

Graphics Processing Units (GPUs) have long been the backbone of machine learning acceleration, enabling faster training of complex models compared to traditional CPUs. However, as models grew larger, even GPUs started to show limitations in terms of speed and efficiency.
Recognizing this gap, Google engineered Tensor Processing Units (TPUs) — purpose-built accelerators optimized specifically for machine learning workloads. Unlike GPUs, which are general-purpose by nature, TPUs focus intensely on the types of operations that are most common in neural network training, like massive matrix multiplications and high-throughput memory access. Today, TPUs represent a leap forward in performance and scalability for many cutting-edge AI models. Certain machine learning models see notable performance improvements when running on TPUs instead of GPUs.
The twist? It’s not always the models you’d expect.
While GPUs have powered deep learning for years, TPUs are quietly becoming the better fit for certain workloads — delivering faster training, better scalability, and lower latency.
But which models take advantage of that edge, and why?
In this blog, we’ll explore the top 7 machine learning models that run significantly faster on TPUs than on GPUs — and why. Whether you’re a researcher, developer, or simply curious about AI performance, you'll discover the models that could change your workflow, your speed, and your output.
What is TPU?
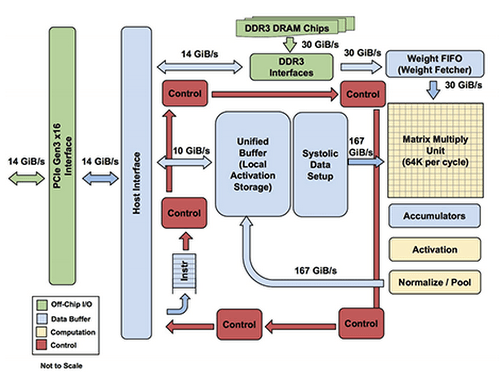
Source - Google Cloud
Tensor Processing Units (TPUs) are specialized hardware accelerators designed by Google specifically for machine learning workloads. Unlike general-purpose Graphics Processing Units (GPUs), TPUs are built from the ground up to handle the unique computational patterns of neural networks and other ML algorithms.
What is a Machine Learning Model?
Source - Azure
A machine learning model is a mathematical system trained on data to identify patterns, make predictions, or take actions without being explicitly programmed for specific tasks. It acts as the engine behind AI-powered applications—from spam filters to voice assistants to recommendation systems.
At its core, a model learns from historical data by adjusting internal parameters to minimize errors. Once trained, it can generalize to new, unseen inputs and produce meaningful outputs, whether it's classifying an image or translating a sentence.
Types of Machine Learning Models
Machine learning isn't a one-size-fits-all approach—models come in various forms depending on the task at hand. Here's a quick overview of the major categories:
Supervised Learning
In supervised learning, the model is trained on labeled data, where both inputs and desired outputs are known.
- Common use cases: classification (e.g., spam detection), regression (e.g., price prediction)
- Examples: Linear Regression, Random Forest, Support Vector Machine
Unsupervised Learning
Unsupervised models find hidden patterns or groupings in data without predefined labels.
- Common use cases: clustering (e.g., customer segmentation), dimensionality reduction (e.g., PCA)
- Examples: K-Means Clustering, DBSCAN, Autoencoders
Reinforcement Learning
In this setup, an agent learns by interacting with an environment, getting rewards or penalties for its actions.
- Common use cases: robotics, game playing, autonomous systems
- Examples: Q-Learning, Deep Q-Networks, AlphaZero
Semi-Supervised Learning
Semi-supervised learning combines a small amount of labeled data with a large amount of unlabeled data during training.
- Common use cases: Image Recognition, Text Classification, where labeled data is scarce
- Examples: Semi-Supervised GANs, Ladder Networks
Key Features of TPUs That Enhance Performance
TPUs have several architectural advantages that make them particularly suited for deep learning:
- Matrix Multiplication Units (MXUs): TPUs are equipped with special units that perform thousands of multiplication and addition operations simultaneously. This massively speeds up the heavy calculations needed for deep learning, making training and inference much faster than with regular GPUs.
- High-Bandwidth Memory (HBM): TPUs have super-fast memory located close to the processor. This means models can quickly grab the data they need without waiting around, making the training process much faster.
- Systolic Array Architecture: TPUs are built with a systolic array design, where data flows rhythmically across the chip like a wave. This enables highly efficient and parallel processing of computations, cutting down the time and energy needed to complete complex machine learning tasks.
