

Increased volume, variety, and velocity of data have exceeded traditional management approaches, creating bottlenecks that restrict innovation and growth. Amazon Data Zone is a powerful solution specifically designed to meet these modern data management challenges.
Let's explore how this platform is revolutionizing the way organizations discover, govern, and share their data.
The Growing Complexity of Data
Modern enterprises generate and consume massive amounts of data across departments, applications, and cloud environments. This data comes in various formats—structured, semi-structured, and unstructured—and resides in multiple locations, from on-premises databases to cloud storage. As organizations grow, so does the complexity of their data landscape.
Data teams increasingly struggle with fundamental questions: Where is our data? Who has access to it? How fresh is it? Is it reliable? Without clear answers, organizations face significant obstacles to becoming truly data-driven.
Why Traditional Solutions Fall Short
Legacy data management tools were designed for simpler times when data volumes were smaller and lived primarily in centralized databases. These tools typically focus on specific aspects of data management rather than providing comprehensive solutions. They often require specialized technical knowledge, creating bottlenecks where IT departments become overwhelmed with requests for data access and integration.
As a result, organizations find themselves with disjointed tools, inconsistent governance practices, and frustrated business users who can't easily find or use the data they need.
What is Amazon Data Zone?
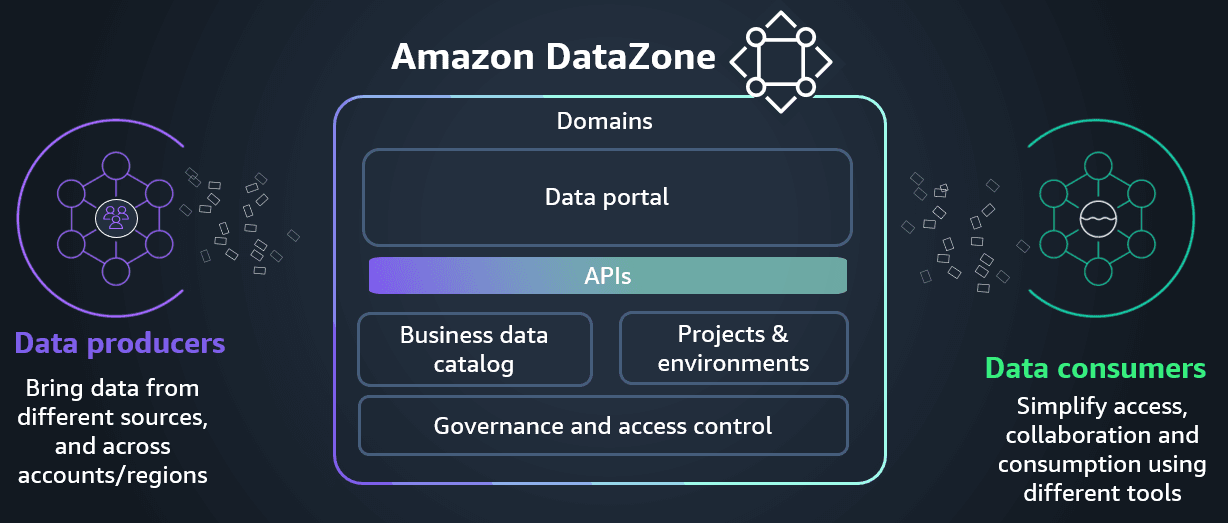
Source - AWS
Amazon Data Zone is a data management service that helps organizations catalog, discover, share, and govern their data at scale. Built specifically for the complexities of modern data environments, it serves as a unified platform where technical and business users can collaborate effectively around data.
At its core, Amazon Data Zone provides:
- Data Catalog and Discovery: A searchable inventory of all data assets across the organization
- Self-service Data Access: Streamlined processes for requesting and granting data access
- Automated Governance: Built-in controls for ensuring compliance with policies and regulations
- Data Sharing Capabilities: Simplified mechanisms for sharing data across teams and organizations
- Integration with AWS Services: Seamless connection with Amazon S3, Amazon Redshift, AWS Glue, and other AWS data services
How Does It Stand Apart?
Unlike traditional data catalogs or governance tools, Amazon Data Zone takes a business-centric approach. It recognizes that effective data management isn't just a technical challenge—it's an organizational one that requires bringing together data producers, consumers, and stewards in a collaborative environment.
