

1. Introduction
1.1 What is Cloud Data Warehousing?
Cloud data warehousing refers to a scalable, managed environment for storing and querying structured or semi-structured data in the cloud. Unlike traditional on-premises data warehouses, which require fixed hardware and manual scaling, cloud-based solutions offer elasticity, pay-per-use pricing, and integration with a broad set of analytics and machine learning tools. These platforms decouple storage from compute, allowing organizations to scale resources independently based on workload demands.
The evolution of cloud data warehousing has enabled organizations to handle larger volumes of data, reduce operational overhead, and support real-time analytics. Services like Azure Synapse Analytics and Google BigQuery exemplify this shift, offering serverless architectures, built-in ML capabilities, and deep integration with their respective cloud ecosystems.
| Era | Time Period | Technology / Platform | Description |
| Mainframe & Early Data Warehousing | 1980s – Early 1990s | IBM DB2, IMS, Oracle RDBMS | Early relational databases used for storing and querying structured business data. |
| Traditional On-Premise Data Warehousing | Mid 1990s – 2010 | Teradata, Netezza, IBM DB2 Warehouse, Oracle Exadata | Purpose-built data warehouse appliances offering MPP (Massively Parallel Processing). |
| Early Cloud & Hybrid Models | 2010 – 2015 | Amazon Redshift (2012), HP Vertica, Greenplum | Initial wave of cloud or hybrid-architecture data warehouses. Lift-and-shift model. |
| Cloud-Native Data Warehousing Emerges | 2015 – 2018 | Google BigQuery, Azure SQL Data Warehouse (later Synapse) | Cloud-native architectures with serverless scaling, decoupled storage/compute. |
| Modern Cloud Data Warehousing & Lakehouse | 2018 – Present | Snowflake, Databricks Lakehouse, Azure Synapse Analytics, BigQuery Omni | Unified analytics platforms, support for structured + semi-structured data, AI/ML integration. |
1.2 Why Compare Azure Synapse and BigQuery?
Azure Synapse Analytics and Google BigQuery are two of the most advanced cloud data warehouse platforms available today. Both aim to simplify data processing, analytics, and visualization at scale, but they differ significantly in architecture, pricing models, integration patterns, and performance optimizations.
A direct comparison helps organizations make informed decisions based on their existing cloud investments, data strategy, and workload types. Whether the goal is to modernize a legacy data warehouse or to build a greenfield analytics platform, understanding these differences is critical to aligning with technical and business requirements.
1.3 Who Should Read This Blog?
This blog is tailored for the following audiences:
- Data Engineers evaluating cloud warehouse features, performance, and pipeline support.
- Solutions Architects assessing platform fit for enterprise data ecosystems.
- Data Analysts and Scientists comparing SQL capabilities, integration with notebooks, and ML tooling.
- Technical Decision-Makers and IT Leaders looking to optimize cost, performance, and long-term platform strategy.
2. Overview of the Platforms
2.1 What is Azure Synapse Analytics?
Azure Synapse Analytics is a unified analytics platform developed by Microsoft. It combines big data and data warehousing capabilities, integrating with Azure Data Lake Storage, Power BI, and Azure Machine Learning. Synapse supports both dedicated SQL pools (formerly SQL Data Warehouse) and serverless SQL pools, offering flexibility between provisioned and on-demand compute.
It provides a development environment—Synapse Studio—which allows data exploration, pipeline development, and notebook-based workflows from a single interface.
2.2 What is Google BigQuery?
Google BigQuery is a fully-managed, serverless data warehouse offered as part of Google Cloud Platform (GCP). It abstracts infrastructure management entirely, focusing on rapid SQL-based analytics over massive datasets. BigQuery is built on Dremel, a columnar execution engine optimized for high-throughput, distributed queries.
It supports automatic scaling, storage separation, and a flat-rate or on-demand pricing model. BigQuery also offers integrations with Looker, Dataflow, and Vertex AI for extended analytics and machine learning capabilities.