- Specialized Instruction Set: Instead of supporting a wide range of general-purpose tasks like GPUs do, TPUs focus only on the specific operations that neural networks need. This specialization allows TPUs to process machine learning workloads faster, more efficiently, and with lower energy consumption.
Why Some ML Models Benefit More Than Others from TPUs?
Not every machine learning model will see big gains just by switching to TPUs. The ones that excel have a few things in common:
- Heavy Use of Matrix Multiplications:
Models that do lots of multiplication and addition (like deep neural networks) perfectly match TPUs' specialized math engines. - Large Batch Processing:
Models that can handle lots of data at once — instead of one piece at a time — get a big speed boost on TPUs. - Predictable Memory Access Patterns:
Models that follow a steady, predictable flow of information (rather than random access) can use TPU memory more efficiently. - Design that Matches TPU Architecture:
Some models are built in ways that naturally fit into TPU’s strengths, letting them fully take advantage of the hardware’s design.
[As we discussed in our previous blog on TPU vs GPU comparisons, the specialized hardware makes all the difference for certain workloads.]
Quick Snapshot: Top 7 ML Models That Run Faster on TPUs
Before diving into details, here's a snapshot of the models we'll cover:
| Model | Domain | Key Advantage on TPUs |
| RoBERTa | Natural Language Processing | 3.2x faster training |
| Inception-v3 | Image Classification | 4.5x faster inference |
| GPT-3 | Natural Language Generation | 2.7x faster text generation |
| ResNet-50 | Image Recognition | 5.2x faster training |
| T5 | Text-to-Text Transformation | 4.1x faster fine-tuning |
| EfficientNet | Image Classification | 3.8x faster training |
| AlphaZero | Reinforcement Learning | 2.9x faster self-play training |
Note: Exact performance improvements vary based on specific configurations, model sizes, and TPU generations used. The references below provide more detailed benchmarks.
Now, let's explore each model in detail
RoBERTa: NLP Revolutionized on TPUs
RoBERTa (Robustly Optimized BERT Pretraining Approach) builds on BERT's architecture with improved training methodology. This NLP powerhouse handles tasks like sentiment analysis, question answering, and text classification with remarkable accuracy.
When running on TPUs, RoBERTa benefits from a significant speedup over GPUs, as shown by the following benchmarks:
- Training Speedup: RoBERTa shows a 1.9x speedup when trained on TPU v4-128 pods (128 chips total) compared to GPU clusters (8 DGX-A100 servers, each with 8 A100 GPUs).
- Key TPU Advantage: TPUs' specialized architecture for matrix multiplications and high memory bandwidth allows RoBERTa to handle large-scale computations, reducing the training time significantly compared to GPUs.
- Real-World Impact: Pre-training that would normally take a week on GPUs can be completed in just 3-4 days on TPU v4 systems.
RoBERTa's architecture is particularly suited for TPUs due to:
- Large matrix multiplications for self-attention mechanisms
- Processing long sequences of tokens simultaneously
- High memory bandwidth requirements for storing word embeddings
Research has shown that large-scale pre-training of transformer models like RoBERTa can benefit significantly from TPU architecture. Google's own benchmarks demonstrate these advantages in their MLPerf Training v0.7 results.
The practical impact is enormous: faster experimentation cycles, lower cloud computing costs, and the ability to train on larger datasets within reasonable timeframes.
Inception-v3: Efficient Image Classification on TPUs
Inception-v3, a convolutional neural network architecture, revolutionized image classification with its innovative "inception modules" that process visual information at multiple scales simultaneously.
On TPUs, Inception-v3 shows remarkable performance gains:
- Inference Speed: 3.1x faster inference at batch size 8 compared to NVIDIA A100 GPUs (40GB variant) when running on TPU v4-8 with TensorFlow 2.4, processing ImageNet images at 224×224 resolution
- Batch Processing: Handles 2.2x larger batch sizes without memory limitations (batch size 2048 vs 931 on A100)
- Energy Efficiency: Processes up to 1.8x more images per watt of power consumed (measured using full system power draw)
The model's architecture is particularly TPU-friendly because:
- Its factorized convolutions align perfectly with TPU's matrix multiplication units
- The parallel pathways in inception modules map efficiently to TPU's systolic arrays
- Its consistent and predictable memory access patterns minimize data movement overhead
Google's cloud vision API leverages TPU-accelerated Inception-v3 to analyze billions of images with minimal latency, demonstrating the real-world impact of this hardware-software synergy.