While other solutions might focus exclusively on technical metadata or governance policies, Amazon Data Zone bridges the gap between business context and technical implementation, making data assets meaningful and accessible to all stakeholders.
| Dimension | Traditional Solutions | Amazon DataZone |
| User Focus | Primarily built for IT and technical users | Designed for both technical and business users |
| Data Discovery | Relies heavily on technical metadata; limited searchability | Business-context-rich discovery with intuitive search |
| Collaboration | Siloed workflows between data owners and consumers | Collaborative workspaces connecting producers, consumers, and stewards |
| Governance Approach | Policy-heavy, manual rule enforcement | Embedded, automated governance with role-based access |
| Integration | Often requires custom integration with other tools and systems | Seamlessly integrates with AWS ecosystem and supports hybrid environments |
| Data Lineage and Transparency | Limited lineage visibility, often unavailable to business users | End-to-end lineage with auditability and transparency for all stakeholders |
| Scalability and Automation | Manual scaling, static policies, and limited automation | Automated workflows, scalable architecture, AI-assisted metadata enhancement |
| Business Enablement | Focus on control, often at the expense of usability | Enables self-service access while maintaining compliance and control |
Key Features
Amazon Data Zone provides a comprehensive set of features designed to address the complex challenges of modern data management. Each capability works in concert to create a unified data experience that balances accessibility with governance.
Unified Data Discovery and Access
Amazon DataZone eliminates the guesswork involved in finding data. Regardless of technical background, users can search, browse, and request access to data across departments from a single workspace. Metadata, business definitions, and usage indicators are surfaced automatically, helping users understand data's relevance and quality before using it.
It also uses AI-powered metadata enrichment, automatically tagging and contextualizing datasets using natural language processing and pattern recognition. This significantly reduces the manual overhead of data cataloging and improves discoverability at scale.
Imagine a marketing analyst trying to understand customer behavior. Instead of chasing down data owners or sifting through spreadsheets, they simply search for "purchase history" and discover a vetted dataset—complete with metadata, ownership details, usage policies, and trust indicators. This turns a multi-day process into a few clicks, speeding up decision-making and encouraging self-service exploration.
Embedded Governance and Policy Enforcement
Governance is not a separate layer in Amazon DataZone—it’s built into every data interaction. The platform makes it easy to set up policies that automatically control access, ensure compliance, and keep a detailed record of how data is being used.
What this looks like in practice:
- Access is granted based on roles, approvals, and declared usage purpose, not just blanket permissions.
- Policies can be created once and applied consistently across datasets.
- Administrators and data stewards have a real-time view of who is using what data, for what purpose, and under which rules.