2.3 Core Architecture Summary
While both platforms are built for scalable analytics, their underlying architectures are distinct.
| Feature | Azure Synapse Analytics | Google BigQuery |
| Compute Model | Dedicated & Serverless SQL pools | Fully Serverless |
| Storage Engine | Azure Data Lake Gen2 | Colossus (GCP distributed file system) |
| SQL Support | T-SQL, Spark SQL | ANSI Standard SQL |
| Execution Engine | MPP-based (dedicated), Spark engine | Dremel (columnar, distributed) |
| Integration | Power BI, Azure ML, Azure Data Factory | Looker, Vertex AI, Dataflow |
| Pricing Model | Provisioned + Serverless (per-query) | On-demand (per-query) or Flat-rate |
3. Architecture Comparison
3.1 Compute and Storage Decoupling
Both Synapse and BigQuery decouple compute from storage, allowing them to scale independently. In Synapse, storage resides in Azure Data Lake Storage Gen2, while compute is either provisioned or on-demand SQL pools. In BigQuery, storage uses Google’s Colossus distributed file system, and compute is fully serverless, managed by the Dremel engine.
The decoupling improves elasticity and supports cost optimization, especially for sporadic workloads or multi-tenant environments.
3.2 Serverless vs Dedicated Models
BigQuery offers a pure serverless model, where users are billed based on the volume of data scanned per query, or via flat-rate pricing for consistent workloads. There is no infrastructure to provision or manage.
In contrast, Synapse offers a hybrid model. Users can provision dedicated SQL pools with fixed compute resources or leverage serverless SQL pools that scale based on query usage. This provides flexibility but adds complexity in resource management and capacity planning.
3.3 Distributed Query Processing
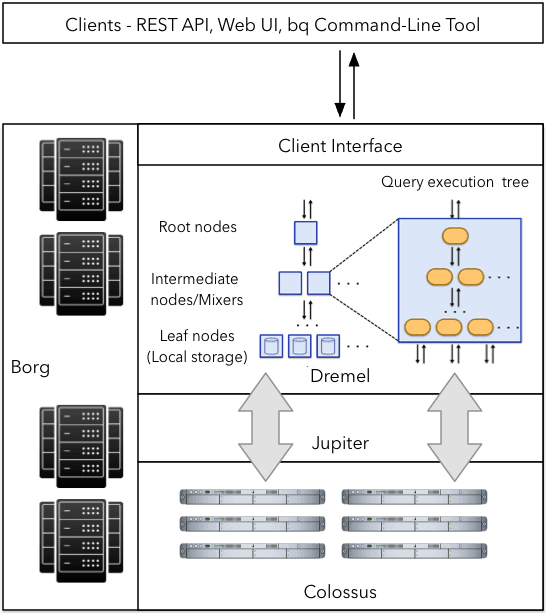
Source: Medium
BigQuery uses the Dremel execution engine, which performs multi-level tree aggregation for highly parallelized, columnar query execution. This allows it to efficiently scan terabytes to petabytes of data with sub-second latency for well-optimized queries.
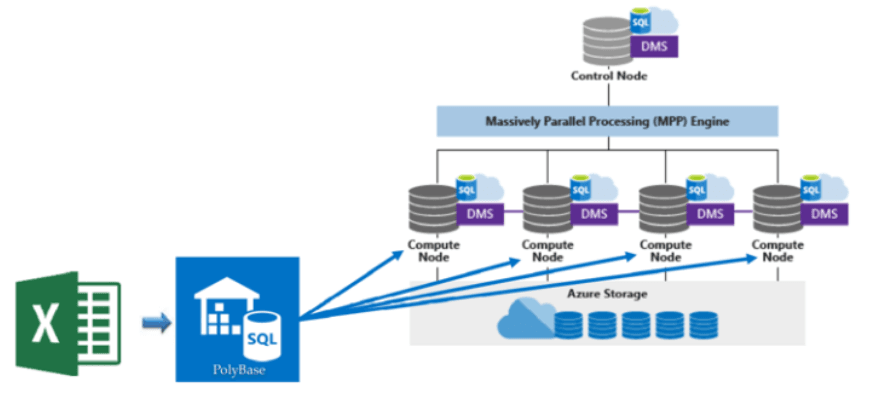
Source: Linkedin
Synapse uses a Massively Parallel Processing (MPP) engine for dedicated SQL pools and Spark for big data workloads. It distributes data across compute nodes and processes it in parallel, though performance depends more heavily on table distribution, indexing, and tuning.
4. Performance and Scalability
4.1 Query Optimization Techniques
BigQuery automatically optimizes queries via predicate pushdown, column pruning, and materialized views. It also supports automatic rewriting of queries using AI to improve performance. However, query performance is tightly linked to table partitioning and clustering strategies.