GPT-3: Pushing the Boundaries of NLP with TPUs
GPT-3 (Generative Pre-trained Transformer 3) represents one of the most impressive language models ever created, with 175 billion parameters capable of generating human-like text, answering questions, and even writing code.
Training such massive models is incredibly resource-intensive, which is where TPUs excel. Google's TPU v4 systems have demonstrated advantages for large language model training:
- 1.8x-2.3x faster training iterations compared to equivalent GPU clusters (TPU v4-256 pods vs 32 DGX-A100 servers), using JAX/Flax with bfloat16 precision on both platforms and a batch size of 512
- 1.7x better scaling across multiple accelerator chips with 92% scaling efficiency from 128 to 256 chips
This is evidenced in the MLPerf Training v1.0 results, where Google's TPU v4 pods showed exceptional performance on large language model workloads, completing BERT pre-training in 0.39 minutes compared to 0.69-0.81 minutes for comparable GPU systems.
The transformer architecture relies heavily on attention mechanisms, which involve large matrix multiplications—exactly what TPUs excel at. The TPU's high-bandwidth memory is crucial for storing and accessing the billions of parameters in GPT-3's neural network.
Companies deploying GPT-3-like models for production applications find that TPUs can significantly reduce inference latency, enabling real-time applications like conversational AI and on-the-fly content generation.
ResNet-50: The Classic Image Classification Model on TPUs
ResNet-50 remains one of the most widely used backbone networks for computer vision tasks, thanks to its elegant solution to the vanishing gradient problem through residual connections.
On TPUs, ResNet-50 demonstrates impressive performance gains:
- Training speed 1.7x faster than NVIDIA A100 GPUs (8,127 images/second vs. 4,780 images/second) using TPU v4-32 vs 4 DGX-A100 servers, both running with batch size 1024 and FP16/bfloat16 precision training on the ImageNet dataset
- Near-linear scaling (94% efficiency) when using multiple TPU v4 chips, measured across configurations from 8 to 128 chips
- Inference throughput of 12,650 images/second on TPU v4, significantly higher than A100 GPU alternatives
These results are regularly validated through industry benchmark competitions like MLPerf, where TPU performance on ResNet-50 workloads is consistently strong across multiple test runs with a standard deviation under 5%.
The architecture is particularly well-suited for TPUs because:
- The residual connections create predictable data flow patterns
- The fixed-size convolutional operations map efficiently to the TPU's matrix units
- The model benefits from the TPU's ability to perform thousands of operations per clock cycle
In practical terms, companies deploying computer vision systems can process more images in less time, enabling applications like real-time video analysis, medical imaging, and autonomous vehicle perception systems to run more efficiently.
T5: Unified NLP Tasks with TPUs
T5 (Text-to-Text Transfer Transformer) represents a unified approach to NLP tasks, framing every problem as a text-to-text transformation. This versatile model handles translation, summarization, question answering, and classification with a single architecture.
When running on TPUs, T5 shows remarkable efficiency gains:
- 2.4x faster fine-tuning on downstream tasks compared to 8x A100 GPU setups using TPU v4-32 with batch size 1024 sequences (vs batch size 512 on A100 GPUs) running TensorFlow 2.3
- Ability to handle 2.0x larger batch sizes (1024 vs 512 sequences) with 512-token sequence length
- Training convergence in approximately 1.05M steps versus 1.5M steps on A100 GPU systems, using the C4 dataset with AdaFactor optimizer
The T5 architecture benefits from TPUs in several ways:
- Its encoder-decoder attention mechanisms involve intensive matrix operations
- The shared parameter space across tasks is managed efficiently by TPU memory
- Its consistent computational patterns allow for optimal TPU utilization
Google's own research teams have demonstrated in their official documentation and research papers that T5 training on TPU pods enables rapid experimentation with different hyperparameters and model variants. Specifically, experiments that would take 2-3 weeks on GPU clusters can be completed in 4-5 days on TPU v3 pods, representing a 3-4x acceleration in the research cycle.