The addition of approval workflows ensures access requests are reviewed and justified, adding a layer of accountability, especially useful in regulated environments. Amazon DataZone also supports cross-account data sharing, allowing organizations to safely collaborate across teams, departments, or even external partners without compromising on control.
As data access expands across teams, so does the risk. Amazon DataZone helps organizations stay secure and compliant without creating bottlenecks. Business teams can move fast, while IT and compliance teams retain visibility and control.
Business-Centric Structure and Collaborative Projects
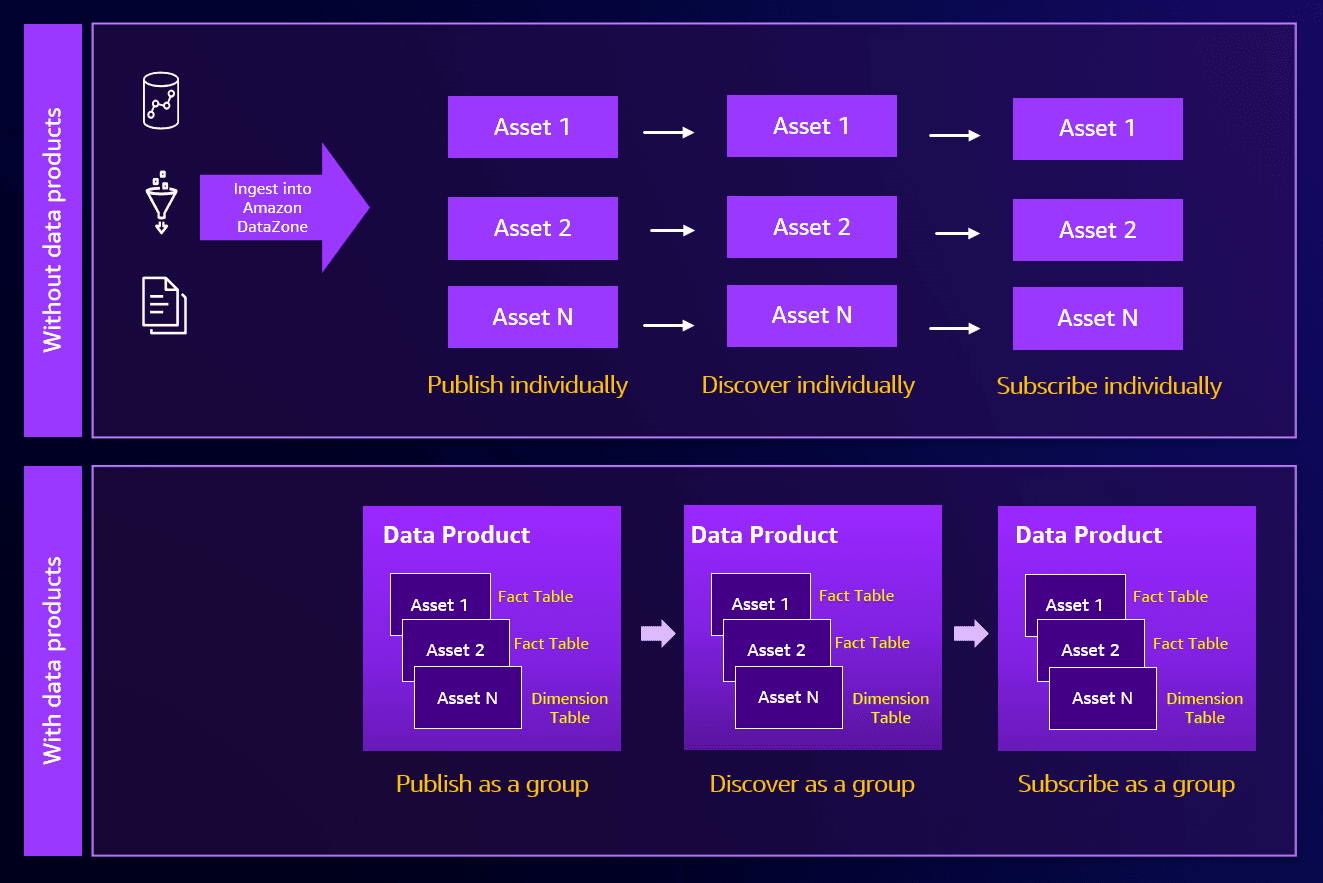
Source - AWS
What sets Amazon DataZone apart from traditional catalogs is its alignment with how businesses operate, not how databases are structured.
- Domain-based data cataloging lets organizations organize and govern data by business units such as Finance, Marketing, or Supply Chain.
- Project workspaces serve as collaborative environments where users can request, access, and analyze data in a governed way. These workspaces can include datasets, user roles, approval workflows, and contextual metadata, scoped specifically to a use case or initiative.
This structure promotes ownership and accountability, allowing data stewards to maintain oversight while empowering teams to move quickly within defined boundaries.
Automated Tracking of Data and Audits
One of the most overlooked—but essential—elements of data trust is knowing where data comes from and how it has changed. Amazon Data Zone provides built-in data lineage tracking that shows a complete chain, from source to transformation to consumption.
Whether it’s for compliance, troubleshooting, or building confidence in data, knowing how a dataset was created—and what touched it along the way—is critical. Teams can validate assumptions, trace back errors, or confirm regulatory requirements with minimal effort. This visibility also helps prevent downstream surprises when upstream data changes.
Audit logs are automatically maintained and centrally viewable, simplifying governance reporting and enabling quicker responses during audits or investigations.
Seamless AWS Integration
Amazon Data Zone is purpose-built to fit into the broader AWS environment, reducing the complexity of implementation and operations.
It connects directly with:
- Amazon S3 for structured and unstructured data storage
- Amazon Redshift for data warehousing
- AWS Lake Formation for data lake governance
- AWS Glue for metadata and data movement
- Amazon QuickSight for dashboards and visual analytics
These integrations enable teams to fully leverage AWS services without needing to combine third-party tools or create custom pipelines. For organizations with multi-account setups or federated data environments, Amazon DataZone supports governed cross-account sharing, helping unify analytics while respecting ownership boundaries.. Teams can move faster, reduce integration overhead, and start seeing value in weeks, not months.
Amazon DataZone Pricing & ROI Considerations
Amazon DataZone operates on a pay-as-you-go model, making it easier for organizations to start small and scale over time. There are no long-term commitments or upfront license fees—just billing based on actual usage.