Synapse allows more manual control through indexing, distribution keys, and statistics management. Users can tune performance by managing resource classes and adjusting parallelism for dedicated SQL pools.
4.2 Data Partitioning and Clustering
Partitioning is crucial in both platforms for controlling data scan costs and query performance. BigQuery supports partitioning by ingestion time or column values and clustering by up to four fields. This enhances filter performance and reduces the amount of data scanned.
Synapse allows horizontal partitioning via table partitioning schemes and distribution types (hash, round robin, replicated). For dedicated pools, choosing the correct distribution key is critical for reducing data movement and improving join performance.
| sql -- BigQuery: Create a partitioned and clustered table CREATE TABLE dataset.sales ( sale_date DATE, region STRING, product STRING, revenue FLOAT64 ) PARTITION BY sale_date CLUSTER BY region, product; -- Synapse: Create a distributed table CREATE TABLE dbo.sales ( sale_date DATE, region NVARCHAR(50), product NVARCHAR(50), revenue FLOAT ) WITH ( DISTRIBUTION = HASH(region), CLUSTERED COLUMNSTORE INDEX ); |
4.3 Auto-Scaling and Concurrency
BigQuery handles scaling automatically, with virtually no concurrency limits for standard workloads. Queries are isolated and scheduled across shared compute resources without explicit intervention.
Synapse's serverless pools scale automatically, but dedicated SQL pools have limits based on the provisioned performance tier (DWU). High concurrency can lead to queued queries if capacity isn’t sufficient, requiring planning or scaling.
5. Data Integration and ETL/ELT Support
5.1 Native Integration with Other Services
Azure Synapse integrates natively with Azure Data Factory (ADF), which enables drag-and-drop data pipeline creation and orchestration for ETL and ELT workflows. Within Synapse Studio, ADF pipelines are embedded, allowing users to perform data movement, transformations, and scheduling from a single UI. Additionally, Synapse connects directly to Azure Data Lake Storage, Azure Cosmos DB, and Microsoft Purview for cataloging.
Google BigQuery integrates with Cloud Dataflow (Apache Beam-based) for real-time and batch data processing, Cloud Composer for orchestration (Airflow-based), and BigQuery Data Transfer Service (DTS) for scheduled imports from external sources such as Google Ads, YouTube, and Salesforce. These services allow tight integration within GCP’s data ecosystem without managing infrastructure.
5.2 Support for Third-party ETL Tools
Both platforms support a wide array of third-party data integration tools. Azure Synapse can connect to Informatica, Talend, Matillion, Apache Nifi, and more. These tools can use Synapse connectors or push data via JDBC/ODBC.
BigQuery is compatible with tools like Fivetran, Stitch, Talend, Apache Nifi, and dbt. Many providers offer native BigQuery connectors or utilize BigQuery’s REST API for high-throughput data loading. BigQuery’s support for streaming APIs also enables ingestion pipelines from Kafka and other message brokers via intermediate tools.
5.3 Streaming Data and Real-time Ingestion
Synapse supports near real-time data ingestion via Azure Stream Analytics and Event Hubs, with the data landing in Azure Data Lake or directly into Synapse tables through pipelines. However, Synapse is better suited for micro-batch over ultra-low-latency workloads.
BigQuery supports real-time ingestion through its streaming API, allowing data to be appended to tables with sub-second latency. It also integrates seamlessly with Pub/Sub, Dataflow, and Kafka connectors, making it highly suitable for event-driven architectures and operational analytics.
6. Data Storage and Formats
6.1 Supported File Formats (Parquet, ORC, JSON, etc.)
Both platforms support industry-standard data formats for ingestion and querying:
- Azure Synapse supports Parquet, ORC, Avro, CSV, JSON, and Delta Lake when used with Spark pools. It is optimized for reading columnar formats such as Parquet.
- BigQuery supports Parquet, ORC, Avro, CSV, JSON, and Cloud Datastore backups. Native support for columnar formats improves performance and reduces scan costs.
These formats can be accessed via external tables or loaded into native table formats for optimized querying.
6.2 Storage Costs and Tiers
Azure Synapse storage costs are tied to Azure Data Lake Storage Gen2, which offers a tiered pricing model (Hot, Cool, Archive). Users pay for storage separately from compute, and cold storage is suitable for infrequently accessed historical data.
BigQuery uses Colossus, GCP’s distributed storage, and offers two tiers:
- Active storage, billed per GB per month.
