 for quick insights and exploration, with cost-effectiveness as a major consideration, then AWS Athena is the ideal choice. Its serverless architecture and pay-per-query model eliminate upfront infrastructure costs and make it perfect for ad-hoc analysis. You only pay for the queries you run, making it a budget-friendly option for occasional data exploration needs.
Scenario 2: Building Scalable Data Pipelines and Data Transformation
For scenarios involving data ingestion from various sources, complex data transformations, and building robust data pipelines, AWS Glue is the better option.
- Ideal Choice: AWS Glue
- Reasoning: For scenarios involving data ingestion from various sources, complex data transformations, and building robust data pipelines, AWS Glue is the better option. Glue's ETL capabilities streamline data preparation and ensure data consistency for downstream analytics. Its visual interface and Apache Spark integration make it accessible to both data engineers and analysts, even for those without extensive coding experience.
Scenario 3: Combining Athena and Glue for a Comprehensive Data Analytics Pipeline
The true power of AWS lies in its ability to leverage multiple services together. A combination of Athena and Glue can create a robust data analytics pipeline:
- Data Ingestion and Transformation with Glue: Utilize Glue to build ETL workflows for extracting data from various sources, transforming it to a consistent format, and loading it into S3. Glue can handle complex data pipelines with ease, ensuring your data is prepared for analysis.
- Data Exploration and Analysis with Athena: Leverage Athena's interactive querying capabilities to explore the transformed data stored in S3. Analysts can gain insights through ad-hoc queries using familiar SQL syntax. Athena's web console and serverless architecture make it easy for users to get started with data exploration
- Data Visualization and Reporting: Integrate the results from Athena with data visualization tools like Amazon QuickSight to create reports and dashboards for deeper data exploration and communication of insights. Data visualization tools can transform raw data from Athena queries into charts, graphs, and other visual formats, making it easier to understand and share data insights with stakeholders.
Additional Considerations
Team Skills and Expertise
The choice between Athena and Glue can also depend on your team's skillset. If your team is comfortable with SQL, Athena might be a good fit. For building complex ETL workflows, expertise in data engineering and Apache Spark might be necessary, making Glue a better choice. Evaluate your team's skillset and choose the service that best aligns with their capabilities to ensure smooth adoption and efficient data management.
Data Volume and Query Complexity
Athena's pay-per-query model might incur higher costs for vast datasets or highly complex queries. For very large datasets or intricate queries, consider using a data warehouse service like AWS Redshift which is specifically designed for large-scale data analytics and may offer better cost performance for those specific use cases.
AWS Athena and AWS Glue are valuable tools for data analytics on AWS, each serving distinct purposes. By understanding their strengths and use cases, you can make an informed decision about which service best suits your specific data processing and analysis needs. Remember, the most powerful approach often lies in combining Athena and Glue to create a comprehensive data analytics pipeline that leverages the unique strengths of both services.
FAQs
Can I use Athena and Glue with data stored outside of AWS S3?
A: While both Athena and Glue primarily work with data stored in Amazon S3, there are ways to integrate them with external data sources. Glue can connect to relational databases, data streams, and even web crawls to extract data before loading it into S3 for further processing with Athena.
Can I use Athena and Glue independently for data analytics?
A: Yes, both Athena and Glue can be used independently. Athena excels at interactive querying of data stored in S3, while Glue focuses on data integration, transformation, and ETL workflows. However, using them together offers a more comprehensive and efficient data analytics solution.
What are the cost implications of using Athena and Glue?
A: Both Athena and Glue follow a pay-per-query model, meaning you only pay for the resources you use. This makes them cost-effective solutions, especially for Athena's ad-hoc analysis and Glue's occasional ETL jobs. However, for very large datasets or complex queries in Athena, consider a data warehouse service like Amazon Redshift for potentially better cost performance.
Do I need coding experience to use Athena and Glue?
A: Athena leverages familiar SQL syntax, making it accessible to users with basic SQL knowledge. Glue offers a visual interface for building ETL workflows, but some data transformation tasks might require Python scripting. For complex ETL processes, having data engineering expertise is beneficial.
What other AWS services can complement Athena and Glue for a data analytics pipeline?
A: Several AWS services can integrate with Athena and Glue to create a robust data analytics pipeline. Here are a few examples:
- Amazon QuickSight: A business intelligence service for data visualization and creating dashboards from Athena query results.
- Amazon SageMaker: A machine learning platform where Glue can prepare data for machine learning models.
- Amazon EMR: A managed Hadoop framework for large-scale data processing tasks that can complement Glue for specific use cases.
Are there any limitations to using Athena and Glue together?
A: While highly effective, there are a few limitations to consider. Athena might incur higher costs for very large datasets or intricate queries. Additionally, your team's skillset might influence the choice between Athena (favoring SQL proficiency) and Glue (requiring expertise in data engineering and Apache Spark for complex ETL workflows).