Here’s a high-level view of the primary cost dimensions:
- Data Requests: Charges are based on API usage for actions like requesting or sharing data. Most core operations have generous free usage tiers.
- Metadata Storage: Fees apply only when storing large volumes of metadata—most small to medium deployments stay within the free limits initially.
- Compute Resources: Costs apply when performing automated metadata ingestion or using AI-driven features.
- AI-Powered Metadata Enhancements: Features like intelligent name generation and tagging are priced based on how much data is processed.
| Pricing Component | Rate | Included Free Usage | Notes |
| Requests | $10 per 100,000 requests | 4,000 requests per account per month | Core APIs like CreateDomain, CreateProject, and Search are free and do not count towards the 4,000 free requests. |
| Metadata Storage | $0.40 per GB per month | 20 MB per account per month | Charges apply only when storage exceeds the free tier. |
| Compute Units | $1.776 per compute unit | 0.2 compute units per account per month | Used for metadata ingestion and AI-based name generation. |
| AI Recommendations | Input: $0.015 per 1,000 tokens <br> Output: $0.075 per 1,000 tokens | None | Charges are based on the number of tokens processed during AI-driven metadata enhancements. |
Note: As of November 1, 2024, Amazon DataZone has removed the monthly user-based subscription fee, making the service more accessible and cost-effective for customers.
Looking Beyond Cost: Where ROI Comes From
Many organizations mistakenly view governance platforms as overhead. Amazon DataZone challenges that mindset by delivering clear, measurable value in four key areas:
- Faster Time to Insight
By making it easier to find and trust the right data, teams spend less time searching and validating and more time analyzing and acting. In many cases, organizations report a 30–50% reduction in time spent locating data assets.
- Reduced Redundancy and Rework
When everyone works from a shared catalog with rich metadata, the same datasets aren’t recreated or re-analyzed in silos. This helps avoid duplicated reports, manual reconciliation, and repeated queries to IT teams.
- Lower Risk and Better Compliance
DataZone’s built-in access controls and audit trails reduce the risk of accidental misuse and support better compliance with regulations like GDPR, HIPAA, and CCPA. That’s not just safer—it’s cost avoidance in the form of fewer breaches, audits, or fines.
- Improved Productivity Across Roles
From data engineers to business analysts, users get a consistent interface and reliable access to what they need. That consistency leads to more self-service, fewer dependencies, and faster project cycles.
Calculating ROI: What to Measure
Before implementing Amazon DataZone, it helps to benchmark current processes—such as how long it takes to find and validate data or how often teams duplicate work. After implementation, these metrics become your baseline for ROI measurement.
What to track:
- Time-to-insight for key reports and analytics
- Number of duplicate data requests or reports
- Percentage of data assets reused across projects
- Number of compliance audits passed with less manual effort
Measurement Approach
- Establish baseline metrics before implementation
- Track key performance indicators like time-to-insight and data request fulfillment times
- Calculate cost avoidance from improved governance and reduced duplicative work
- Measure increased value from data-driven decisions enabled by better data access
For a more detailed understanding and to explore specific use cases, visit the Amazon DataZone Pricing Page.
How Amazon Data Zone Streamlines Data Management?
Simplified Integration with Existing Data Sources
Getting started with Amazon Data Zone doesn’t mean moving your data or overhauling your systems. It connects to your existing data sources—like cloud storage, databases, and data lakes. It automatically scans and catalogs metadata, tagging assets with relevant classifications and business context. This minimizes operational disruption while enabling faster time-to-value.
- For technical teams: Reduces the need for building custom data connectors or manual data ingestion scripts.
- For business users: Discover and access relevant data faster, without waiting on IT or learning complex tools.
User-Friendly Data Access
Forget long email chains, confusing approvals, or waiting weeks just to get access to data. Amazon Data Zone makes things smoother with:
- Self-service portals allow users to discover and request data using familiar business terms.
- Automated approval workflows enforce data access policies based on roles, departments, and sensitivity levels.
- Immediate access provisioning once requests are approved—no need to wait for manual handoffs.
- Business context and metadata are presented, improving understanding and usability.
These enhancements shorten the time from data request to delivery from days or weeks to just minutes.
Automation and Scalability
As data volumes grow, manual processes become unsustainable. Amazon Data Zone addresses this challenge through automation:
- Automatic metadata extraction and cataloging
- Policy-based access control that scales across the organization
- Scheduled data quality checks and notifications
- Automated integration of new data sources
This automation ensures that governance practices remain consistent even as your data landscape expands.