- Long-term storage, automatically applied after 90 days of no changes, with lower rates.
| Feature | Azure Synapse | Google BigQuery |
| Storage Backend | Azure Data Lake Gen2 | Colossus |
| Format Support | Parquet, ORC, JSON, Avro, Delta | Parquet, ORC, JSON, Avro |
| Tiered Pricing | Yes (Hot, Cool, Archive) | Yes (Active, Long-term) |
| Cost (est.) per TB/month | ~$20–$23 (Hot Tier) | ~$20 (Active), ~$10 (Long-term) |
6.3 External Table Support
Both platforms support querying data in-place without full ingestion:
- Synapse supports external tables using PolyBase or Spark. Data can be queried from Azure Blob Storage or Data Lake in supported formats like Parquet or CSV.
- BigQuery allows external querying via Federated Tables, supporting Cloud Storage, Google Drive, and Cloud Bigtable. It supports predicate pushdown for efficient access in external sources.
This feature is particularly useful for data lake architectures and hybrid storage strategies.
7. Security and Compliance
7.1 Identity and Access Management (IAM)
Azure Synapse uses Azure Active Directory (AAD) for authentication and role-based access control (RBAC). Permissions are granular and include workspace-level, SQL pool-level, and object-level security (e.g., row-level and column-level security).
BigQuery uses Google Cloud IAM, supporting fine-grained access control at the project, dataset, and table level. BigQuery also supports authorized views, allowing masked or filtered views of sensitive data without exposing the underlying dataset.
7.2 Data Encryption (At Rest & In Transit)
Both platforms enforce encryption by default:
- Synapse encrypts data at rest using Azure Storage Service Encryption (SSE) and in transit via TLS. It supports customer-managed keys (CMK) and double encryption for added security.
- BigQuery encrypts data at rest with AES-256 and in transit using TLS 1.2+. Users can opt for customer-managed encryption keys (CMEK) or customer-supplied keys (CSK).
7.3 Compliance Standards (HIPAA, GDPR, etc.)
Both services meet a wide range of compliance standards:
- Azure Synapse is certified for HIPAA, GDPR, ISO 27001, SOC 1/2/3, and FedRAMP.
- BigQuery is certified for HIPAA, GDPR, ISO 27001, SOC 1/2/3, and FedRAMP High.
8. Pricing and Cost Optimization
8.1 Pricing Models: On-demand vs Provisioned
- Azure Synapse offers two pricing models:
- Dedicated SQL pools: charged by provisioned DWUs (Data Warehouse Units).
- Serverless SQL pools: billed per TB of data processed.
- BigQuery has:
- On-demand pricing: billed per TB of data scanned.
- Flat-rate pricing: fixed monthly cost for reserved slots (compute capacity).
The right model depends on query volume and workload predictability.
8.2 Cost Estimation Examples
For a simple analytical workload querying 1 TB of data daily:
| Scenario | Azure Synapse (Serverless) | BigQuery (On-demand) |
| Data Scanned per Day | 1 TB | 1 TB |
| Cost per TB | ~$5 | ~$5 |
| Monthly Estimate (30 days) | ~$150 | ~$150 |
For dedicated capacity:
| Platform | Capacity | Monthly Cost (est.) |
| Synapse (DWU1000) | Dedicated SQL | ~$6,000 |
| BigQuery (100 slots) | Flat-rate | ~$2,000 |
8.3 Best Practices for Cost Control
- Partition and cluster large tables to reduce scan volume.
- Use materialized views for frequently queried data.
- Monitor and alert on query costs using built-in dashboards.
- In BigQuery, preview queries before running, and use slot reservations for predictable workloads.
- In Synapse, scale DWUs dynamically and pause unused pools to avoid unnecessary charges.
9. Monitoring, Logging, and Observability
9.1 Built-in Monitoring Tools (Synapse Studio vs Cloud Console)
Azure Synapse Studio includes integrated monitoring tools to track query performance, resource usage (DWUs), and pipeline executions. It provides visual dashboards for:
- Query history and duration
- SQL pool utilization
- Data movement within pipelines
Google Cloud Console provides BigQuery Monitoring, which displays:
- Query execution time
- Slot utilization (for flat-rate pricing)
- Interactive dashboards with execution graphs and latency metrics
9.2 Integration with Logging Systems (Azure Monitor vs Stackdriver)
Azure Monitor is natively integrated with Synapse. It captures:
- SQL diagnostics and activity logs
- Pipeline metrics (success/failure)
- Custom log-based metrics through Log Analytics
BigQuery integrates with Cloud Logging (formerly Stackdriver). Logs include:
- Query execution details
- Job failures
- Resource usage patterns
Both systems support exporting logs to storage or third-party tools (e.g., Splunk, Datadog) for centralized analysis.