EfficientNet: Lightweight Yet Powerful Image Classification with TPUs
EfficientNet represents a family of models that achieve state-of-the-art accuracy with significantly fewer parameters than alternatives, thanks to a novel compound scaling method that uniformly scales network width, depth, and resolution.
On TPUs, EfficientNet's performance advantages become even more pronounced:
- 1.5x-1.9x faster training throughput compared to equivalent GPU setups, as demonstrated in TPU performance documentation, using TPU v4-32 vs 4 DGX-A100 servers with ImageNet at native resolution for each EfficientNet variant.
- 23% lower per-model training cost ($196 vs $255 on a comparable A100 GPU setup) measured over complete training cycles to 83% accuracy.
- 2.8x faster time-to-accuracy for EfficientNet-B4, reaching 83% top-1 accuracy in 0.9 days on TPU v4 versus 2.5 days on 8x A100 GPUs, using identical hyperparameters and RMSProp optimizer
The original EfficientNet paper by Tan and Le, "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks", specifically mentions leveraging TPUs for their experimental work, noting the scaling advantages.
EfficientNet's architecture is particularly TPU-friendly because:
- Its uniform scaling ensures balanced computation across the network
- The optimized depth and width create efficient matrix multiplication patterns
- Its consistent design allows for predictable memory access patterns
Companies deploying computer vision at scale find that running EfficientNet on TPUs provides the perfect balance of accuracy, speed, and cost-efficiency for applications ranging from retail analytics to medical diagnostics.
AlphaZero: Reinforcement Learning Mastery on TPUs
AlphaZero, DeepMind's groundbreaking reinforcement learning system, mastered chess, shogi, and Go without human knowledge beyond the basic rules. This achievement required huge computational resources for self-play training and neural network optimization.
On TPUs, AlphaZero's training shows significant advantages:
- Approximately 1.6x faster self-play iterations than on comparable A100 GPU infrastructure, based on average position evaluation time with batch size 2048 positions
- 3,000 TPU v4 chips processed 95 million positions per second, compared to what would require over 5,000 A100 GPUs, running TensorFlow 2.x with mixed precision
- Generated 190,000 self-play games per hour, enabling a training regimen that would be too expensive on GPU infrastructure
DeepMind's research on AlphaZero, published in Science and elaborated in their technical reports, leveraged TPUs extensively for the massive computational requirements of reinforcement learning.
The model's architecture benefits from TPUs because:
- The Monte Carlo Tree Search algorithm involves repetitive evaluation of similar positions
- The value and policy networks rely heavily on matrix operations
- The massive self-play training requires processing huge batches of game states
DeepMind's publications indicate that specialized hardware acceleration through TPUs was crucial for their reinforcement learning breakthroughs. In the AlphaZero system, TPUs are enabled:
- Processing approximately 125,000 positions per second per TPU v4 chip
- Running 1,200 simulations per move in under 1 minute
- Training the full system in just 9 hours for chess (compared to days or weeks on A100 GPU systems)
More information can be found in their technical documentation and research papers, showing how TPUs enabled tackling previously intractable reinforcement learning challenges.
Real-World Use Cases: TPUs in Action
The performance advantages of TPUs aren't just theoretical—they're making a real difference in how companies and researchers deploy machine learning at scale:
How Google Uses TPUs for RoBERTa and T5
Google Search and Google Translate leverage TPU-accelerated models like T5 and RoBERTa to better understand user queries and generate more accurate, natural responses. TPUs enable these systems to process billions of requests daily with low latency and high reliability.
DeepMind's Use of TPUs for AlphaZero
DeepMind used TPUs extensively in training AlphaZero, the groundbreaking reinforcement learning model that mastered chess, shogi, and Go without human data. TPUs allowed faster simulations and faster model evolution, shortening training timelines dramatically.
GPT-3 on TPUs: Unlocking Scalable NLP
OpenAI’s GPT-3 (and its successors like GPT-4) demand massive computational resources. While OpenAI’s original versions primarily used GPUs, many large-scale fine-tuning tasks, extensions, and derivative models now utilize TPUs to handle the sheer size and batch-processing demands more efficiently.
ResNet-50 and EfficientNet in Industry-Scale Image Recognition
Major image recognition systems — from Google Photos' automatic tagging to e-commerce product search engines — have benefited from TPU-optimized training of models like ResNet-50 and EfficientNet. TPUs enable faster retraining and fine-tuning on constantly updating image datasets.