Enabling a Data-Driven Culture Across the Organization
Modern enterprises don't just need better tools—they need a culture that values and uses data at every level. Amazon DataZone plays a foundational role in enabling this shift.
- From Gatekeeping to Empowerment
Amazon DataZone simplifies data access for business users while maintaining governance controls, enabling teams across marketing, finance, and operations to explore, understand, and use data with confidence. - Building Trust in Data
Clear data lineage, business glossaries, and quality indicators help remove ambiguity. Users spend less time questioning data and more time applying it. - Fostering Responsible Data Use
With role-based access and automated compliance checks, the platform encourages responsible behavior without stifling innovation. - Aligning Business and Technical Stakeholders
By bridging the gap between IT and business teams, Amazon DataZone creates a shared workspace where data producers and consumers operate with clarity and collaboration.
This cultural shift—enabled by thoughtful architecture and intuitive user experience—can be more transformative than any single feature. It’s what turns a data management tool into a catalyst for enterprise-wide agility and innovation.
Real-World Impact: Amazon Data Zone in Action
Retail: Unifying Customer Data to Drive Personalization
A global retailer faced challenges integrating fragmented data from point-of-sale systems, mobile apps, and marketing platforms. Amazon DataZone helped them establish a governed data catalog accessible across departments.
Key Outcomes:
- Marketing teams used metadata tagging and trust signals to discover and use customer segments more accurately
- Reduced campaign planning cycles by 30% due to faster data discovery
- Improved campaign conversion rates by 15% through more targeted outreach
Healthcare: Balancing Data Accessibility and Compliance
A national healthcare network needed to support research and analytics across departments without violating patient privacy. By deploying Amazon DataZone, they created controlled access zones for clinical data, layered with automatic data anonymization and audit logging.
Key Outcomes:
- Research teams accessed approved datasets 50% faster with self-service tools
- Compliance officers used automated audit trails to validate HIPAA adherence in real-time
- Reduced manual approval workflows by 70%, accelerating clinical trials
Financial Services: Enabling Trust in Analytics and Reporting
A leading bank struggled with inconsistent data definitions across trading, risk, and compliance teams. Amazon DataZone enabled them to create a shared business glossary and domain-based access policies.
Key Outcomes:
- Report generation times were reduced from 3 days to 4 hours due to centralized, validated datasets
- Reduced risk of regulatory non-compliance by enforcing consistent data usage policies
- Enhanced collaboration between compliance, data engineering, and analytics teams
AI & Machine Learning: Improving Model Reliability and Speed
A SaaS company building predictive models needed a better way to discover and govern training datasets. With Amazon DataZone, they cataloged their internal data assets with lineage information, data quality scores, and usage metadata.
Key Outcomes:
- Data scientists reduced dataset discovery time by 60%
- Model performance improved due to better understanding of data quality and version history
- Reduced rework by eliminating use of outdated or unapproved training data
Fitting Amazon DataZone into Your Existing Data Stack
For most enterprises, data doesn't live in a single cloud or platform—it’s scattered across hybrid environments, legacy systems, and a mix of SaaS applications. Amazon DataZone is designed with this reality in mind. While its native AWS integrations are powerful, its real strength lies in how flexibly it connects with the tools and platforms you already rely on.
Beyond the AWS Ecosystem: Adapting to Hybrid and Multicloud Environments
Amazon DataZone goes beyond AWS-native data services to support the diverse systems modern organizations use:
- Cloud Storage Providers: Connects with Azure Blob Storage, Google Cloud Storage, and other public cloud environments, ensuring data silos don’t form just because of cloud boundaries.
- On-Premises Systems: Offers secure connections to data housed in traditional data centers, enabling metadata management and governance without requiring full cloud migration.
- SaaS Platforms: Works with platforms like Salesforce, Workday, and ServiceNow, allowing teams to govern and reuse SaaS-derived data alongside structured data sources.
Organizations no longer need to centralize all data physically to manage it effectively. DataZone allows you to centralize visibility and control without centralizing storage.
Compatibility with Analytics and Data Science Workflows
Amazon DataZone supports the tools your analysts, scientists, and decision-makers already use:
- Business Intelligence Tools: Whether your teams use Tableau, Power BI, or Looker, DataZone helps surface-governed, trusted data be directly incorporated into those tools, speeding up insight generation while maintaining control.
- Notebooks and SQL Tools: Data scientists and engineers can access curated datasets from Jupyter, RStudio, DBeaver, and other SQL clients, without requesting extracts from IT.