9.3 Alerting and Usage Analytics
- Azure Synapse supports alerting via Azure Monitor alerts, which can trigger emails, webhooks, or automation (e.g., Logic Apps) when thresholds are exceeded.
- BigQuery allows usage-based alerting using Cloud Monitoring metrics, such as data scanned per query or slot utilization.
For usage analytics, both platforms integrate with:
- Power BI / Looker for visualizations
- APIs for custom dashboards or billing forecasts
10. Developer and SQL Experience
10.1 Query Syntax and SQL Variants
Azure Synapse primarily uses T-SQL, which will be familiar to SQL Server users. It supports:
- Window functions
- Common table expressions (CTEs)
- Index hints and distribution strategies (in dedicated pools)
Google BigQuery uses Standard SQL, a dialect based on ANSI SQL. It also supports:
- Array and struct data types
- JSON functions
- User-defined functions (UDFs) in SQL and JavaScript
| sql -- Azure Synapse T-SQL SELECT region, SUM(sales) AS total_sales FROM dbo.sales_data WHERE sale_date >= '2023-01-01' GROUP BY region; -- BigQuery Standard SQL SELECT region, SUM(sales) AS total_sales FROM `project.dataset.sales_data` WHERE sale_date >= '2023-01-01' GROUP BY region; |
10.2 Notebooks and Development Interfaces
Synapse Studio includes Apache Spark notebooks that support Python, Scala, and .NET. These notebooks are ideal for big data transformation and ML workflows. They can be scheduled as part of pipelines.
BigQuery integrates with Colab, Vertex AI Workbench, and Jupyter. Users can run SQL, Python, or use magic commands (%%bigquery) directly in notebooks.
Both support GitHub integration and extensions for VS Code and IntelliJ, enabling CI/CD workflows.
10.3 Programming Language Support (Python, Java, etc.)
| Language | Azure Synapse | Google BigQuery |
| Python | Spark pools, SynapseML | BigQuery Python SDK, Colab, Vertex AI |
| Java | JDBC/ODBC support | Java client library, UDFs |
| .NET | .NET SDK, ADF pipelines | .NET client support |
| Go, Node.js | Via REST APIs | Native libraries |
Developers can use REST APIs, client libraries, and ODBC/JDBC drivers to interact with both platforms programmatically.
11. Ecosystem and Tooling
11.1 Integration with BI Tools (Power BI, Looker, etc.)
- Azure Synapse integrates natively with Power BI, allowing live dashboards and semantic models via DirectQuery.
- BigQuery integrates seamlessly with Looker, Data Studio, Tableau, Qlik, and more.
Both platforms support ODBC/JDBC connectors, enabling BI connectivity regardless of vendor.
11.2 Machine Learning and AI Capabilities
- Synapse offers SynapseML, a scalable machine learning library built on Apache Spark. Users can train models in notebooks and integrate them into pipelines.
- BigQuery provides BigQuery ML, which allows users to train, evaluate, and deploy ML models using only SQL. Supported models include linear regression, logistic regression, time-series forecasting, and deep neural networks via TensorFlow integration.
BigQuery also integrates with Vertex AI, GCP’s full-fledged ML platform, while Synapse can connect to Azure Machine Learning services.
11.3 Marketplace and Community Support
- Azure Marketplace offers templates for Synapse pipelines, datasets, and connectors.
- GCP Marketplace provides BigQuery public datasets, ML models, and community-built UDFs.
Community support is strong for both, with active forums, Stack Overflow presence, GitHub repos, and regular feature updates driven by feedback.
12. Use Cases and Industry Adoption
12.1 Common Use Cases (Analytics, ML, Reporting)
| Use Case | Azure Synapse | Google BigQuery |
| Enterprise Reporting | ✅ Deep Power BI integration | ✅ Built-in BI Engine |
| Machine Learning | ✅ Spark + SynapseML | ✅ BigQuery ML + Vertex AI |
| Real-time Analytics | ✅ Event Hubs + Stream Analytics | ✅ Pub/Sub + Streaming API |
| Data Lakehouse | ✅ Delta Lake with Spark | ✅ Federated queries + external tables |
12.2 Customer Success Stories
- Azure Synapse: Used by Heathrow Airport for operational analytics and Marks & Spencer for customer personalization at scale.