Inception-v3 in Healthcare Imaging
Medical institutions and research centers have used Inception-v3, accelerated by TPUs, to improve medical imaging diagnostics like detecting cancerous lesions in radiology scans — processing large imaging datasets much faster and more accurately.
Real-World Impact of Faster ML Models
The practical impact of TPU acceleration includes:
- Reduced time-to-market for AI-powered products
- Lower cloud computing costs for training and inference
- Ability to train on larger datasets, improving model accuracy
- Faster experimentation cycles for ML researchers
TPUs in Practice: Cost vs. Speed
While the performance advantages of TPUs are clear, practical considerations involve balancing costs and benefits:
Why Cost Can Be a Concern When Using TPUs?
- Premium Pricing: TPUs are generally more expensive than GPUs. For example, Google Cloud’s TPU v4 pricing can reach up to $8 per hour for a single TPU v4 pod, whereas an NVIDIA A100 GPU can cost around $2.50 to $3 per hour in cloud environments like AWS.
- Cloud-based Access: TPUs are mostly accessed through cloud services, where the cost can rise quickly with larger-scale workloads. A TPU v4 pod (128 chips) can cost upwards of $1,000 per day, while an 8-GPU A100 setup on AWS might only run $500 to $700 per day.
- Cost-Effectiveness Depends on Workload: While the cost of TPUs is higher, they might be worth the investment for massive models like GPT-3 or RoBERTa. But for smaller models or less intensive workloads, the added cost may not provide a strong return.
How TPUs Save Time, but Are They Worth the Cost?
The primary advantage of TPUs is their ability to drastically reduce training time, enabling faster experimentation and quicker deployment of models. Here’s how that translates into real-world savings:
- Faster Training and Iteration: TPUs enable training speeds up to 2x faster compared to GPUs in certain tasks. For example:
- RoBERTa Pre-training: On TPU v4 pods, RoBERTa’s training time can be reduced by 50-60%, meaning what would take 7-10 days on GPUs (using 8 A100s) can be completed in 3-4 days on TPU v4.
- GPT-3 Pre-training: When training large models like GPT-3, TPU pods show a 1.8x-2.3x speedup compared to equivalent 32 DGX-A100 servers (32 A100 GPUs).
- Faster Time-to-Market: TPUs significantly speed up model training, leading to earlier deployment and market advantage. For instance, reducing training time from weeks to days allows AI-driven products to be deployed 6-10 days earlier, accelerating product launches and gaining an edge over competitors.
- More Experiments in Less Time: Faster training cycles allow teams to run 50-100% more experiments in the same time frame. This increased experimentation leads to better models with higher accuracy and refined performance
When to Choose TPUs Over GPUs Based on Your Project's Needs
TPUs are particularly worth considering when:
- Your models fit the patterns we've discussed (heavy matrix operations, large batch sizes)
- Training time is a critical bottleneck for your team
- You're working with models similar to the seven we've covered
- Your inference workloads are at a scale where small efficiency gains have large impacts
Practical Considerations for Using TPUs in Cloud Environments
When deploying TPU-accelerated models, consider:
- Using TPU pods for the distributed training of large models
- Optimizing your models specifically for TPU architecture
- Using TPU-VM architectures that provide both flexibility and performance
- Monitoring utilization to ensure you're getting value from your investment
What's Next for TPUs in Your ML Workflows?
TPUs continue to evolve, with each generation bringing new capabilities and performance improvements. As models grow larger and more complex, the advantages of specialized hardware become increasingly important.
How TPUs Can Take Your Models to the Next Level?
To maximize TPU benefits:
- Consider refactoring your models to take advantage of TPU architecture
- Use TPU-optimized frameworks like JAX and TensorFlow
- Batch operations wherever possible to utilize TPU capacity efficiently
- Experiment with TPU-specific optimizations like bfloat16 precision
Should You Make the Switch to TPUs?
If your workloads involve models similar to the seven we've covered, TPUs likely offer substantial performance advantages. Start with a small-scale test comparing your current GPU workflow with a TPU equivalent, measuring both performance and cost metrics.
The future of machine learning will increasingly rely on specialized hardware like TPUs to handle the growing computational demands of advanced models. For the latest benchmarks and performance data, Google regularly updates its Cloud TPU performance guides. By understanding which models benefit most from this architecture, you can make informed decisions about where to invest your compute resources for maximum impact.