Rather than forcing users to learn a new analytics stack, DataZone works with your current one—reducing friction and encouraging faster adoption.
Built for Extension: Adapting to Unique Organizational Needs
Every organization has specific needs. Amazon DataZone provides multiple ways to extend its capabilities:
- Robust APIs: Enable teams to build custom workflows, integrations, or automations based on metadata events.
- Webhooks and Triggers: Link DataZone actions to other enterprise systems—automatically notify security, kick off pipeline jobs, or update dashboards.
- Custom Metadata: Add organization-specific tags, classifications, or business rules to reflect your unique operating context.
You’re not limited to out-of-the-box governance. Amazon DataZone lets you shape your metadata and governance layer around how your business actually works.
Getting Started with Amazon Data Zone
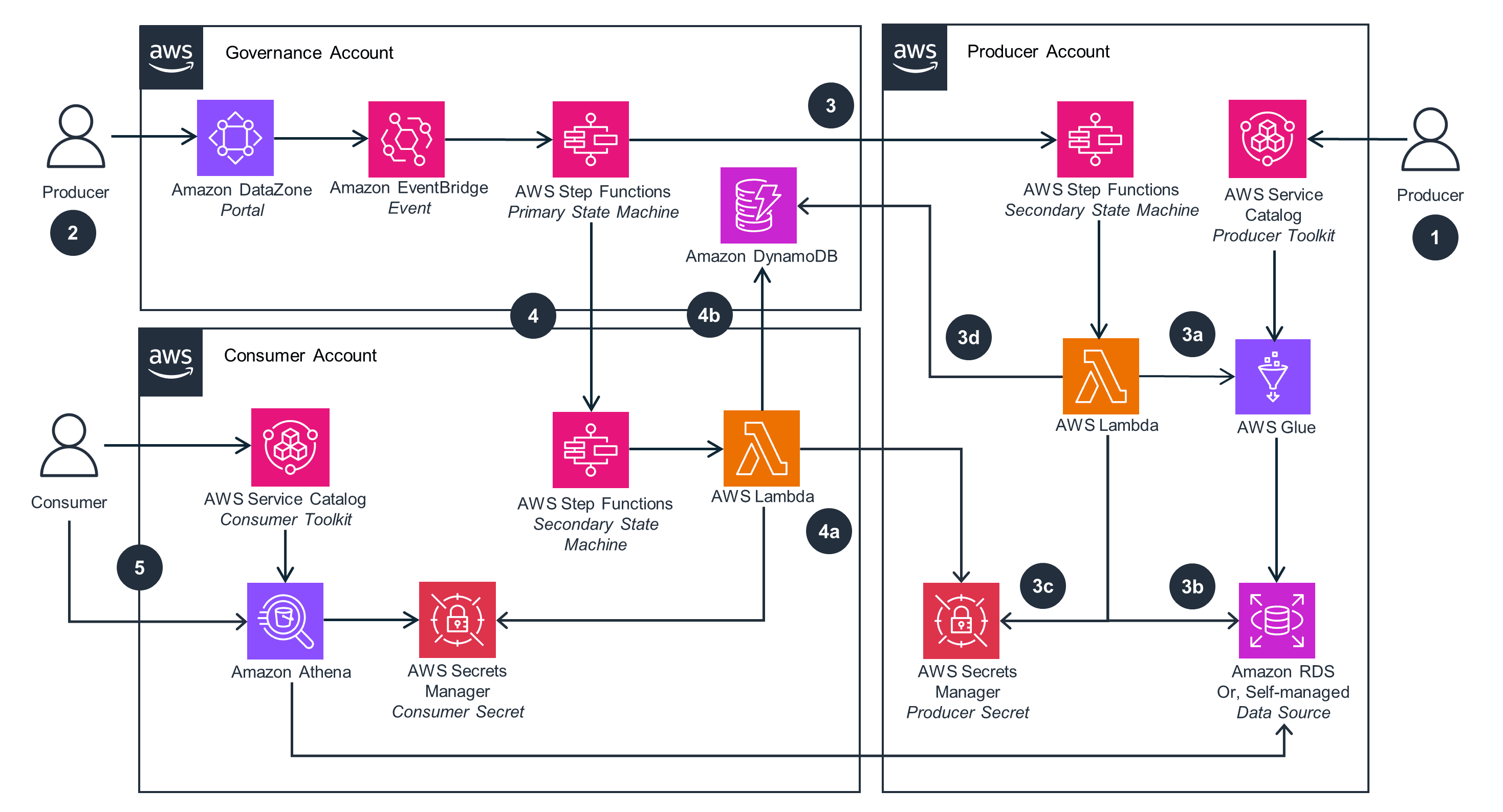
Source - AWS
Prerequisites for Implementation
Before diving into implementation, set yourself up for success with a few key preparations:
- Identify your core team—include both business leaders and technical stakeholders
- Take inventory of your current data sources and governance requirements
- Define your initial data domains and assign ownership
- Review existing access control and compliance policies
These steps ensure your setup aligns with your organization’s goals
Step-by-Step Implementation Guide
- Set Up Your Amazon Data Zone Environment
- Create your first Amazon Data Zone domain
- Set up authentication and user roles
- Define initial projects and business units to match your organization’s structure
- Connect Data Sources
- Integrate with your data repositories—Amazon S3, Redshift, and others
- Enable automatic metadata extraction
- Apply classification rules to tag sensitive or regulated data
- Establish Governance
- Define data domains and assign clear ownership
- Set up access policies and approval workflows
- Configure security, compliance, and audit settings
- Empower Your Users
- Train business users to search, request, and work with data
- Guide data owners on how to publish and share assets
- Collect feedback to continuously improve usability and adoption
Best Practices for a Smooth Rollout
- Start small: Begin with a few well-known, high-impact data domains
- Think cross-functional: Involve business and technical teams from day one
- Go step-by-step: Use a phased rollout instead of trying to do everything at once
- Invest in adoption: Provide training, support, and clear communication
- Iterate often: Review usage patterns and adjust policies as needed
Maximizing Value with Amazon Data Zone
Unlocking the full potential of Amazon Data Zone isn’t just about setup—it’s about smart practices that drive better data usage, governance, and performance across your organization.
Optimize Your Data Structure for Discovery and Trust