- BigQuery: Adopted by Spotify for music analytics and The Home Depot for inventory forecasting and digital transformation.
These case studies reflect the platforms’ maturity and ability to scale to petabyte-scale workloads in production.
12.3 Industry-specific Fit
| Industry | Azure Synapse Highlights | BigQuery Highlights |
| Finance | Integration with Dynamics, fine-grained RBAC | Real-time fraud detection, native encryption |
| Healthcare | HIPAA-ready, integrates with HL7, FHIR | Genomic data processing, AI-driven insights |
| Retail | ADF for complex pipelines, Power BI | Real-time demand forecasting, Pub/Sub |
| Manufacturing | IoT ingestion via Event Hubs | Time-series analysis, predictive maintenance |
13. Pros and Cons
13.1 Azure Synapse Pros and Cons
Azure Synapse offers a unified environment for data integration, analytics, and orchestration, particularly beneficial for enterprises already within the Microsoft ecosystem. However, its hybrid approach of serverless and dedicated pools introduces complexity in cost and performance tuning.
| Pros | Cons |
| Tight integration with Microsoft services (Power BI, ADF, Purview) | Higher complexity in managing dedicated SQL pools |
| Built-in orchestration via Synapse Pipelines | Less mature serverless performance compared to BigQuery |
| Supports multiple compute engines (T-SQL, Spark, Data Explorer) | Longer startup time for Spark workloads |
| Granular security with AAD, RBAC, and fine-grained data controls | UI and experience can feel less polished compared to BigQuery |
| Strong fit for enterprise and batch ETL-heavy environments | Requires manual scaling and tuning in dedicated mode |
13.2 BigQuery Pros and Cons
Google BigQuery excels in simplicity, performance, and serverless scalability. It enables rapid time-to-value for data analytics projects with minimal infrastructure overhead, but has limitations in terms of advanced workload orchestration and compute customization.
| Pros | Cons |
| Fully serverless with automatic scaling and resource allocation | Limited customization of compute resources |
| Excellent performance for ad-hoc and high-concurrency workloads | Flat-rate pricing requires upfront planning for slot reservation |
| Tight integration with AI/ML services like Vertex AI and BigQuery ML | Less control over query execution plans and tuning |
| Seamless real-time ingestion with Pub/Sub and streaming API | UI lacks native pipeline orchestration—requires external tools |
| Lower operational overhead and strong cost efficiency for queries | Complex transformations may require using Dataflow or external tools |
14. Decision Criteria and Recommendations
14.1 When to Choose Synapse
Choose Azure Synapse Analytics if:
- You're operating in a Microsoft-centric environment and need native integration with Power BI, Azure Data Factory, and Active Directory.
- You require complex ETL orchestration and want an end-to-end data integration platform under one interface.
- Your use case involves large-scale batch data processing or integration with Apache Spark-based machine learning workflows.
- You need fine-grained security and compliance features suitable for regulated industries (e.g., government, finance).
14.2 When to Choose BigQuery
Choose Google BigQuery if:
- Your workloads are query-centric, unpredictable, or bursty, and you benefit from fully serverless architecture.
- You need real-time analytics, with strong integration with Pub/Sub, Dataflow, and BigQuery Streaming API.
- You're aiming to quickly deliver value without infrastructure management.
- You want to integrate analytics seamlessly with Vertex AI, Looker, or BigQuery ML for AI-driven insights.
- You have high concurrency requirements or multi-team access to the same datasets.
14.3 Hybrid/Multi-Cloud Considerations
In hybrid or multi-cloud setups, interoperability becomes key:
- Azure Synapse can consume external data from AWS S3 or GCP via data pipelines and Spark connectors.
- BigQuery Omni (GCP’s cross-cloud analytics service) allows users to query data across AWS and Azure using the same BigQuery interface.
In both cases, consider vendor lock-in, data egress costs, and identity management across clouds. For multi-cloud strategies:
- Use open file formats (Parquet, Avro) and external table definitions.
- Implement centralized IAM using federated identity providers (e.g., Okta, Azure AD).
- Align on data governance policies and metadata catalogs that span cloud boundaries.