A well-organized data environment makes it easier for users to find, understand, and trust the data they access. Here's how to get there:
- Use consistent naming conventions for datasets, fields, and domains—avoid cryptic or system-specific labels
- Add rich metadata, including business definitions, data quality indicators, data lineage, and usage notes
- Assign clear ownership for each dataset and domain to establish accountability
- Document business logic and rules alongside technical metadata—so everyone understands how the data is used
- Group assets into logical domains and categories to simplify navigation for end users
- Tag data assets with sensitivity levels (e.g., PII, financial, internal) to support compliance and access control
Tip: Regular metadata reviews help keep the catalog clean, current, and trustworthy.
Strengthen Security and Compliance Without Slowing Down
Amazon Data Zone offers built-in tools to help you keep data secure and compliant—use them to create a strong, scalable governance framework:
- Enforce least-privilege access—only give users the access they need, and nothing more
- Use automated, policy-driven access controls that adapt to changes in user roles or data sensitivity
- Monitor access logs and request patterns to identify unusual behavior or risk areas
- Set up automated alerts for policy violations, access to sensitive data, or data sharing outside allowed boundaries
- Document data handling procedures for PII, regulated data, or cross-border sharing to stay audit-ready
Security and compliance are continuous practices—automate what you can, and review regularly.
Tune Performance for Scale and Speed
As data volumes grow, staying fast and responsive becomes critical. Here’s how to keep Amazon Data Zone running efficiently:
- Schedule metadata extraction based on how often your data changes—real-time for active sources, periodic for static ones
- Use caching wisely to speed up access to high-demand datasets and reduce load
- Monitor usage trends to right-size resources, identify underutilized data, and eliminate bottlenecks
- Establish archiving and retention policies to move outdated or unused assets out of the active catalog
- Leverage automation to detect slow processes, stale metadata, or broken links between assets
The more you optimize behind the scenes, the smoother the experience is for your users.
Limitations and Strategic Considerations Before Adoption
While Amazon Data Zone introduces a compelling approach to modern data governance and discovery, it’s not a one-size-fits-all solution. For organizations exploring adoption, it's important to evaluate not only the platform's capabilities but also the context and conditions under which it can succeed. The following considerations are not drawbacks per se, but strategic realities that shape how the platform delivers value.
1. Implementation Complexity and Setup Investment
Amazon Data Zone is not a plug-and-play tool; it is a foundational platform that requires thoughtful configuration.
- Initial Setup Demands Structure
Organizations must define domains, curate metadata, and establish governance policies early. Without a clear framework, implementation can stall. This front-loaded effort often reveals gaps in existing data processes, especially in decentralized environments. - AWS Familiarity Accelerates Success
Teams without prior AWS experience may find the service ecosystem—IAM, Lake Formation, Glue, and more—overwhelming at first. This isn’t a blocker, but it does affect timelines. Organizations should account for training or consider managed onboarding support to navigate the ecosystem effectively. - Change Management is Non-Negotiable
Because Amazon Data Zone alters how teams access and govern data, internal alignment is critical. This includes both cultural readiness and executive support. A rollout without change management risks low adoption, shadow data workarounds, or governance bypasses.
2. Technical and Integration Considerations
The technical foundation of Amazon Data Zone is robust, but there are certain boundaries to be aware of—particularly when operating at scale or across diverse ecosystems.
- Scaling for Volume and Variety
While Amazon Data Zone is designed for enterprise workloads, organizations dealing with extremely high-frequency or high-volume datasets (e.g., IoT, clickstream data) may need to optimize their data pipelines and metadata management strategies to maintain performance and discoverability. - Depth of Integration Outside AWS
Native integration is a clear strength within AWS, but organizations relying heavily on non-AWS storage, analytics, or identity systems should carefully evaluate current support for connectors, metadata ingestion, and access control synchronization. These integrations are improving but may require additional engineering overhead today. - Customization for Niche Governance Needs
Amazon Data Zone provides a strong governance framework, but industries with regulatory nuances (e.g., pharma, defense) or domain-specific taxonomies may need to extend or adapt certain features through custom development, third-party tooling, or policy layering.
3. Organizational Readiness and Governance Maturity
Amazon Data Zone works best in organizations that are already moving toward data-centric operations—but it can expose structural weaknesses if those foundations are missing.
- Governance Maturity Shapes ROI
If your organization lacks clear data ownership, data stewardship roles, or documented governance practices, Amazon Data Zone will not fill that gap on its own. In such cases, the platform may initially highlight the need for foundational governance work. - Data Quality is a Bottleneck or a Catalyst
The platform amplifies value from trusted, well-documented data. But if datasets are inconsistent, poorly tagged, or lacking in lineage, the discovery and approval workflows can feel like window dressing over weak content. Addressing data quality is not optional—it is fundamental to success. - Ongoing Stewardship Requires Resources
Amazon Data Zone is not set-and-forget. It demands continuous curation of metadata, monitoring of access requests, and refinement of policies. Assigning clear ownership and dedicating operational capacity is necessary to sustain long-term impact.
4. Cost Dynamics and ROI Considerations
As with many enterprise-grade platforms, cost is a function of scale, usage, and operational complexity.
- Data Volume Directly Influences Costs
Storage and cataloging of large data lakes and data warehouses increases costs—not just in storage, but in metadata management, access policies, and processing. It’s crucial to prioritize high-value domains first and assess usage before scaling horizontally. - API and Workflow Automation May Add Overhead
Organizations with programmatic access models (e.g., automated policy enforcement, frequent API interactions) should model usage patterns carefully. API-heavy workloads may lead to unexpected operational costs, particularly at scale. - Evaluate Value Across Teams, Not Just IT
Amazon Data Zone’s ROI grows when its benefits are felt across business, analytics, compliance, and IT functions. A successful adoption should factor in not just licensing and infrastructure costs, but also reduced manual effort, improved data discovery time, fewer compliance risks, and increased productivity from governed self-service.
Making Amazon DataZone Work for Your Organization
As data continues to grow in volume, complexity, and importance, the ability to manage it effectively is no longer optional—it’s a strategic necessity. Amazon DataZone offers a powerful yet practical foundation for achieving this.
Whether you're just beginning your data governance journey or looking to unify fragmented systems, success with Amazon DataZone depends on a few key practices:
- Start with High-Impact Domains
Identify business areas where data friction is highest—like marketing attribution or financial forecasting—and deploy Amazon DataZone there first to demonstrate value quickly. - Build Cross-Functional Ownership
Engage both technical and business stakeholders early. Success depends not only on implementation but also on adoption across teams. - Invest in Metadata and Governance Foundations
The platform’s benefits scale with the quality of metadata and governance processes. A strong foundation here ensures long-term value. - Measure and Communicate Value
Track metrics like time-to-insight, request fulfillment, and data reuse. Use them to build momentum and secure ongoing support.
Amazon DataZone is not just a tool—it’s a platform for driving cultural and operational change. By anchoring your rollout in real business priorities and promoting responsible access, you turn a technical deployment into a competitive advantage.






